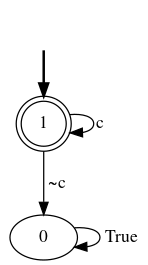
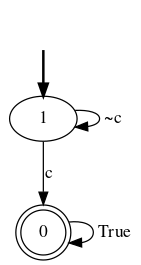
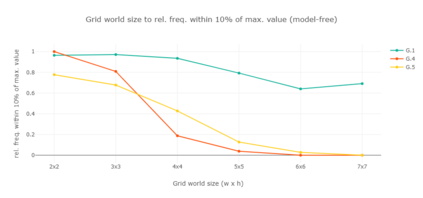
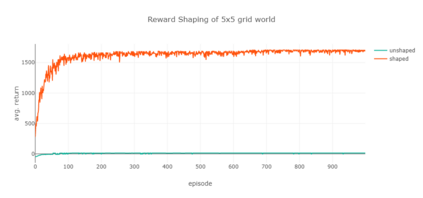
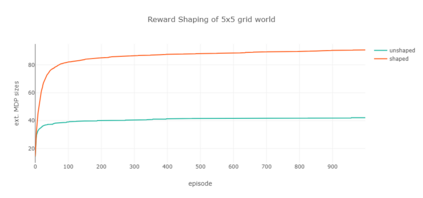
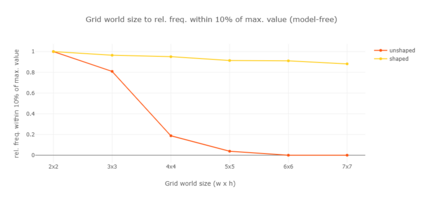
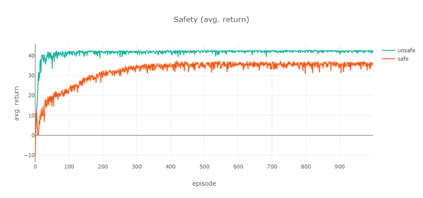
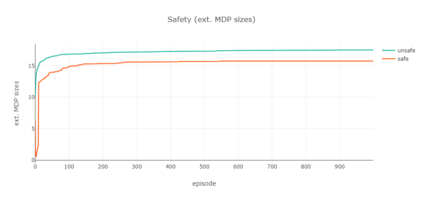
Markov decision processes are typically used for sequential decision making under uncertainty. For many aspects however, ranging from constrained or safe specifications to various kinds of temporal (non-Markovian) dependencies in task and reward structures, extensions are needed. To that end, in recent years interest has grown into combinations of reinforcement learning and temporal logic, that is, combinations of flexible behavior learning methods with robust verification and guarantees. In this paper we describe an experimental investigation of the recently introduced regular decision processes that support both non-Markovian reward functions as well as transition functions. In particular, we provide a tool chain for regular decision processes, algorithmic extensions relating to online, incremental learning, an empirical evaluation of model-free and model-based solution algorithms, and applications in regular, but non-Markovian, grid worlds.
翻译:马尔科夫决策程序通常在不确定的情况下用于顺序决策,但在许多方面,从限制或安全规格到任务和奖励结构中各种时间(非马尔科维人)依赖性(非马尔科维人),都需要延期,为此,近年来,兴趣已发展成为强化学习和时间逻辑的结合,即将灵活行为学习方法与强有力的核查和保障相结合。本文介绍了对最近引入的常规决策程序的试验性调查,该程序既支持非马尔科维人奖励功能,也支持过渡功能。特别是,我们为常规决策程序、与在线、渐进学习有关的算法扩展、无模型和基于模型的解决方案算法的经验评估以及常规但非马尔科维人电网世界的应用提供了一个工具链。