
题目: Improving Policies via Search in Cooperative Partially Observable Games
摘要:
最近在游戏中的超人结果很大程度上是在各种零和游戏中实现的,比如围棋和扑克,在这些游戏中,玩家需要与他人竞争。然而,就像人类一样,现实世界的人工智能系统也必须在合作的、部分可观察的环境中与其他智能体进行协调和通信。这些设置通常要求参与者既要解释他人的行为,又要在解释时提供信息。这些能力通常被总结为心智理论,并被视为社会交往的关键。在本文中,我们提出了两种不同的搜索技术,可用于改进合作部分可观察博弈中的任意一致策略。第一个是单智能体搜索,它可以有效地将问题转换为单智能体。通过使除一个智能体外的所有智能体都按照商定的策略进行设置。相反,在多智能体搜索中,只要在计算上可行,所有智能体都会执行相同的公共知识搜索过程,否则就会退回到根据商定的策略进行搜索。我们证明了这些搜索过程在理论上至少保证了协议策略的原始性能(在有界近似误差范围内)。在Hanabi的基准挑战问题中,我们的搜索技术极大地提高了每一个测试的性能我们测试了智能体,当应用到使用RL训练的策略时,在游戏中获得了24.61/25的最新分数,而之前最好的分数是24.08/25。
作者简介:
Jakob Foerster是Facebook人工智能研究科学家,研究兴趣是深度学习,多智能体,强化学习,博弈论。
Noam Brown是Facebook人工智能研究科学家,研究兴趣是人工智能,博弈论算法,多智能体系统,机器学习。
成为VIP会员查看完整内容

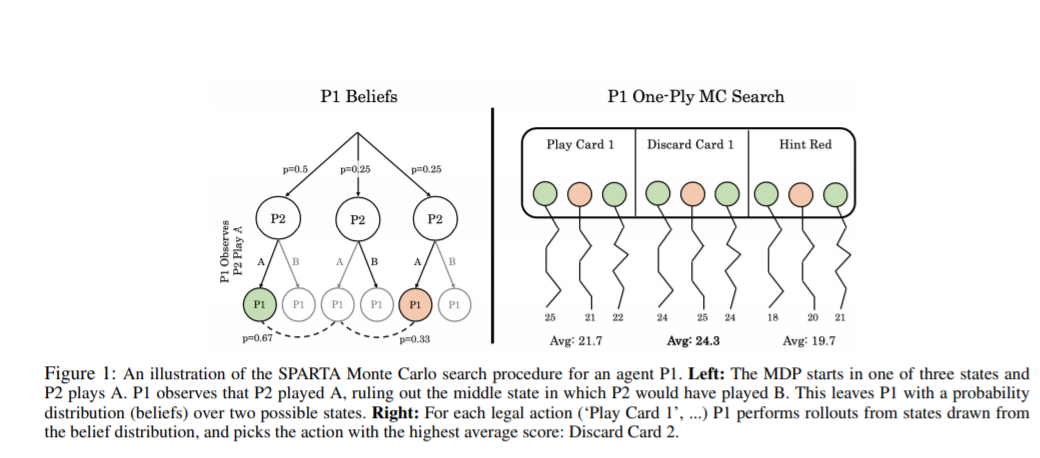

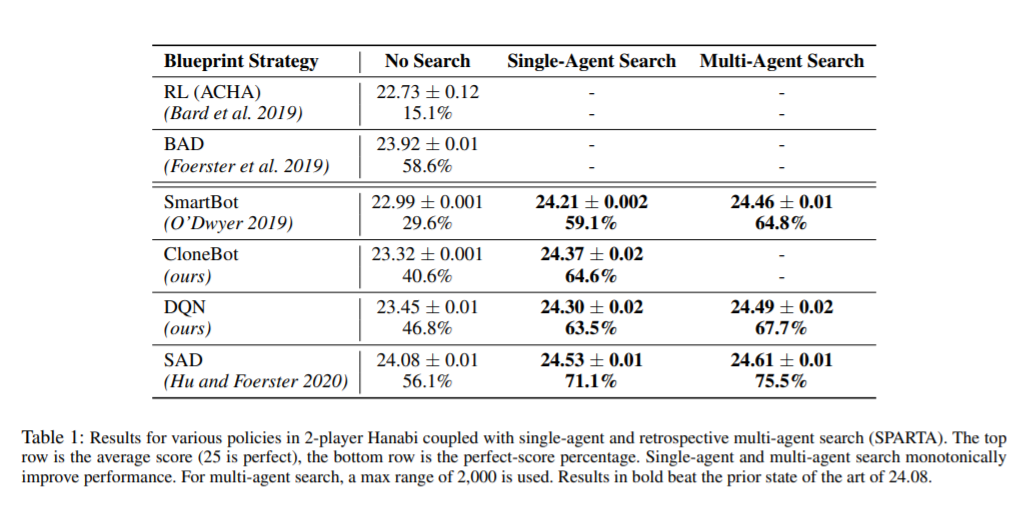
相关内容

专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
24+阅读 · 2019年11月11日
专知会员服务
13+阅读 · 2019年10月3日
Arxiv
4+阅读 · 2018年3月30日


相关VIP内容
专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
24+阅读 · 2019年11月11日
专知会员服务
13+阅读 · 2019年10月3日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年3月30日