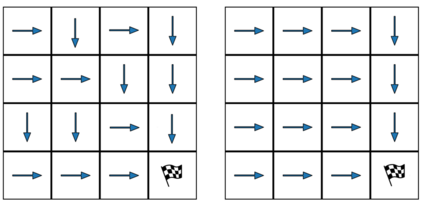
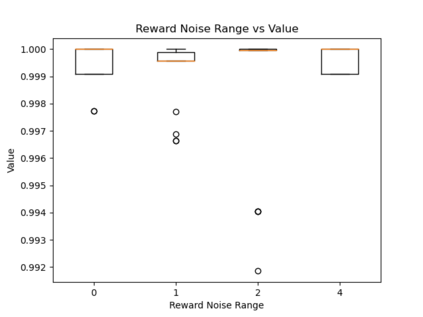
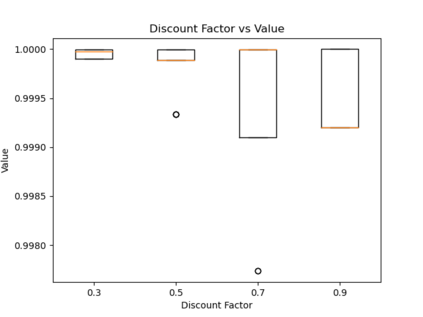
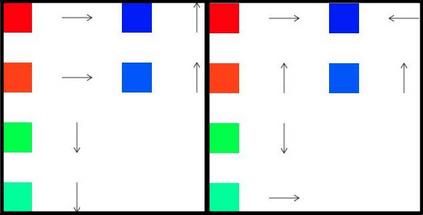
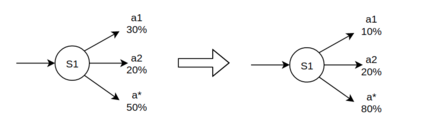
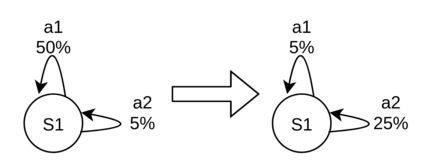
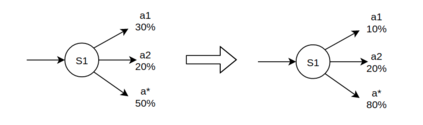
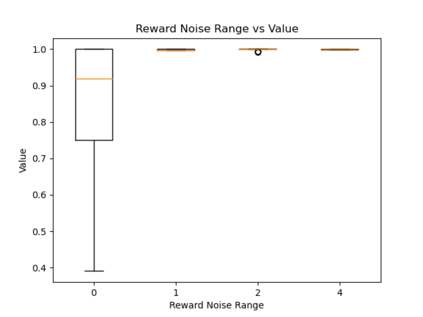
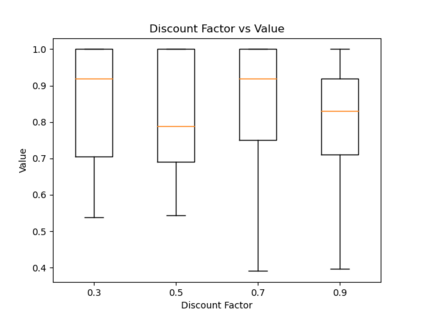
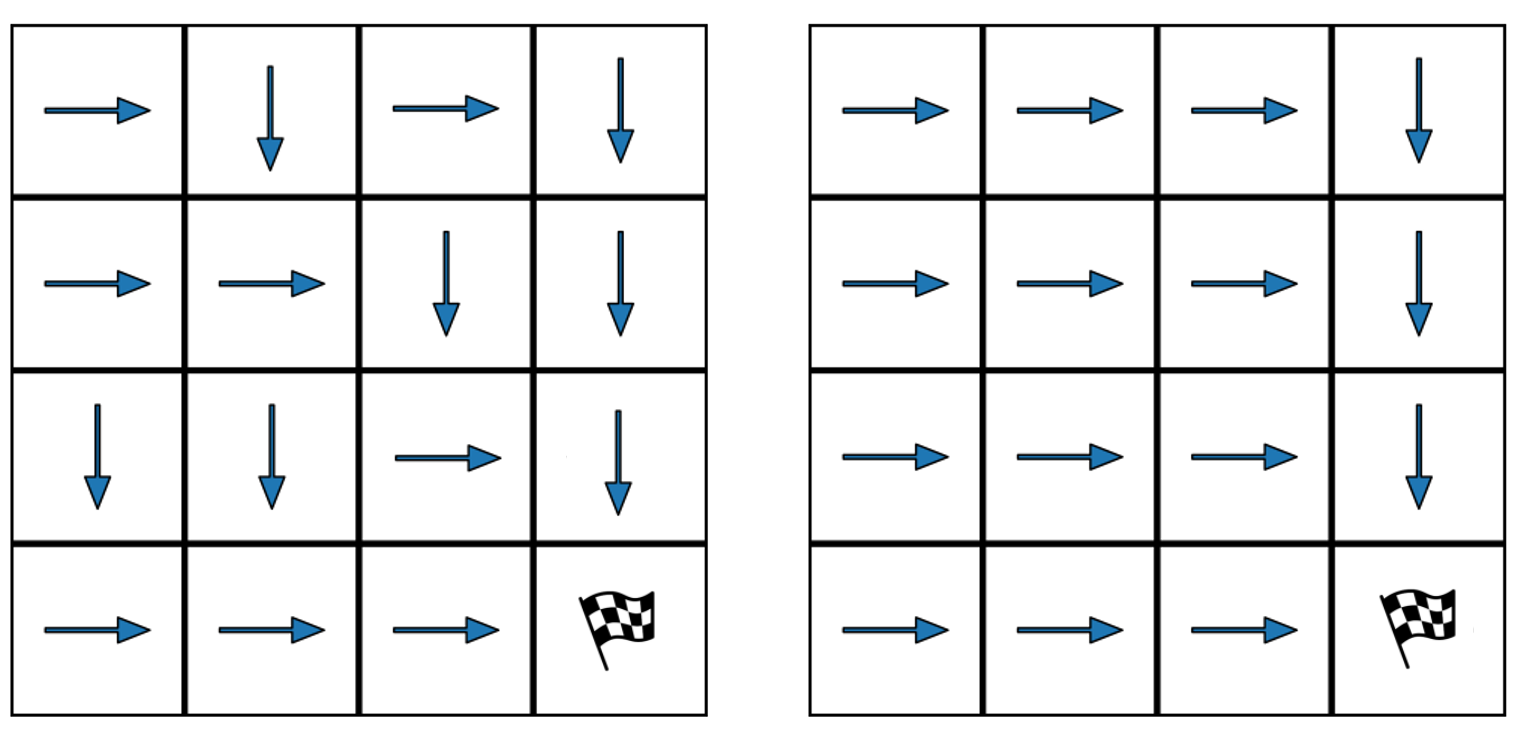
When humans are given a policy to execute, there can be pol-icy execution errors and deviations in execution if there is un-certainty in identifying a state. So an algorithm that computesa policy for a human to execute ought to consider these effectsin its computations. An optimal MDP policy that is poorly ex-ecuted (because of a human agent) maybe much worse thananother policy that is executed with fewer errors. In this pa-per, we consider the problems of erroneous execution and ex-ecution delay when computing policies for a human agent thatwould act in a setting modeled by a Markov Decision Process(MDP). We present a framework to model the likelihood ofpolicy execution errors and likelihood of non-policy actionslike inaction (delays) due to state uncertainty. This is followedby a hill climbing algorithm to search for good policies thataccount for these errors. We then use the best policy found byhill climbing with a branch and bound algorithm to find theoptimal policy. We show experimental results in a Gridworlddomain and analyze the performance of the two algorithms.We also present human studies that verify if our assumptionson policy execution by humans under state-aliasing are rea-sonable.
翻译:当人类被赋予执行政策时,如果在确定状态时不确定,执行中可能会出现极差的错误和偏差。因此,计算一个人执行的政策的算法应该在其计算中考虑这些效应。最优的 MDP 政策如果执行不力(因为人为代理),可能比执行错误较少的其他政策要差得多。在这个pa-per中,我们在计算一个以Markov 决策程序(MDP)为模型的设定为模型的人类代理人的政策时会考虑错误的执行和执行拖延问题。我们提出了一个框架,用以模拟政策执行错误的可能性和由于不确定性而采取非政策性行动的可能性。这是由山坡爬算法所遵循的,以寻找出这些错误的好政策。我们然后用一个分支和捆绑的算法来利用山坡爬所发现的最佳政策来找到最佳的政策。我们在一个Gridworddomain 中展示实验结果,并分析两种算法的性。我们还可以进行人类研究,如果我们的假设是用人类的状态执行的话,那么可以核查我们的假设。