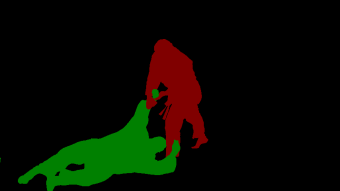
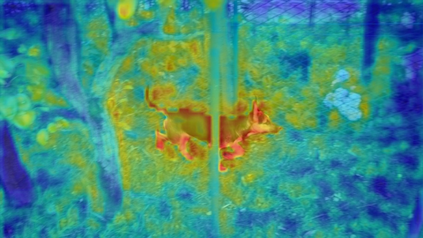
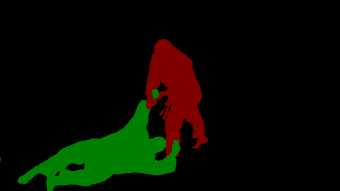
Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the 'cross-attention' operation, which allows a vector representation (e.g. of an object in an image) to be learned by attending to an arbitrarily sized set of input features. Recently, "Masked Attention" was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over `soft-masks' (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our "Differentiable Soft-Masked Attention" for the task of Weakly-Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation. Code: https://github.com/Ali2500/HODOR/blob/main/hodor/modelling/encoder/soft_masked_attention.py
翻译:计算机图像变异器由于在模拟复杂操作中的性能和灵活性而成为计算机视觉中的流行。 特别重要的是, “ 交叉注意” 操作, 允许通过任意大小的输入功能来学习矢量代表( 图像中的物体) 。 最近, “ 吸引注意” 提议, 特定对象代表只关注该对象的分解面罩正在运行的那些图像像素特性。 这种关注的专业化对于各种图像和视频分割任务十分有益。 在本文中, 我们提议了另一种关注的专业化, 使得能够参加“ 软质( 连续遮罩比值而不是二进制值的物体), 并且通过这些掩码的特性来学习矢量代表( 图像中的物体) 。 用于在网络中学习注意的面具, 不需要直接损失监督。 具体地说, 我们使用“ 差异性软质250 关注” 来完成 Weakly- Supervis Vocal 面板块的任务。 我们在此过程中开发一个变压/ 常规网络, 但也需要一种稳定的系统框架, 。 这些变压/ 格式的网络需要一种单一的标签框架, 的系统框架, 需要一种不易变压/ 。