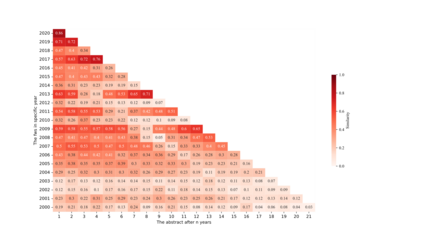
Future work sentences (FWS) are the particular sentences in academic papers that contain the author's description of their proposed follow-up research direction. This paper presents methods to automatically extract FWS from academic papers and classify them according to the different future directions embodied in the paper's content. FWS recognition methods will enable subsequent researchers to locate future work sentences more accurately and quickly and reduce the time and cost of acquiring the corpus. The current work on automatic identification of future work sentences is relatively small, and the existing research cannot accurately identify FWS from academic papers, and thus cannot conduct data mining on a large scale. Furthermore, there are many aspects to the content of future work, and the subdivision of the content is conducive to the analysis of specific development directions. In this paper, Nature Language Processing (NLP) is used as a case study, and FWS are extracted from academic papers and classified into different types. We manually build an annotated corpus with six different types of FWS. Then, automatic recognition and classification of FWS are implemented using machine learning models, and the performance of these models is compared based on the evaluation metrics. The results show that the Bernoulli Bayesian model has the best performance in the automatic recognition task, with the Macro F1 reaching 90.73%, and the SCIBERT model has the best performance in the automatic classification task, with the weighted average F1 reaching 72.63%. Finally, we extract keywords from FWS and gain a deep understanding of the key content described in FWS, and we also demonstrate that content determination in FWS will be reflected in the subsequent research work by measuring the similarity between future work sentences and the abstracts.
翻译:未来工作判决(FWS)是学术论文中包含作者对其拟议后续研究方向描述的学术论文中特别的句子。本文介绍了自动从学术论文中从学术论文中提取FWS并按文件内容所体现的未来不同方向进行分类的方法。FWS的识别方法将使后续研究人员能够更准确和迅速地定位未来工作判决,并减少获取该判决的时间和费用。目前自动确定未来工作判决的工作相对较少,现有研究无法准确地从学术论文中找出FWS,从而无法大规模地进行数据挖掘。此外,未来工作的内容有许多方面,内容的细分有助于分析具体发展方向。在本论文中,自然语言处理(NLP)作为案例研究使用,而FWSWS从学术论文中抽取出,并按不同类型分类。我们手动建立一个附加说明的附加说明的文集,有六种不同的FWSWS。随后的自动识别和分类将使用机器学习模型,这些模型的运行情况将基于评估指标的很多方面内容,而且内容的分级部分有助于分析具体发展方向方向。在本文件中,BERIFSWSWS1和SBSBSFBSBSA的自动确认最佳的成绩。我们最终的成绩和SBIFIFB任务中,在SBSBSLLLSBSBSBS的成绩模型中,在达到了最佳的成绩模型的成绩和SBSBSBA中展示了最佳的成绩中,在达到最佳的成绩中,在SBSBSBBBA中,在SBA中,在SBBB中,在SBLA中,在SBLIFSB中,在达到最佳的成绩中,在SBSB中显示了最佳的成绩的成绩和SBSBSBSBSBA中,在SBA中显示了最佳的成绩中,在达到了最佳的成绩中,在SBBBLBLBLBLA中,在SBA中,在SBSBA中,在SB中,在SBA中,在达到了最佳的成绩和SBSBSBSBSBSBSBSBA中,在SBA中,在SBA中,在SBA中