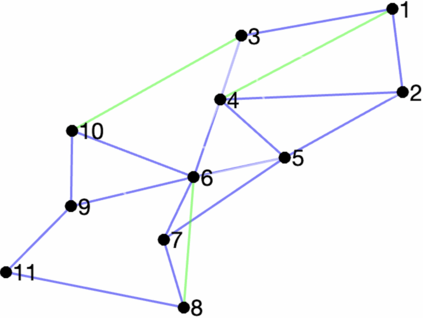
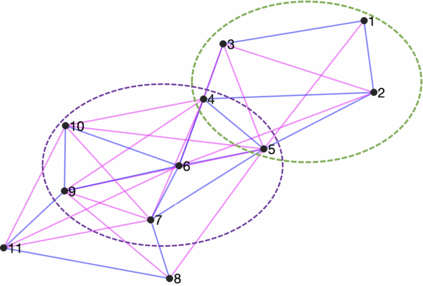
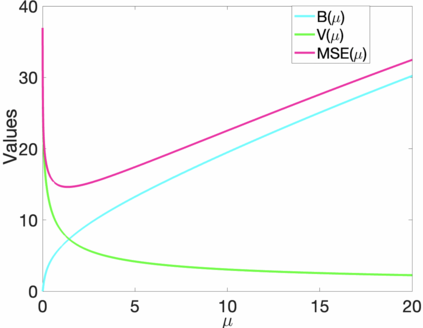
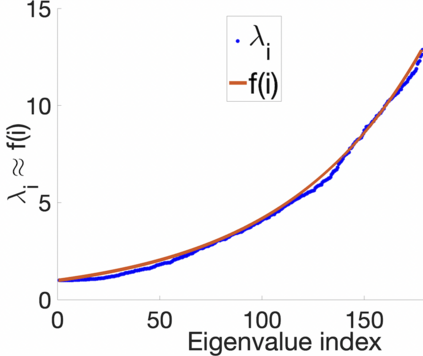
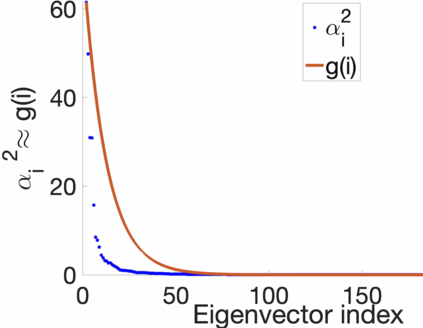
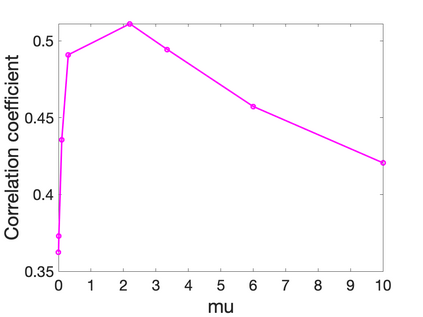
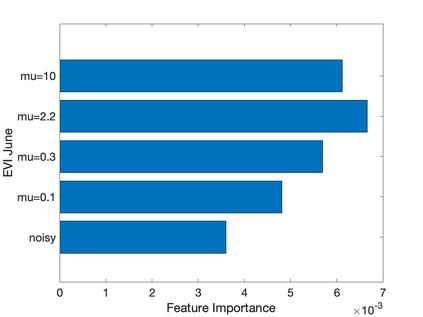
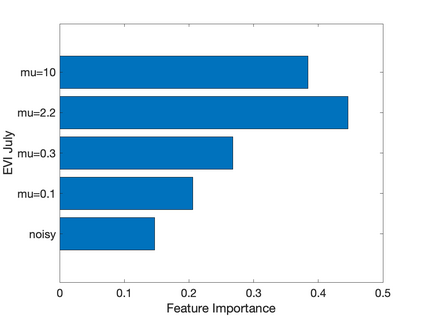
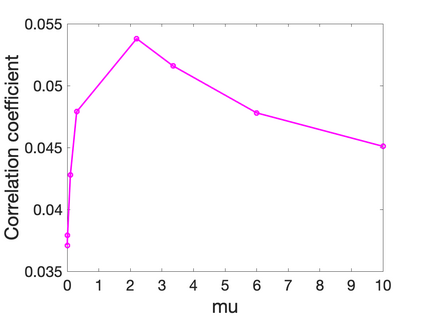
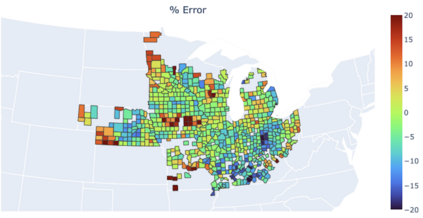
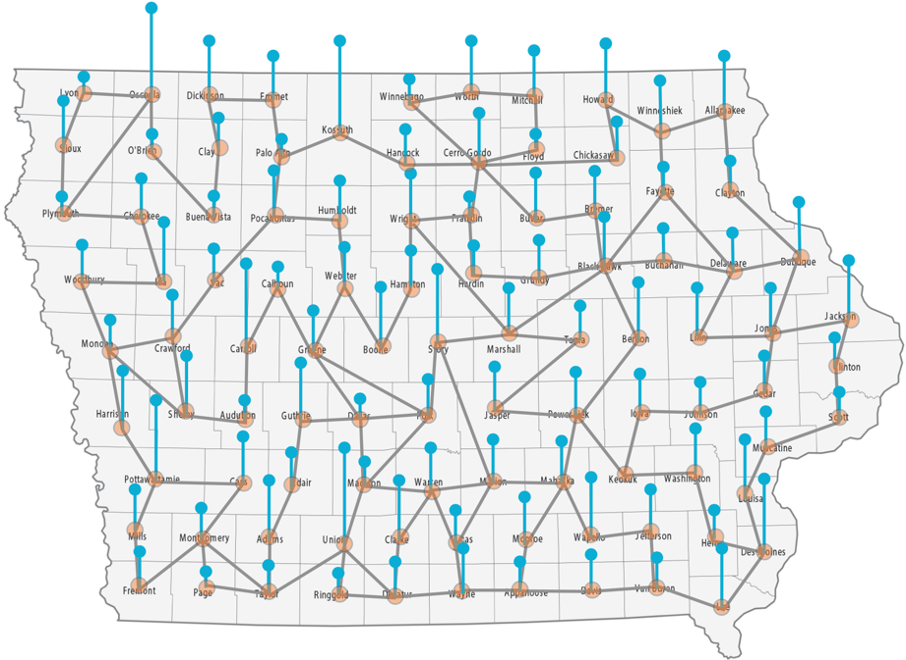
Prediction of annual crop yields at a county granularity is important for national food production and price stability. In this paper, towards the goal of better crop yield prediction, leveraging recent graph signal processing (GSP) tools to exploit spatial correlation among neighboring counties, we denoise relevant features via graph spectral filtering that are inputs to a deep learning prediction model. Specifically, we first construct a combinatorial graph with edge weights that encode county-to-county similarities in soil and location features via metric learning. We then denoise features via a maximum a posteriori (MAP) formulation with a graph Laplacian regularizer (GLR). We focus on the challenge to estimate the crucial weight parameter $\mu$, trading off the fidelity term and GLR, that is a function of noise variance in an unsupervised manner. We first estimate noise variance directly from noise-corrupted graph signals using a graph clique detection (GCD) procedure that discovers locally constant regions. We then compute an optimal $\mu$ minimizing an approximate mean square error function via bias-variance analysis. Experimental results from collected USDA data show that using denoised features as input, performance of a crop yield prediction model can be improved noticeably.
翻译:在本文件中,为了更好地预测作物产量,利用最近的图形信号处理(GSP)工具来利用相邻各州之间的空间相关性,我们通过图形光谱过滤器来淡化相关特征,这些特征是深入学习的预测模型的投入。具体地说,我们首先建立一个具有边重的组合式图表,通过量度学习将土壤和位置特征的州与州之间的相似点和位置特征编码起来。然后,我们通过以拉巴拉西常规化成像图(GLR)的后生(MAP)配方(MAP)最优化地(MAP)来淡化特征。我们把重点放在评估关键重量参数($\mu$)的挑战上,交易忠诚期和GLR,这是以非超强的方式产生噪音差异的函数。我们首先利用一种图形分级检测(GCD)程序来直接估计噪音与州与州之间的相似点信号。我们随后通过偏差模型(GLRR)来计算一个最佳的美元/穆(MA)最大限度地减少一个近似的正方形错误功能。从所收集的美国作物预测的实验性预测结果,可以显示改进的绩效。