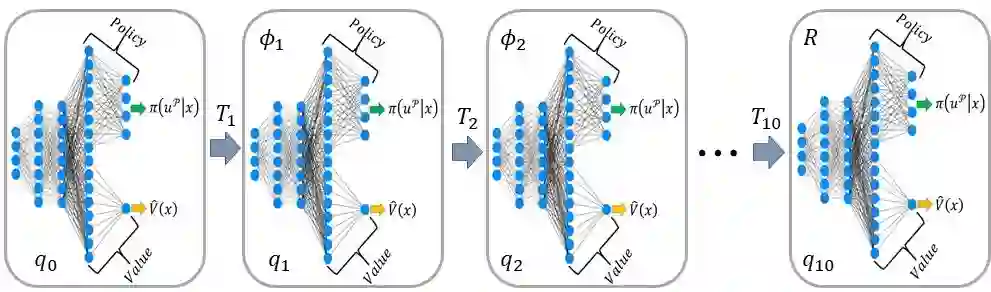
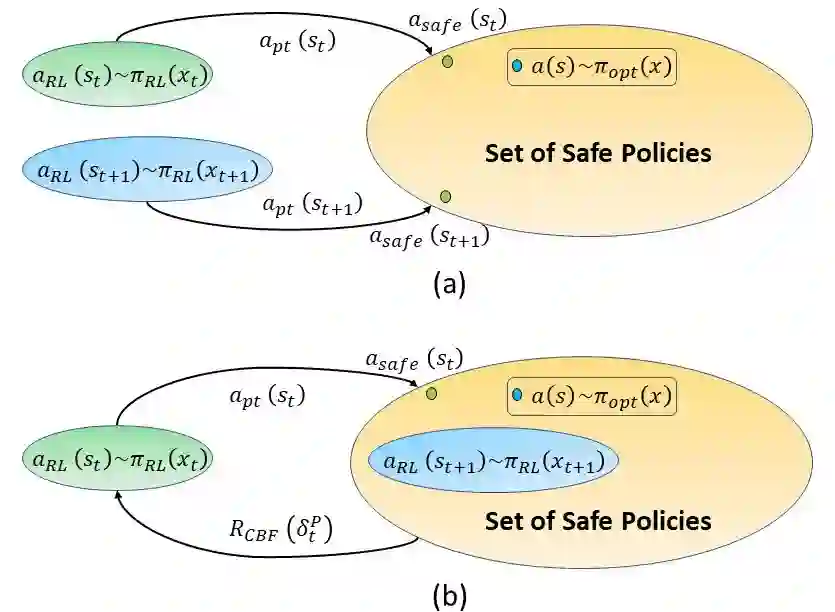
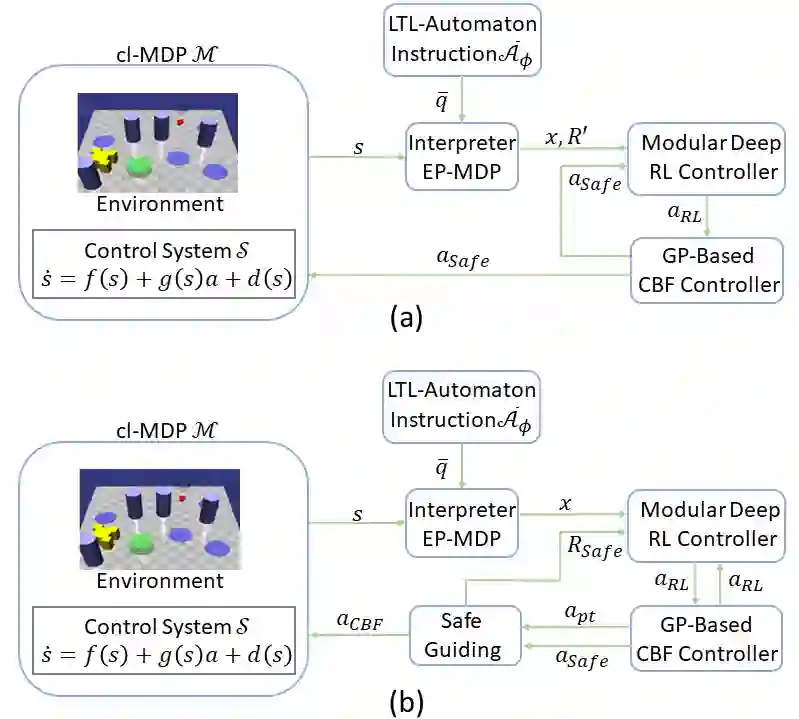
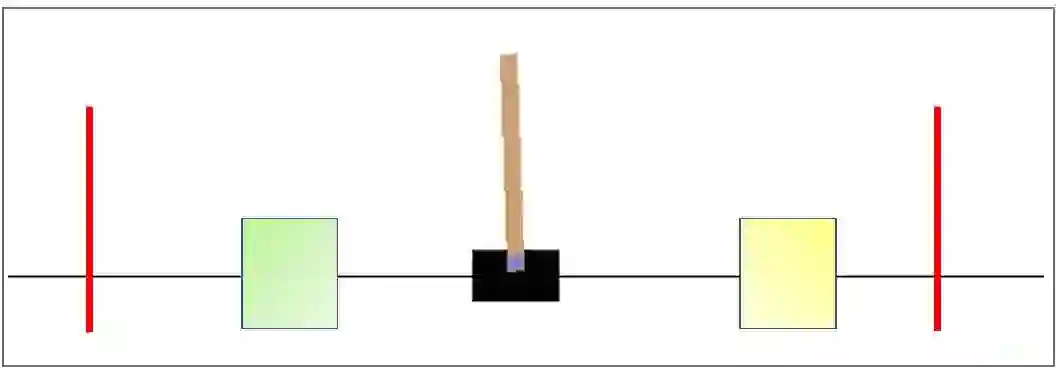
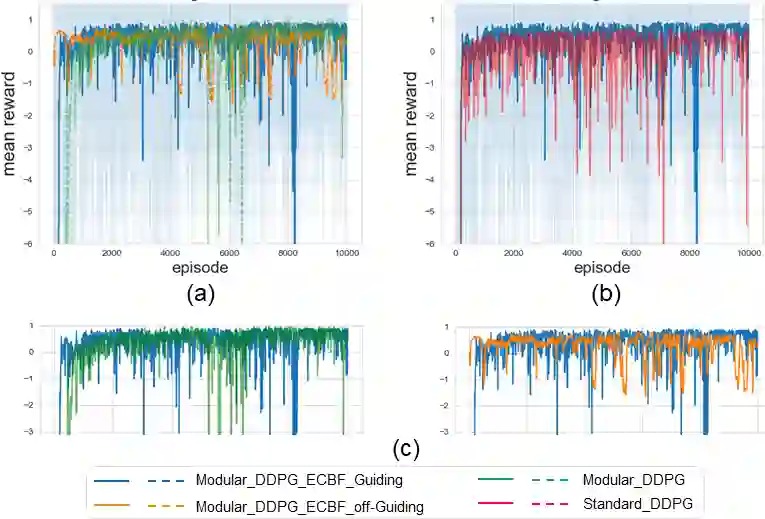
Reinforcement learning (RL) is a promising approach and has limited success towards real-world applications, because ensuring safe exploration or facilitating adequate exploitation is a challenge for controlling robotic systems with unknown models and measurement uncertainties. Such a learning problem becomes even more intractable for complex tasks over continuous space (state-space and action-space). In this paper, we propose a learning-based control framework consisting of several aspects: (1) linear temporal logic (LTL) is leveraged to facilitate complex tasks over an infinite horizons which can be translated to a novel automaton structure; (2) we propose an innovative reward scheme for RL-agent with the formal guarantee such that global optimal policies maximize the probability of satisfying the LTL specifications; (3) based on a reward shaping technique, we develop a modular policy-gradient architecture utilizing the benefits of automaton structures to decompose overall tasks and facilitate the performance of learned controllers; (4) by incorporating Gaussian Processes (GPs) to estimate the uncertain dynamic systems, we synthesize a model-based safeguard using Exponential Control Barrier Functions (ECBFs) to address problems with high-order relative degrees. In addition, we utilize the properties of LTL automatons and ECBFs to construct a guiding process to further improve the efficiency of exploration. Finally, we demonstrate the effectiveness of the framework via several robotic environments. And we show such an ECBF-based modular deep RL algorithm achieves near-perfect success rates and guard safety with a high probability confidence during training.
翻译:强化学习(RL)是一个很有希望的方法,在现实世界应用方面取得的成功有限,因为确保安全探索或促进充分开发是控制具有未知模型和测量不确定性的机器人系统的挑战,这种学习问题对于连续空间(状态空间和动作空间)的复杂任务变得更加棘手。在本文中,我们提议一个学习控制框架,包括几个方面:(1) 利用线性时间逻辑(LTL),在一个无限的视野上推动复杂的任务,可以转化为新的自动结构;(2) 我们提议为RL试剂制定创新奖励计划,正式保证全球最佳政策最大限度地提高满足LTL规格的可能性;(3) 以奖励塑造技术为基础,我们开发一个模块化政策梯度结构,利用自动马顿结构的好处,拆分解总体任务,便利学习控制员的绩效;(4) 利用Gaussian Processes(GPs)来评估不确定的动态系统,我们用深度控制障碍功能(ECBBF)来综合基于模型的保障,以便用高度的概率(ECBF)来进一步解决问题。此外,我们利用LBR-R-R-R-Acal-Acal-Acal-Acal-Adental acal acal acal bestrual destration acal destrut the sal destrual destrual destrut the the the the the the the sal laut the lautal and lautal acal acal ax lautal to laututus and and and and and and and laututututaldal)。