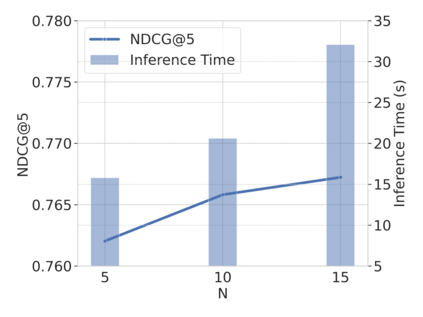
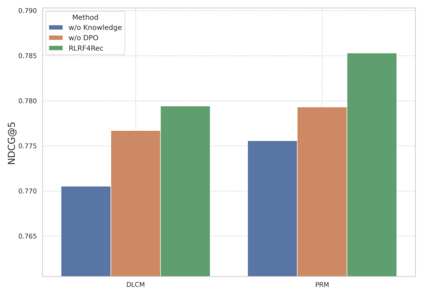
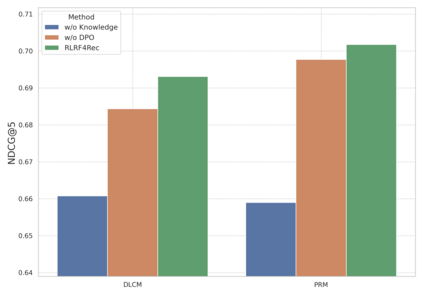
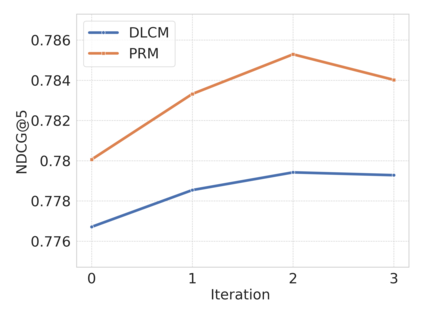
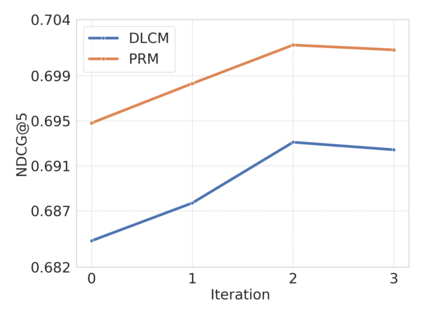
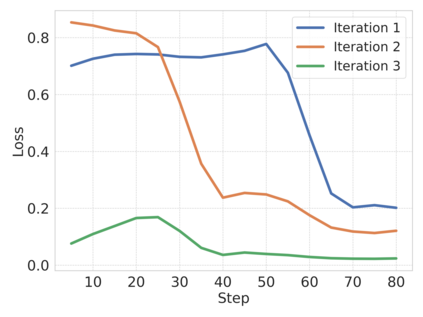
Large Language Models (LLMs) have exhibited remarkable performance across a wide range of domains, motivating research into their potential for recommendation systems. Early efforts have leveraged LLMs' rich knowledge and strong generalization capabilities via in-context learning, where recommendation tasks are framed as prompts. However, LLM performance in recommendation scenarios remains limited due to the mismatch between their pretraining objectives and recommendation tasks, as well as the lack of recommendation-specific data during pretraining. To address these challenges, we propose DPO4Rec, a novel framework that integrates Direct Preference Optimization (DPO) into LLM-enhanced recommendation systems. First, we prompt the LLM to infer user preferences from historical interactions, which are then used to augment traditional ID-based sequential recommendation models. Next, we train a reward model based on knowledge-augmented recommendation architectures to assess the quality of LLM-generated reasoning. Using this, we select the highest- and lowest-ranked responses from N samples to construct a dataset for LLM fine-tuning. Finally, we apply a structure alignment strategy via DPO to align the LLM's outputs with desirable recommendation behavior. Extensive experiments show that DPO4Rec significantly improves re-ranking performance over strong baselines, demonstrating enhanced instruction-following capabilities of LLMs in recommendation tasks.
翻译:暂无翻译