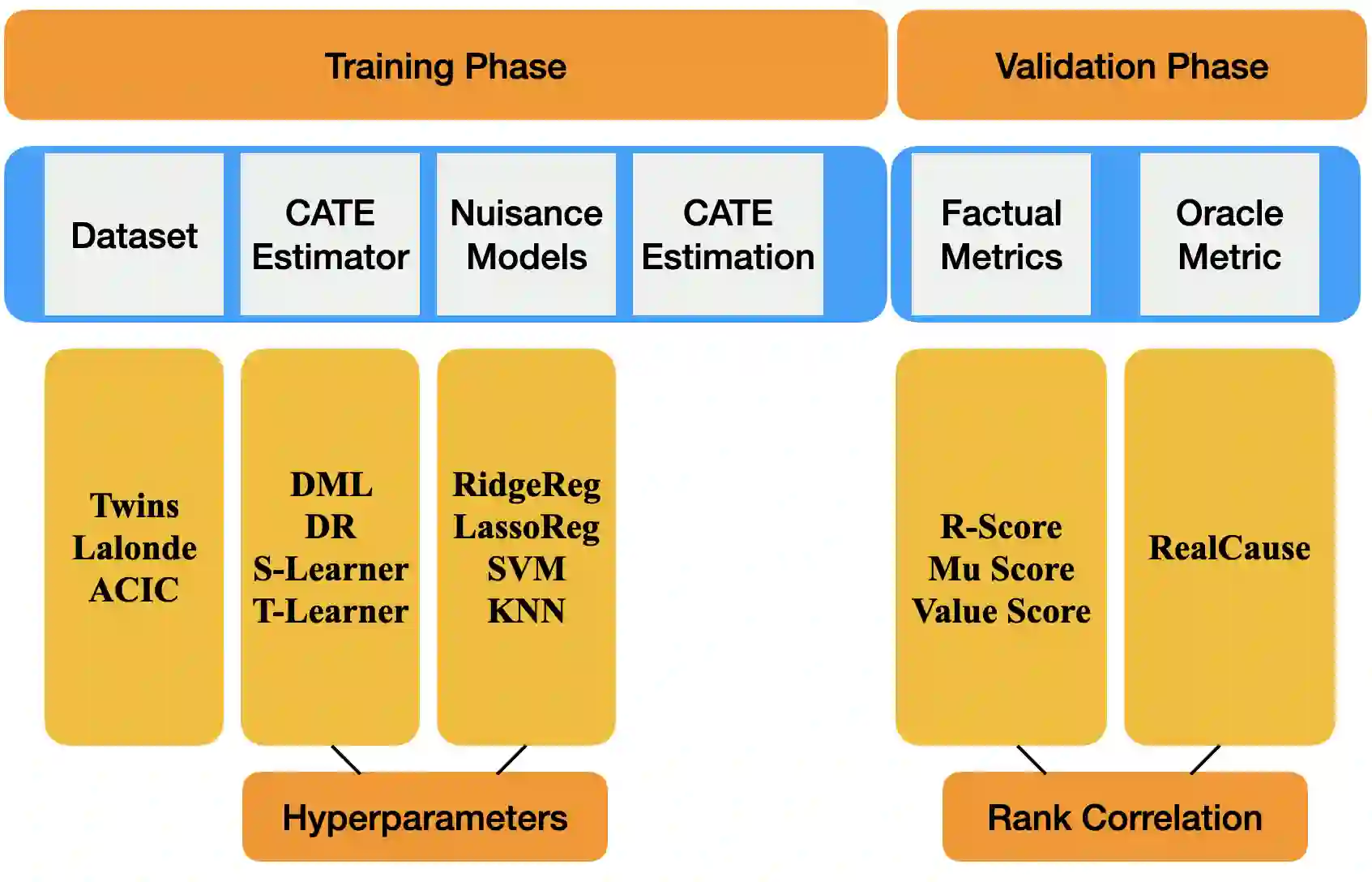
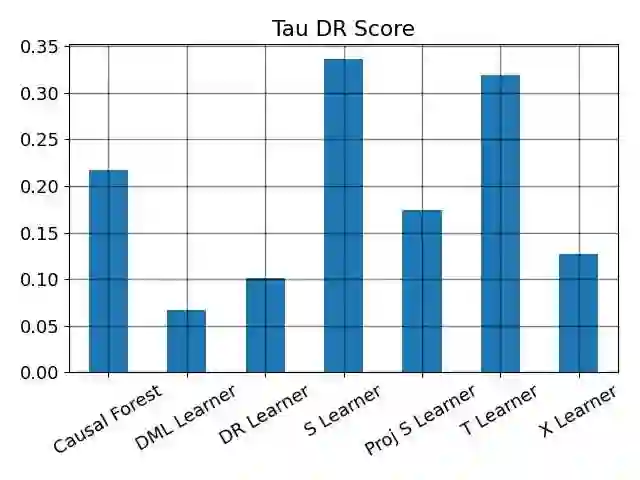
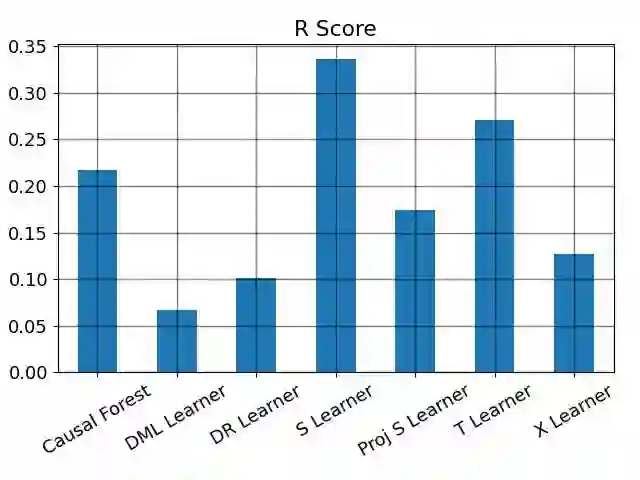
We study the problem of model selection in causal inference, specifically for the case of conditional average treatment effect (CATE) estimation under binary treatments. Unlike model selection in machine learning, we cannot use the technique of cross-validation here as we do not observe the counterfactual potential outcome for any data point. Hence, we need to design model selection techniques that do not explicitly rely on counterfactual data. As an alternative to cross-validation, there have been a variety of proxy metrics proposed in the literature, that depend on auxiliary nuisance models also estimated from the data (propensity score model, outcome regression model). However, the effectiveness of these metrics has only been studied on synthetic datasets as we can observe the counterfactual data for them. We conduct an extensive empirical analysis to judge the performance of these metrics, where we utilize the latest advances in generative modeling to incorporate multiple realistic datasets. We evaluate 9 metrics on 144 datasets for selecting between 415 estimators per dataset, including datasets that closely mimic real-world datasets. Further, we use the latest techniques from AutoML to ensure consistent hyperparameter selection for nuisance models for a fair comparison across metrics.
翻译:我们研究因果推断中的模型选择问题,具体针对在二进制处理中进行有条件平均治疗效果(CATE)估计的情况。与机器学习中的模型选择不同,我们在这里不能使用交叉校验技术,因为我们没有观察到任何数据点的反事实潜在结果。因此,我们需要设计不明显依赖反事实数据的模型选择技术。作为交叉校验的替代办法,我们用文献中建议的各种代用指标来研究,这取决于从数据中估计的辅助性骚扰模型(对称分评分模型、结果回归模型)。然而,这些指标的有效性仅研究在合成数据集上,因为我们可以观察反事实数据。我们进行了广泛的实证分析,以判断这些指标的性能,我们利用基因化模型的最新进展来纳入多种现实的数据集。我们评估了144个数据集的9项指标,用于选择415个估量器,包括近似真实世界数据集。此外,我们使用最新的标准来进行自自动模模的比较,以确保从自动模量模型到自自动模准的一致的比标。