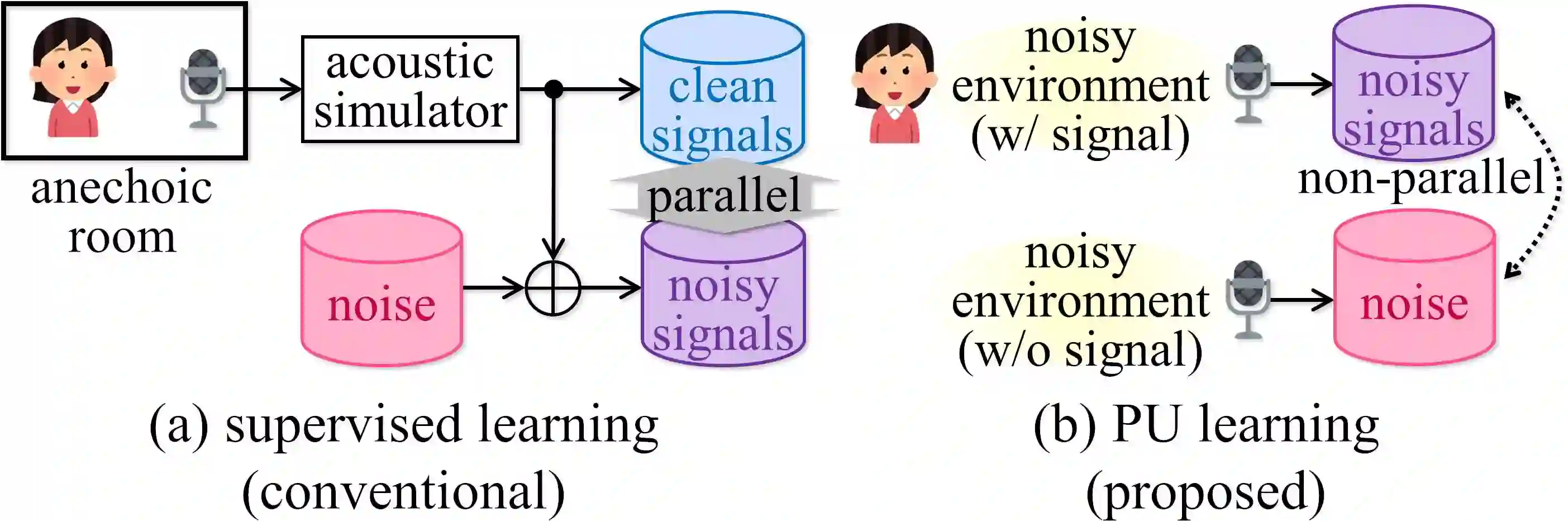
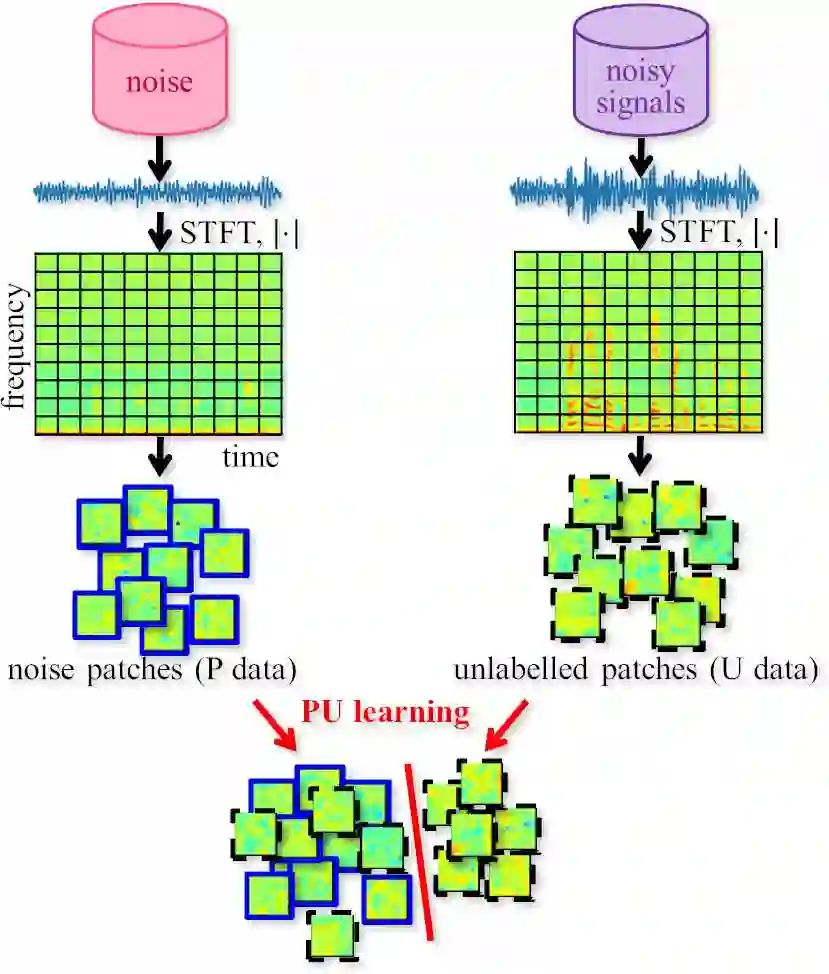
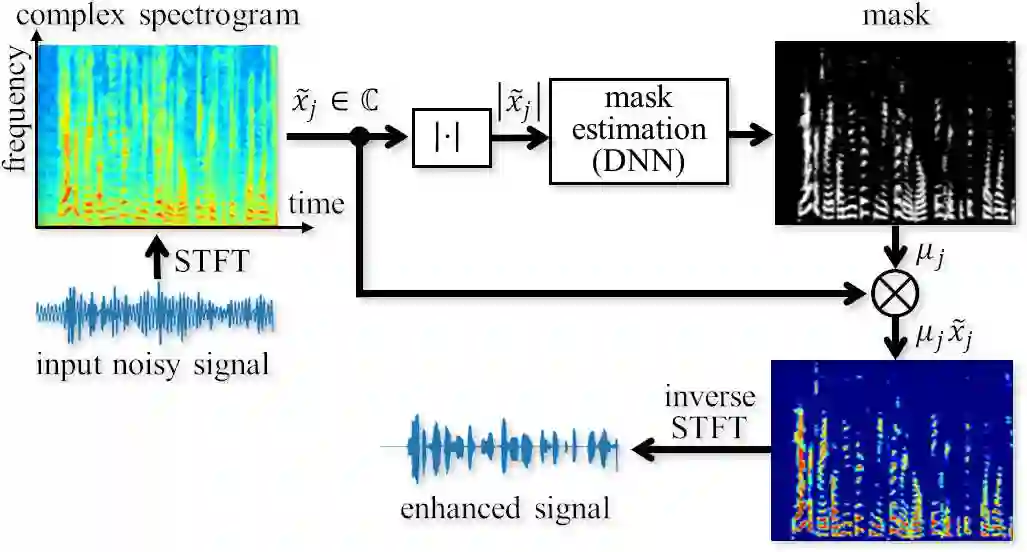
Supervised learning is a mainstream approach to audio signal enhancement (SE) and requires parallel training data consisting of both noisy signals and the corresponding clean signals. Such data can only be synthesised and are thus mismatched with real data, which can result in poor performance. Moreover, it is often difficult/impossible to obtain clean signals, making it difficult/impossible to apply the approach in this case. Here we explore SE using non-parallel training data consisting of noisy signals and noise, which can be easily recorded. We define the positive (P) and the negative (N) classes as signal absence and presence, respectively. We observe that the spectrogram patches of noise clips can be used as P data and those of noisy signal clips as unlabelled data. Thus, learning from positive and unlabelled data enables a convolutional neural network to learn to classify each spectrogram patch as P or N for SE.
翻译:受监督的学习是增强音频信号的一种主流方法,需要由噪音信号和相应的清洁信号组成的平行培训数据。这些数据只能合成,因而与真实数据不匹配,这可能导致性能不佳。此外,获得清洁信号往往很难/不可能,使得在这种情况下很难/不可能应用这一方法。在这里,我们使用由噪音信号和噪音组成的非平行培训数据进行探索。我们把正(P)和负(N)级分别定义为信号缺失和存在。我们观察到,噪音剪片的光谱部分可以用作P数据,而噪音片的振动信号片则用作无标签数据。因此,从正和无标签的数据中学习,使得一个脉动神经网络能够学习将每个光谱片段分类为P或N。