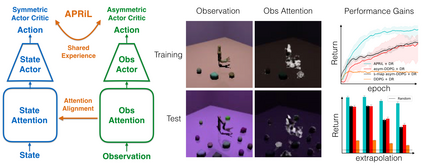
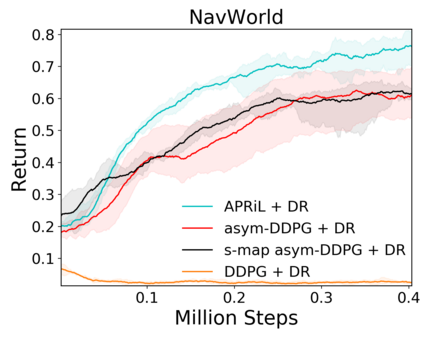
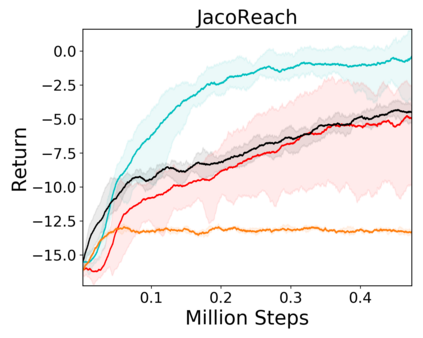
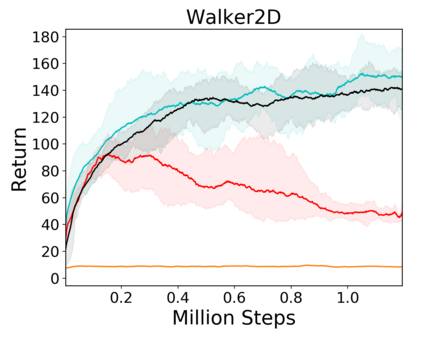
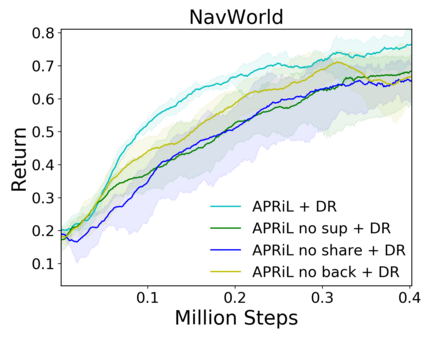
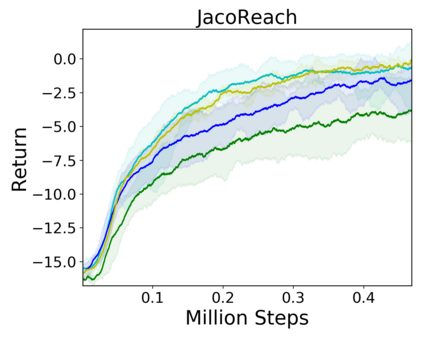
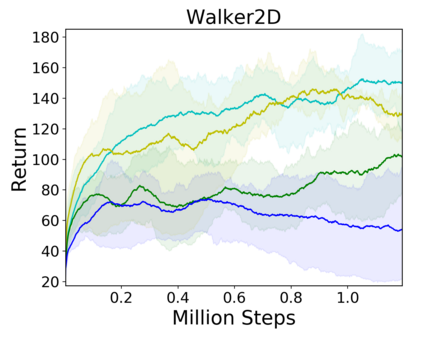
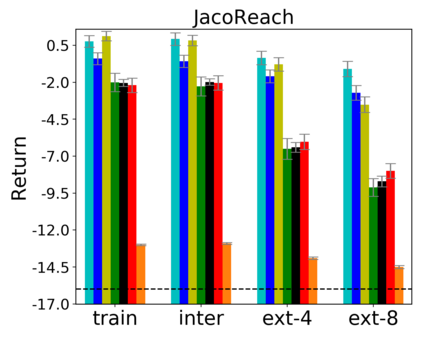
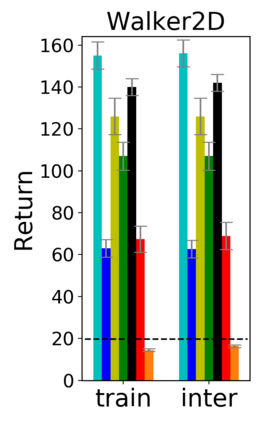
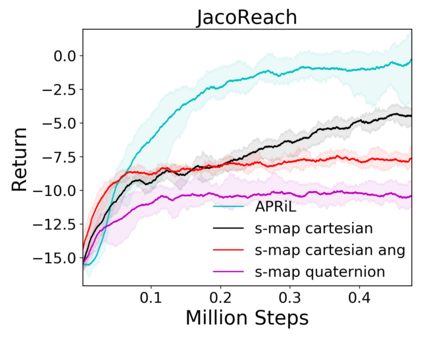
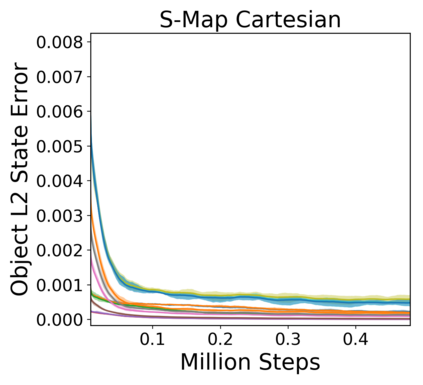
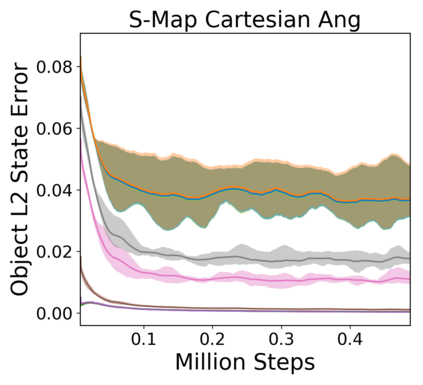
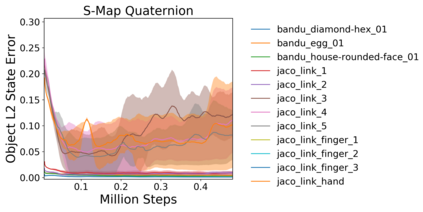
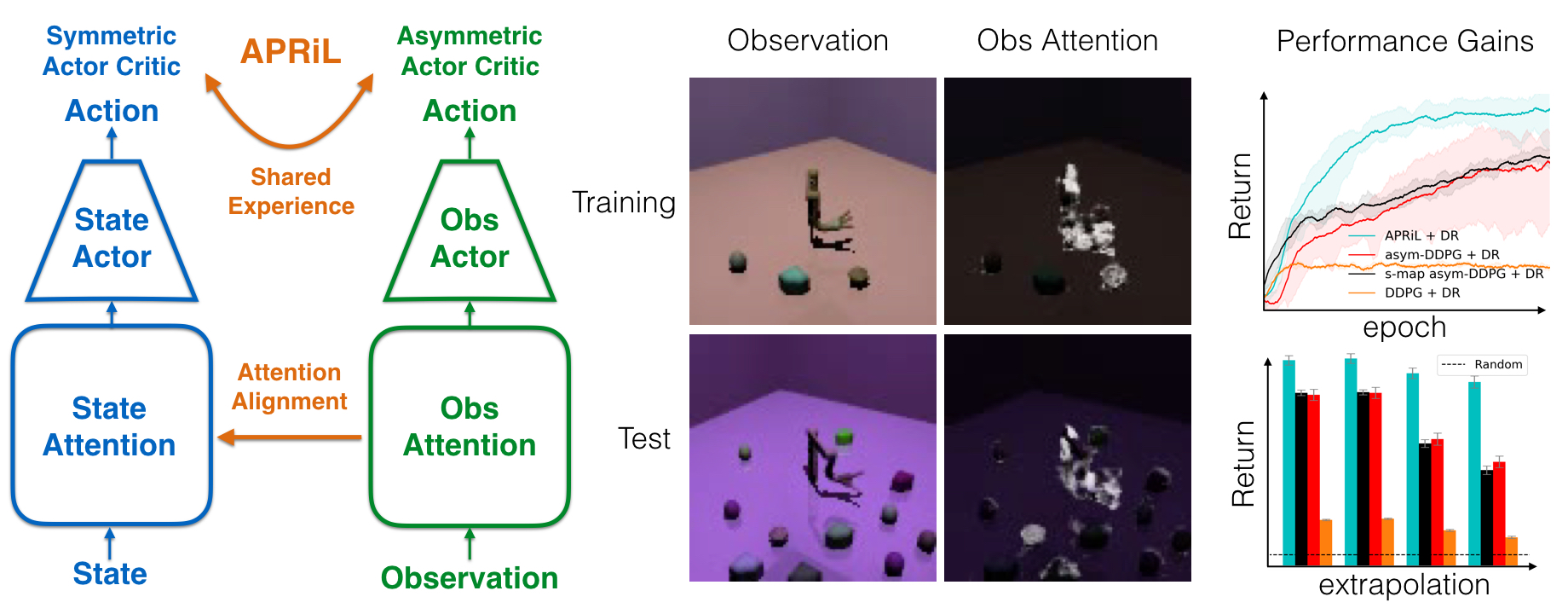
Image-based Reinforcement Learning is known to suffer from poor sample efficiency and generalisation to unseen visuals such as distractors (task-independent aspects of the observation space). Visual domain randomisation encourages transfer by training over visual factors of variation that may be encountered in the target domain. This increases learning complexity, can negatively impact learning rate and performance, and requires knowledge of potential variations during deployment. In this paper, we introduce Attention-Privileged Reinforcement Learning (APRiL) which uses a self-supervised attention mechanism to significantly alleviate these drawbacks: by focusing on task-relevant aspects of the observations, attention provides robustness to distractors as well as significantly increased learning efficiency. APRiL trains two attention-augmented actor-critic agents: one purely based on image observations, available across training and transfer domains; and one with access to privileged information (such as environment states) available only during training. Experience is shared between both agents and their attention mechanisms are aligned. The image-based policy can then be deployed without access to privileged information. We experimentally demonstrate accelerated and more robust learning on a diverse set of domains, leading to improved final performance for environments both within and outside the training distribution.
翻译:据了解,基于图像的强化学习因抽样效率低下而受到影响,并被概括到诸如分流器等看不见的视觉(观测空间与任务无关的方面)。视觉域随机随机学鼓励通过培训进行转让,以克服目标领域可能遇到的变异的视觉因素。这增加了学习的复杂性,可能会对学习率和性能产生消极影响,需要了解部署期间可能出现的差异。在本文件中,我们引入了“注意优先的强化学习”(APRIL),它使用一种自我监督的关注机制,以大大缓解这些缺陷:通过侧重于与任务相关的观测,关注分散器的强健性和显著提高学习效率。 APRIL培训了两种关注的、强化的行为者-批评剂:一种纯粹基于图像观测的,可在培训和转移领域之间提供;另一种是仅可在培训期间获得特权信息(如环境状况),两种机构及其关注机制都相互交流经验。然后可以在无法获取特权信息的情况下部署基于图像的政策。我们实验性地展示了在一系列不同领域加速和更有力地学习,从而改进了外部环境的最终绩效。