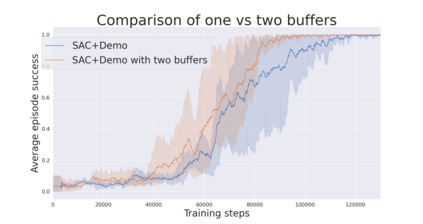
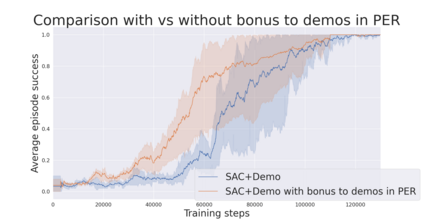
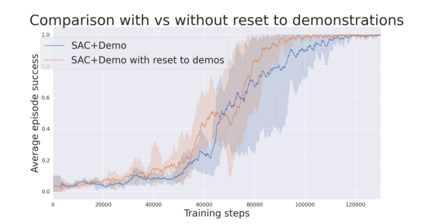
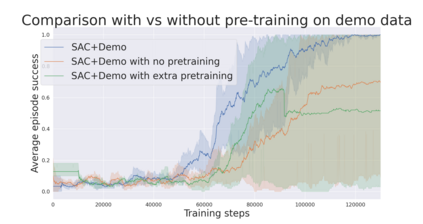
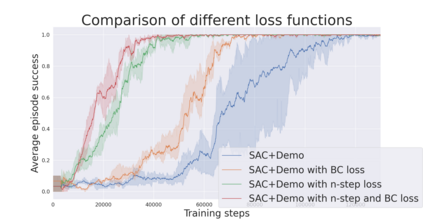
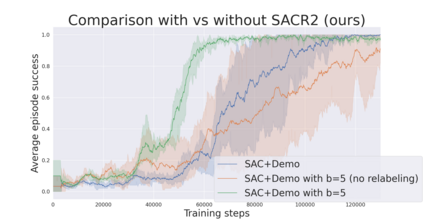
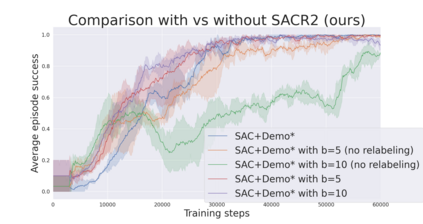
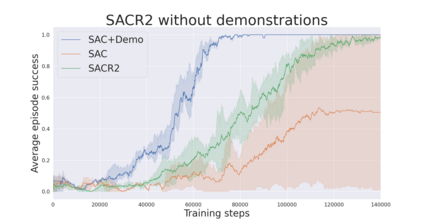
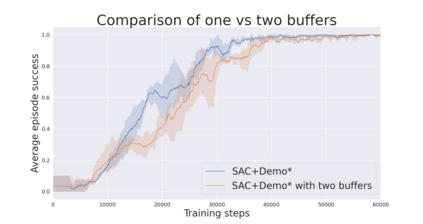
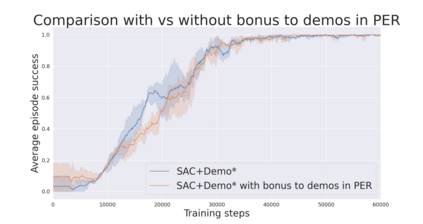
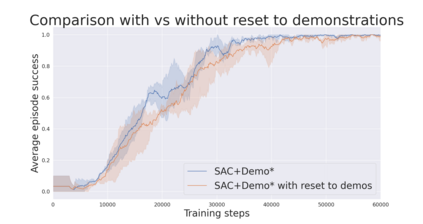
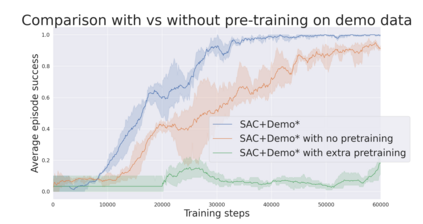
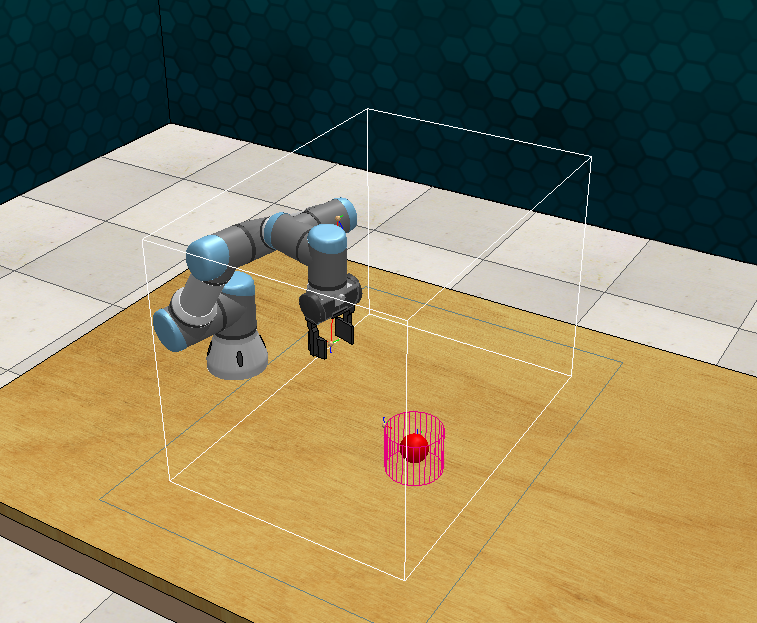
During recent years, deep reinforcement learning (DRL) has made successful incursions into complex decision-making applications such as robotics, autonomous driving or video games. However, a well-known caveat of DRL algorithms is their inefficiency, requiring huge amounts of data to converge. Off-policy algorithms tend to be more sample-efficient, and can additionally benefit from any off-policy data stored in the replay buffer. Expert demonstrations are a popular source for such data: the agent is exposed to successful states and actions early on, which can accelerate the learning process and improve performance. In the past, multiple ideas have been proposed to make good use of the demonstrations in the buffer, such as pretraining on demonstrations only or minimizing additional cost functions. We carry on a study to evaluate several of these ideas in isolation, to see which of them have the most significant impact. We also present a new method, based on a reward bonus given to demonstrations and successful episodes. First, we give a reward bonus to the transitions coming from demonstrations to encourage the agent to match the demonstrated behaviour. Then, upon collecting a successful episode, we relabel its transitions with the same bonus before adding them to the replay buffer, encouraging the agent to also match its previous successes. The base algorithm for our experiments is the popular Soft Actor-Critic (SAC), a state-of-the-art off-policy algorithm for continuous action spaces. Our experiments focus on robotics, specifically on a reaching task for a robotic arm in simulation. We show that our method SACR2 based on reward relabeling improves the performance on this task, even in the absence of demonstrations.
翻译:近些年来,深层强化学习(DRL)成功地侵入了复杂的决策应用程序,如机器人、自主驾驶或视频游戏等。然而,众所周知的DRL算法的警告是效率低,需要大量的数据才能汇集。非政策算法往往更具抽样效率,并且能够从重播缓冲中储存的任何非政策数据中得到更多好处。专家演示是这类数据的一个流行来源:代理商暴露于成功的州和行动,从而可以加速学习过程和改善业绩。过去,人们曾提出多种想法,以便很好地利用缓冲演示,例如仅对演示进行预培训,或尽量减少额外的成本功能。我们正在进行一项研究,对其中的一些想法进行孤立评估,看看其中哪些想法具有最显著的影响。我们还根据对演示和成功事件给予的奖励奖金,提出了一种新的方法。首先,我们奖励从演示到鼓励代理商与所展示的行为相匹配的转变。随后,在收集成功插图时,我们甚至将其在演示前期演示前的过渡与预示器的过渡标注,然后又将我们之前的试算法的试算法作为我们的试算的基础。我们之前的试算的试算,让我们的试算的试算,让我们的试算法的试算的试算法,让我们的试算,让我们的试算的试算法的试算的试算。