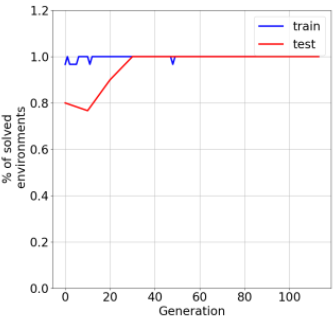
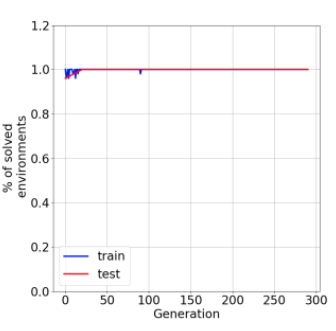
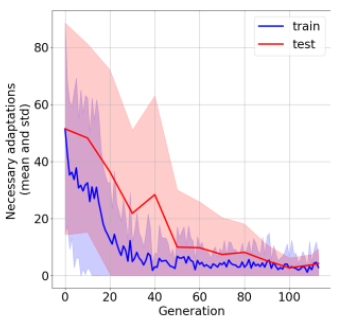
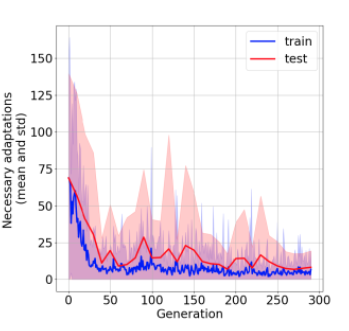
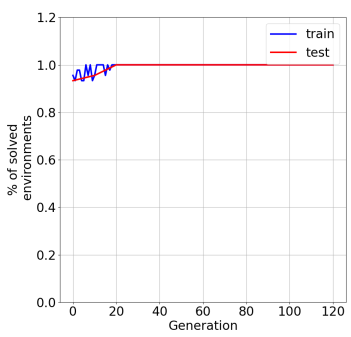
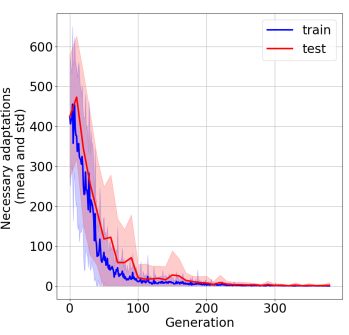
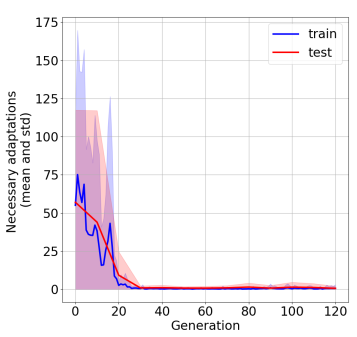
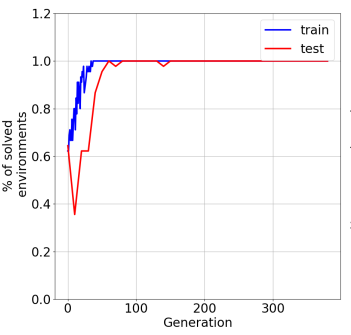
In the past few years, a considerable amount of research has been dedicated to the exploitation of previous learning experiences and the design of Few-shot and Meta Learning approaches, in problem domains ranging from Computer Vision to Reinforcement Learning based control. A notable exception, where to the best of our knowledge, little to no effort has been made in this direction is Quality-Diversity (QD) optimisation. QD methods have been shown to be effective tools in dealing with deceptive minima and sparse rewards in Reinforcement Learning. However, they remain costly due to their reliance on inherently sample inefficient evolutionary processes. We show that, given examples from a task distribution, information about the paths taken by optimisation in parameter space can be leveraged to build a prior population, which when used to initialise QD methods in unseen environments, allows for few-shot adaptation. Our proposed method does not require backpropagation. It is simple to implement and scale, and furthermore, it is agnostic to the underlying models that are being trained. Experiments carried in both sparse and dense reward settings using robotic manipulation and navigation benchmarks show that it considerably reduces the number of generations that are required for QD optimisation in these environments.
翻译:在过去几年里,大量研究致力于在从计算机视野到强化学习控制等问题领域,利用以往的学习经验,并设计了少见的和少见的学习和元的学习方法,从计算机视野到强化学习控制,这是一个显著的例外,在这方面,我们最了解的、很少或没有作出努力的方面是质量多样性(QD)优化。QD方法被证明是处理强化学习中欺骗性微小和微量奖励的有效工具。然而,由于依赖内在抽样的低效率演化过程,这些方法仍然费用高昂。我们表明,鉴于任务分布的实例,可以利用关于参数空间优化所走的道路的信息来建立先前的人口,在使用在不见环境中的本地化的QD方法时,可以进行几度调整。我们提出的方法并不需要反常调,实施和规模简单,而且对正在培训的基本模式而言,这是微不足道的。使用机器人操纵和导航基准在稀有和密集的奖励环境中进行的实验表明,选择这些环境所需的代数大大降低。