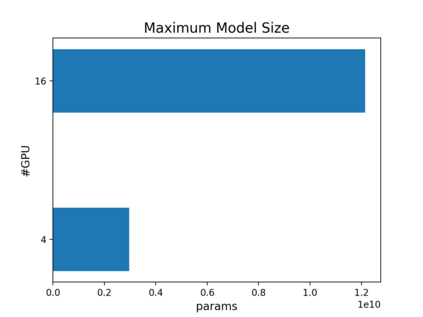
The Transformer architecture has improved the performance of deep learning models in domains such as Computer Vision and Natural Language Processing. Together with better performance come larger model sizes. This imposes challenges to the memory wall of the current accelerator hardware such as GPU. It is never ideal to train large models such as Vision Transformer, BERT, and GPT on a single GPU or a single machine. There is an urgent demand to train models in a distributed environment. However, distributed training, especially model parallelism, often requires domain expertise in computer systems and architecture. It remains a challenge for AI researchers to implement complex distributed training solutions for their models. In this paper, we introduce Colossal-AI, which is a unified parallel training system designed to seamlessly integrate different paradigms of parallelization techniques including data parallelism, pipeline parallelism, multiple tensor parallelism, and sequence parallelism. Colossal-AI aims to support the AI community to write distributed models in the same way as how they write models normally. This allows them to focus on developing the model architecture and separates the concerns of distributed training from the development process. The documentations can be found at https://www.colossalai.org and the source code can be found at https://github.com/hpcaitech/ColossalAI.
翻译:转型结构改善了计算机愿景和自然语言处理等领域深层次学习模式的绩效。 更好的绩效加上更大的模型规模。 这给当前加速器硬件如GPU的记忆墙带来了挑战。 在一个单一的GPU、 BERT 和 GPT 等大型模型上培训一个单一的GPU 或单一的机器是绝非理想的。 但是, 迫切需要在分布式环境中培训模型。 但是, 分布式培训, 特别是模型平行主义, 往往需要计算机系统和架构的域域专长。 AI研究人员要为其模型实施复杂的分布式培训解决方案,这仍然是一项挑战。 在本文中,我们引入了Colossal-AI, 这是一个统一的平行培训系统,旨在无缝地整合平行技术的不同模式,包括数据平行主义、管道平行主义、多重多发式平行主义和顺序平行主义。 Colossal-AI 旨在支持AI 社区以与通常写模型相同的方式编写分布式模型。 这使得他们能够专注于开发模型架构,并将分布式培训的关切问题与发展进程分开。 在 https://wwwcoglas/coglasstors。 在 http: httpscomologs.