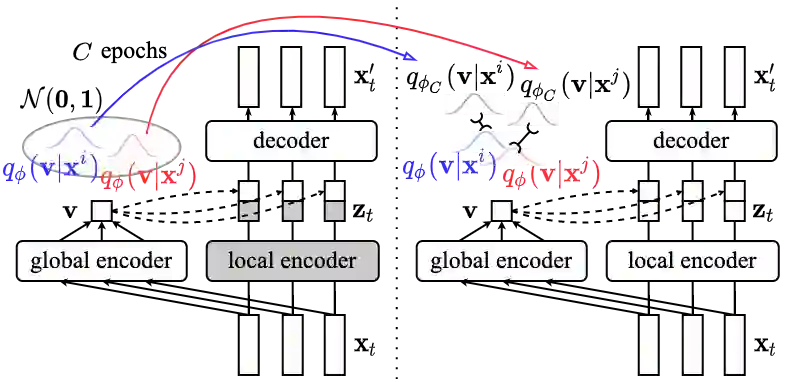
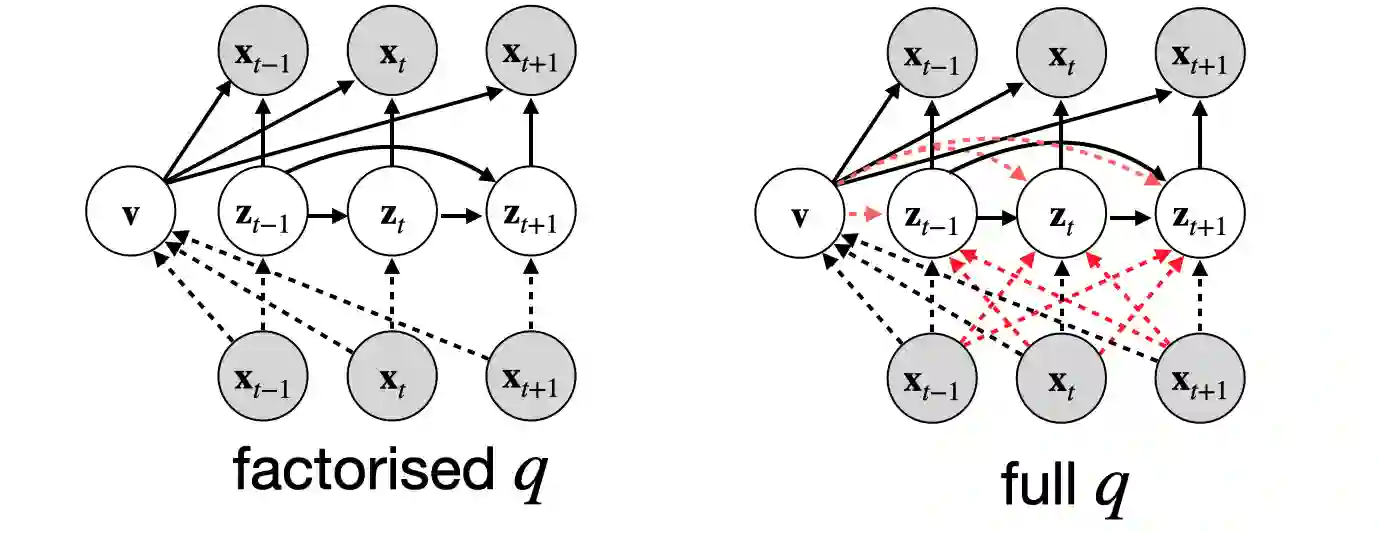
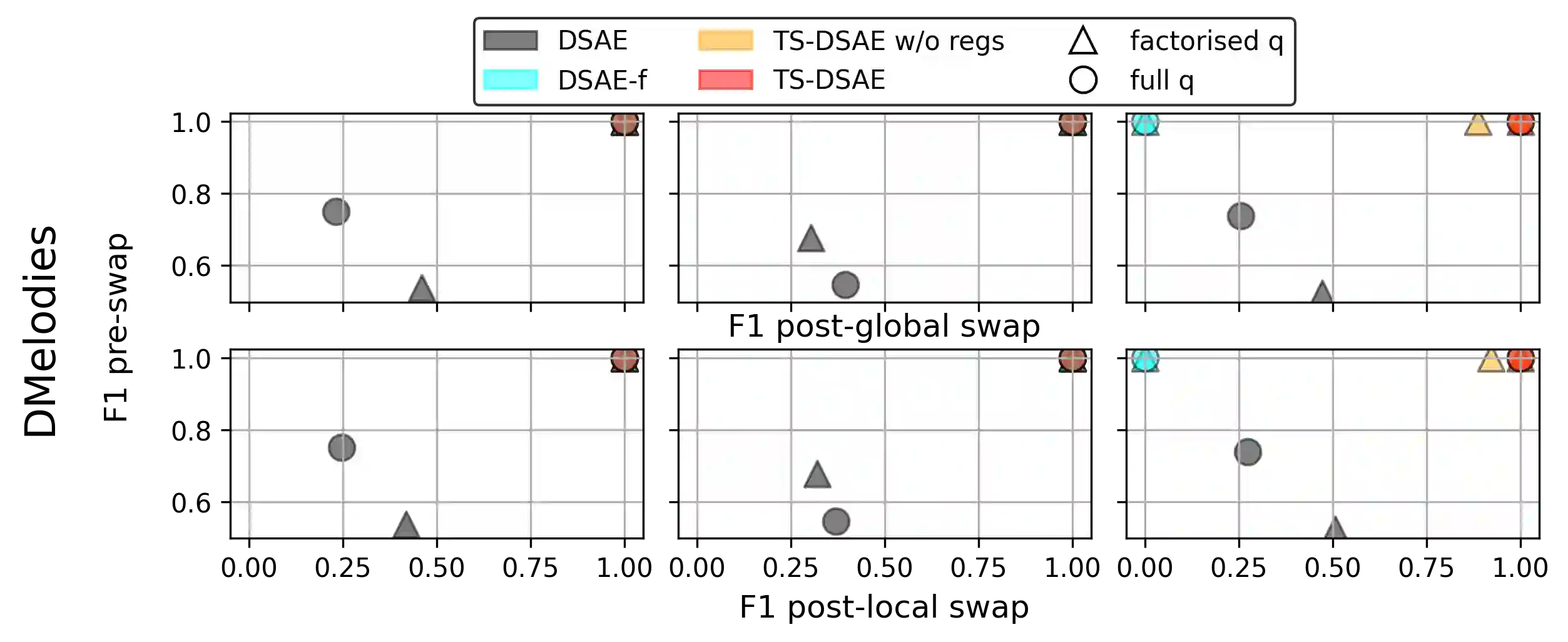
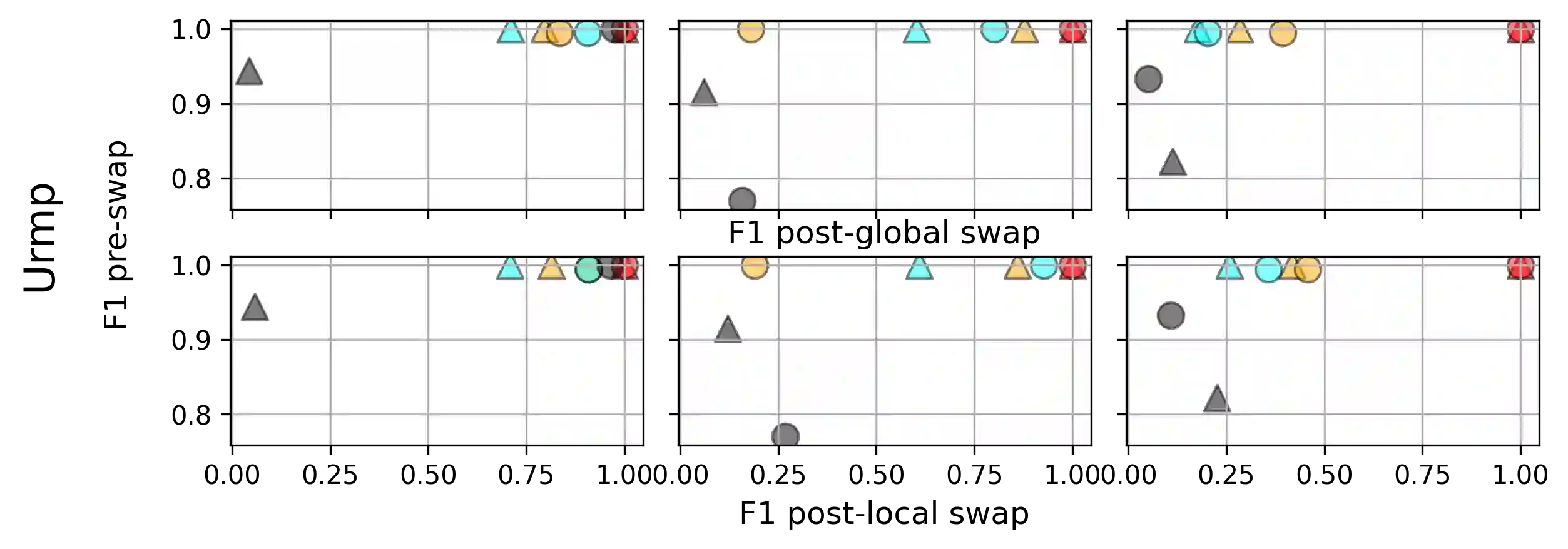
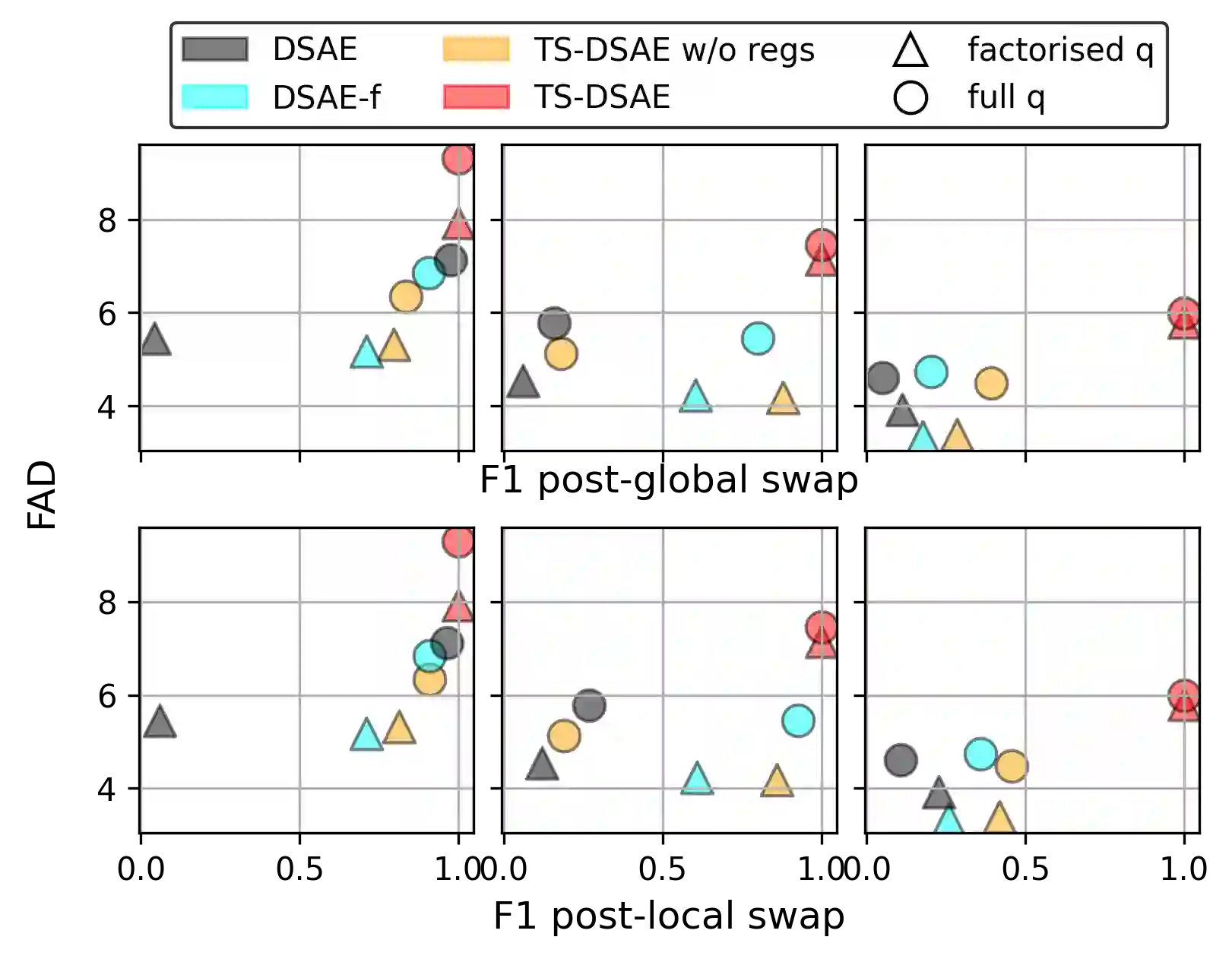
Disentangled sequential autoencoders (DSAEs) represent a class of probabilistic graphical models that describes an observed sequence with dynamic latent variables and a static latent variable. The former encode information at a frame rate identical to the observation, while the latter globally governs the entire sequence. This introduces an inductive bias and facilitates unsupervised disentanglement of the underlying local and global factors. In this paper, we show that the vanilla DSAE suffers from being sensitive to the choice of model architecture and capacity of the dynamic latent variables, and is prone to collapse the static latent variable. As a countermeasure, we propose TS-DSAE, a two-stage training framework that first learns sequence-level prior distributions, which are subsequently employed to regularise the model and facilitate auxiliary objectives to promote disentanglement. The proposed framework is fully unsupervised and robust against the global factor collapse problem across a wide range of model configurations. It also avoids typical solutions such as adversarial training which usually involves laborious parameter tuning, and domain-specific data augmentation. We conduct quantitative and qualitative evaluations to demonstrate its robustness in terms of disentanglement on both artificial and real-world music audio datasets.
翻译:分解的连续自动编码器( DSAE) 是一组概率化的图形模型, 它描述了观察到的序列, 带有动态潜伏变量和静态潜伏变量。 前一个编码信息, 其框架速率与观测相同, 而后一个框架则支配整个序列。 这引入了诱导偏差, 便于不受监督地分解潜在的当地和全球因素。 在本文中, 我们显示香草 DSAE 对动态潜伏变量的模型结构和能力的选择十分敏感, 并且容易崩溃静态潜伏变量。 作为对策, 我们提议TS- DSAE, 是一个两阶段培训框架, 首先学习序列级前分布, 随后用于规范模型, 并促进辅助目标, 以促进分解。 拟议的框架完全不受监督和稳健, 与广泛的模型配置中的全球因素崩溃问题相适应。 它还避免典型的解决方案, 例如通常涉及劳累参数调换的对抗性培训, 和特定域数据扩增。 我们进行定量和定性评估, 以显示其真实的磁性数据。