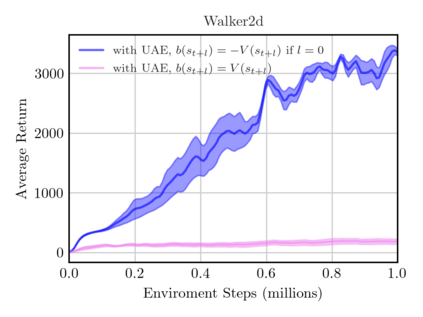
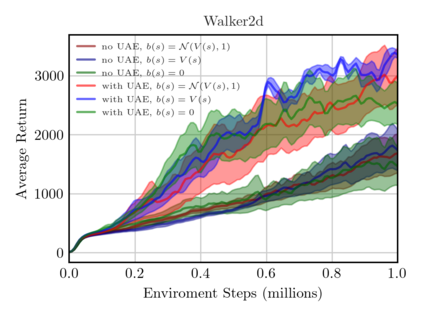
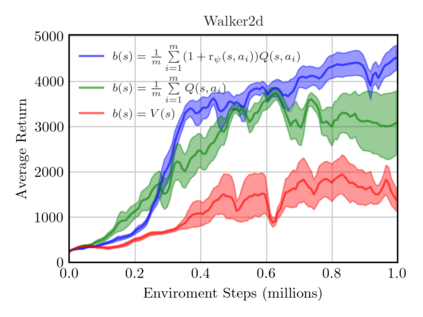
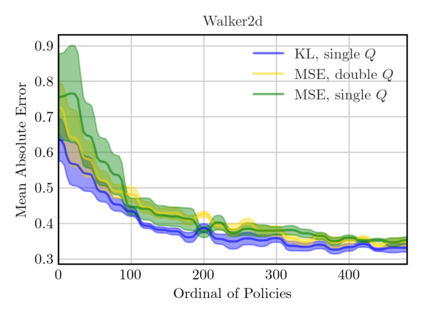
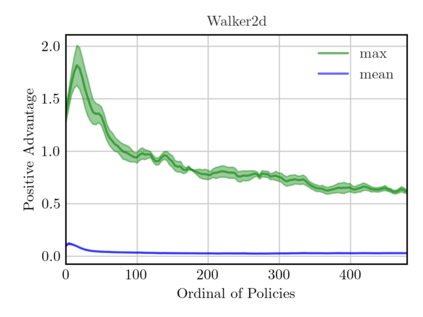
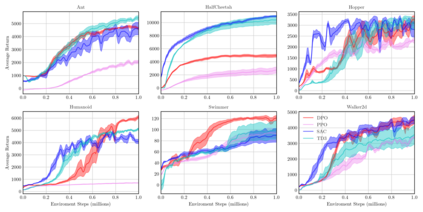
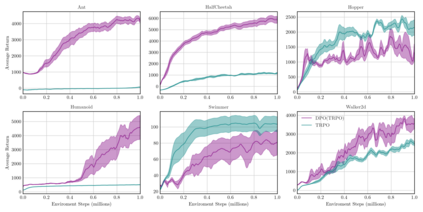
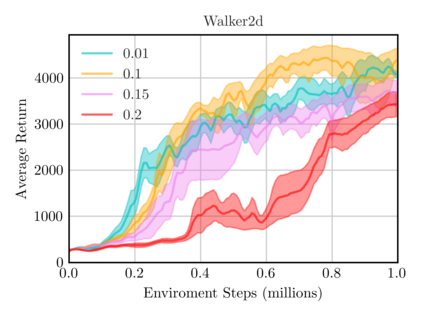
On-policy algorithms are supposed to be stable, however, sample-intensive yet. Off-policy algorithms utilizing past experiences are deemed to be sample-efficient, nevertheless, unstable in general. Can we design an algorithm that can employ the off-policy data, while exploit the stable learning by sailing along the course of the on-policy walkway? In this paper, we present an actor-critic learning framework that borrows the distributional perspective of interest to evaluate, and cross-breeds two sources of the data for policy improvement, which enables fast learning and can be applied to a wide class of algorithms. In its backbone, the variance reduction mechanisms, such as unified advantage estimator (UAE), that extends generalized advantage estimator (GAE) to be applicable on any state-dependent baseline, and a learned baseline, that is competent to stabilize the policy gradient, are firstly put forward to not merely be a bridge to the action-value function but also distill the advantageous learning signal. Lastly, it is empirically shown that our method improves sample efficiency and interpolates different levels well. Being of an organic whole, its mixture places more inspiration to the algorithm design.
翻译:但是,政策上的算法应该是稳定的,抽样密集的。 利用过去经验的非政策算法被认为具有抽样效率,但总的来说是不稳定的。 我们能否设计出一种算法,可以使用非政策性数据,同时利用在政策上行走的航道上的稳定学习? 在本文中,我们提出了一个行为者- 批评学习框架,它借用了利益分配的观点来进行评估,并交叉生成了两种改进政策的数据来源,这可以快速学习,并可以应用于广泛的类别的算法。在其主干线中,差异减少机制,例如统一优势估计器(UAE),它扩大了普遍优势估计器(GAE),可以适用于任何依赖于国家的基线,以及一个能够稳定政策梯度的学习基线。 我们首先提出,它不仅仅是一个与行动价值功能的桥梁,而且还可以淡化有利的学习信号。 最后,它从经验上表明,我们的方法改进了抽样效率和不同层次的内插法。 它是一个有机整体的混合物激励点,它更有利于设计。