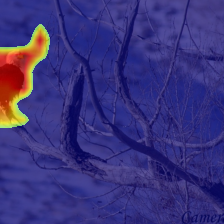
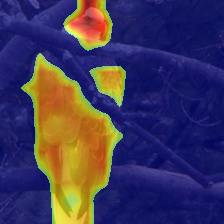
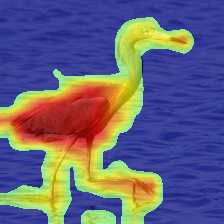
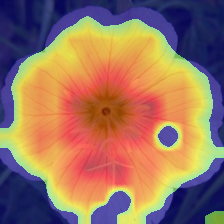
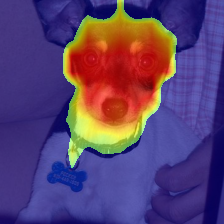
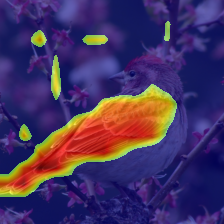
We present Generative Interpretable Fine-Tuning (GIFT) for parameter-efficient fine-tuning of pretrained Transformer backbones, which can be formulated as a simple factorized matrix multiplication in the parameter space or equivalently in the activation space, and thus embraces built-in interpretability. For a pretrained layer with weights $\omega\in \mathbb{R}^{d_{out}\times d_{in}}$, our proposed GIFT learns the fine-tuned weights $\hat{\omega}$ directly from $\omega$ as $\hat{\omega}=\omega \cdot (\mathbb{I}+\phi_{d_{in}\times r}\cdot \psi_{r\times d_{in}})$ where $\mathbb{I}$ is an identity matrix. $\Theta=(\phi, \psi)$ are the learnable parameters of the two linear layers of GIFT with $r$ being a hyper-parameter. $\Theta$ is shared by all the layers selected for fine-tuning, resulting in significantly fewer trainable parameters compared to Low-Rank Adaptation (LoRA). We perform comprehensive evaluations on natural language tasks (commonsense reasoning and sequence classification) and computer vision tasks (visual fine-grained classification). We obtain the best accuracy and parameter efficiency among baselines both on the Commonsense170k reasoning benchmark using LLaMA-1 (7B) and Llama-2 (7B)/-3 (8B) and on the FGVC and VTAB visual recognition benchmarks using ImageNet-21k pretrained Vision Transformer (ViT-B/16). Notably, we obtain 5.9% absolute increase in average accuracy with 53.8 times reduction of parameters on Commonsense170k using Llama-3 (8B) compared to LoRA. We obtain performance comparable to LoRA on the GLUE benchmark but with significantly fewer parameters using RoBERTa-Base/Large. We show the output of the first linear layer (i.e., $\omega\cdot \phi$) is surprisingly interpretable, which can play the role of a token-clustering head as a by-product to localize meaningful objects/parts in images for computer vision tasks. Our code is publicly available.
翻译:暂无翻译