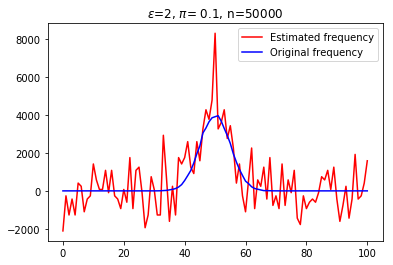
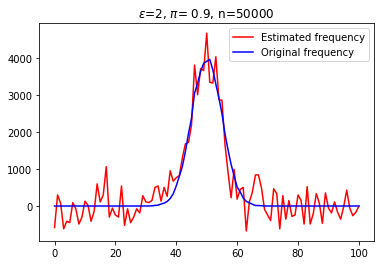
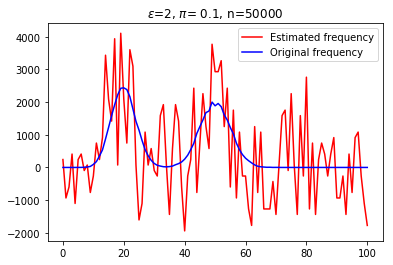
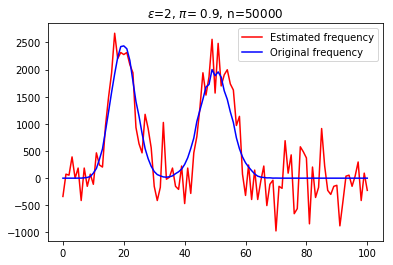
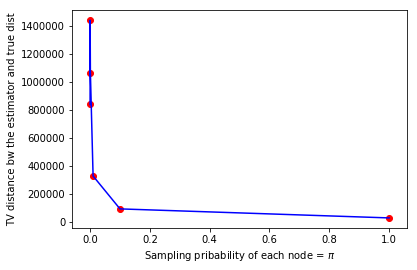
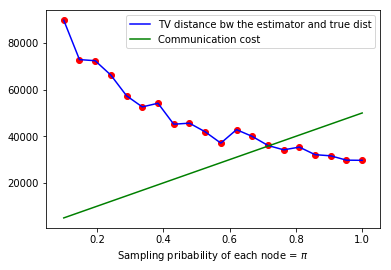
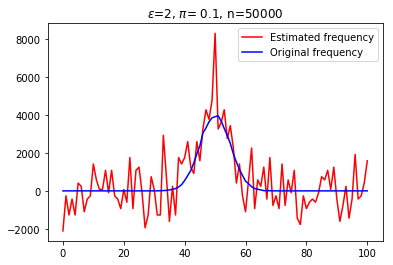
With the recent bloom of data, there is a huge surge in threats against individuals' private information. Various techniques for optimizing privacy-preserving data analysis are at the focus of research in the recent years. In this paper, we analyse the impact of sampling on the utility of the standard techniques of frequency estimation, which is at the core of large-scale data analysis, of the locally deferentially private data-release under a pure protocol. We study the case in a distributed environment of data sharing where the values are reported by various nodes to the central server, e.g., cross-device Federated Learning. We show that if we introduce some random sampling of the nodes in order to reduce the cost of communication, the standard existing estimators fail to remain unbiased. We propose a new unbiased estimator in the context of sampling each node with certain probability and compute various statistical summaries of the data using it. We propose a way of sampling each node with personalized sampling probabilities as a step to further generalisation, which leads to some interesting open questions in the end. We analyse the accuracy of our proposed estimators on synthetic datasets to gather some insight on the trade-off between communication cost, privacy, and utility.
翻译:由于最近数据泛滥,对个人私人信息的威胁急剧增加。近年来研究的重点是优化隐私保护数据分析的各种技术。在本文件中,我们分析取样对频率估计标准技术的效用的影响。 频率估计标准技术是大规模数据分析的核心,而频率估计标准技术是大规模数据分析的核心,是根据纯议定书对当地顺从的私人数据释放的。我们研究数据共享分布式环境的情况,在这种环境中,各种节点将数值报告给中央服务器,例如交叉便利学习。我们表明,如果我们对节点进行一些随机抽样,以减少通信费用,现有标准估计者就无法保持公正。我们提议在对每个节点进行抽样时采用新的不偏袒的估算,以某种可能性对使用的数据进行不同的统计摘要进行计算。我们建议一种方法,对每个节点进行抽样的个化概率取样,作为进一步概括的一个步骤,从而导致一些有趣的公开问题。我们分析了我们提议的关于合成数据保密性、对合成数据的保密性分析的准确性。我们分析了关于合成数据收集的通信的保密性、对合成数据收集的保密性的分析。