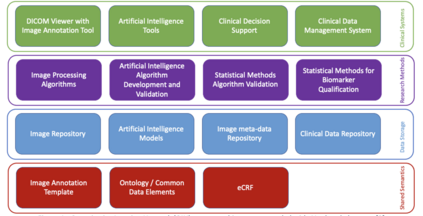
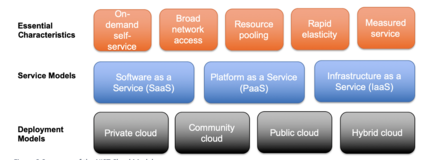
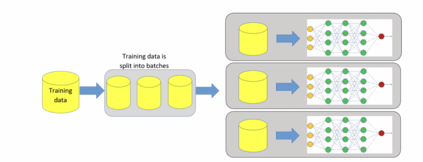
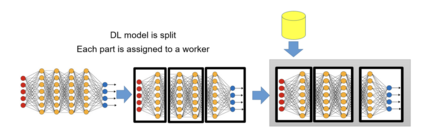
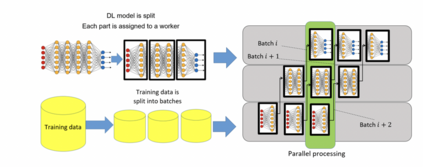
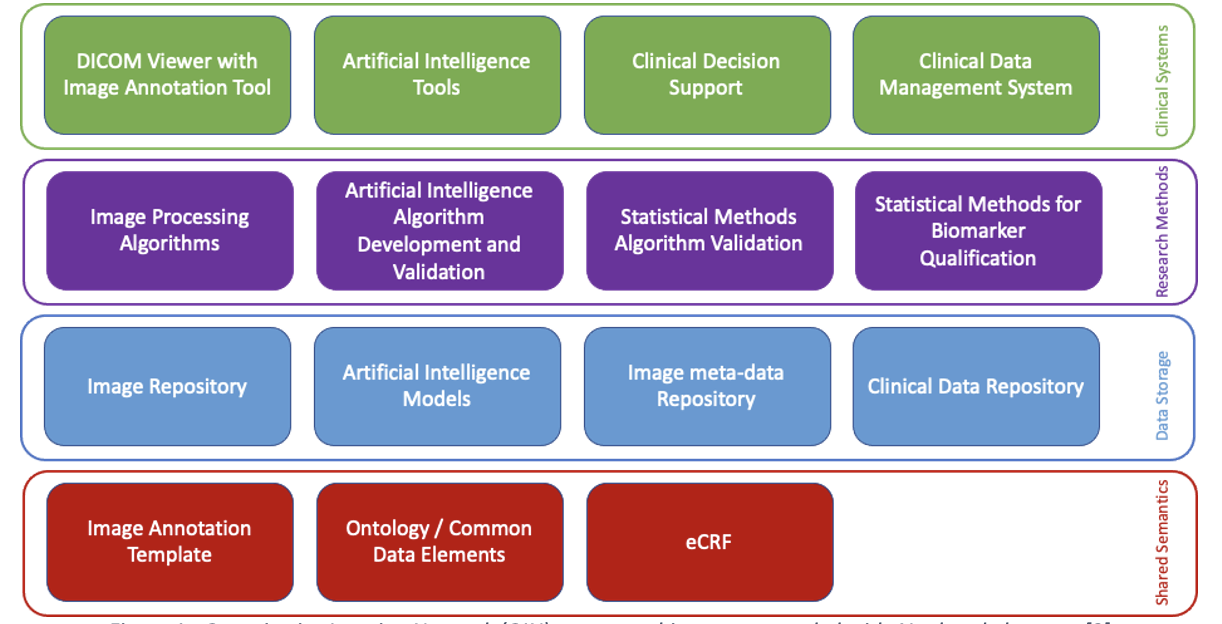
Artificial intelligence (AI), especially deep learning, requires vast amounts of data for training, testing, and validation. Collecting these data and the corresponding annotations requires the implementation of imaging biobanks that provide access to these data in a standardized way. This requires careful design and implementation based on the current standards and guidelines and complying with the current legal restrictions. However, the realization of proper imaging data collections is not sufficient to train, validate and deploy AI as resource demands are high and require a careful hybrid implementation of AI pipelines both on-premise and in the cloud. This chapter aims to help the reader when technical considerations have to be made about the AI environment by providing a technical background of different concepts and implementation aspects involved in data storage, cloud usage, and AI pipelines.
翻译:收集这些数据和相应的说明需要执行成像生物库,以标准化的方式提供获取这些数据的机会,这需要根据现行标准和准则仔细设计和实施,并遵守目前的法律限制,然而,适当的成像数据收集工作不足以培训、验证和部署AI,因为资源需求很高,需要谨慎地混合实施AI在预设和云中的管道,本章的目的是在需要从技术角度考虑AI环境时,通过提供数据储存、云的使用和AI管道所涉不同概念和执行方面的技术背景,帮助读者。