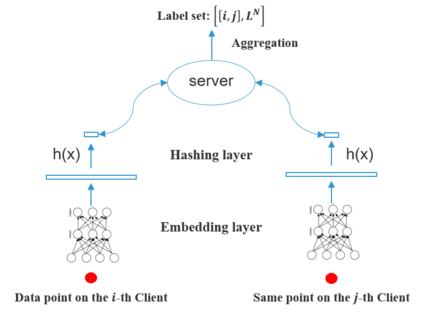
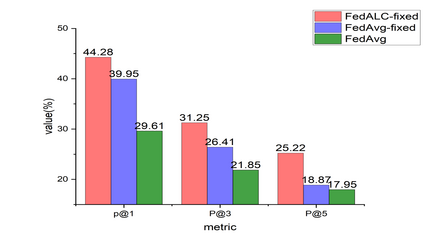
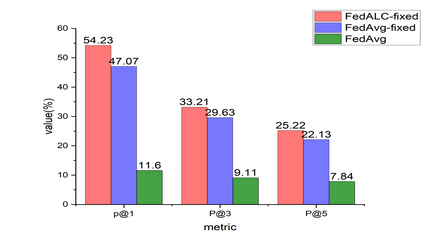
Federated learning aims to collaboratively learn a model by using the data from multiple users under privacy constraints. In this paper, we study the multi-label classification problem under the federated learning setting, where trivial solution and extremely poor performance may be obtained, especially when only positive data w.r.t. a single class label are provided for each client. This issue can be addressed by adding a specially designed regularizer on the server-side. Although effective sometimes, the label correlations are simply ignored and thus sub-optimal performance may be obtained. Besides, it is expensive and unsafe to exchange user's private embeddings between server and clients frequently, especially when training model in the contrastive way. To remedy these drawbacks, we propose a novel and generic method termed Federated Averaging by exploring Label Correlations (FedALC). Specifically, FedALC estimates the label correlations in the class embedding learning for different label pairs and utilizes it to improve the model training. To further improve the safety and also reduce the communication overhead, we propose a variant to learn fixed class embedding for each client, so that the server and clients only need to exchange class embeddings once. Extensive experiments on multiple popular datasets demonstrate that our FedALC can significantly outperform existing counterparts.
翻译:暂无翻译