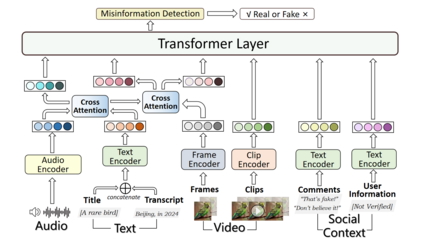
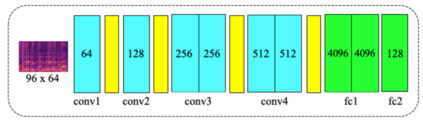
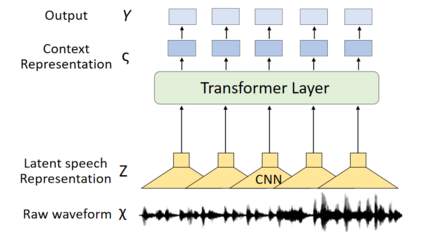
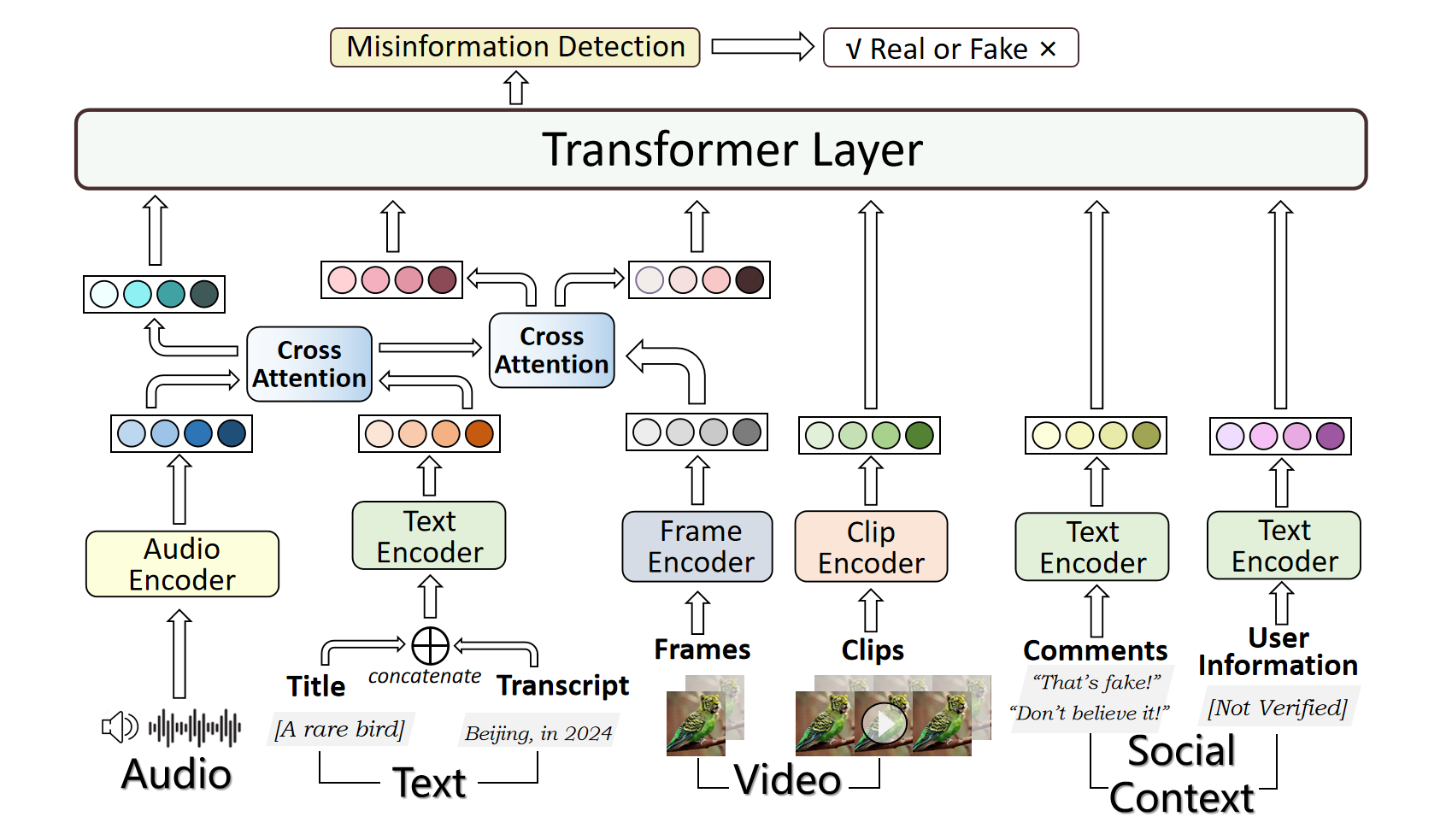
With the rapid development of deepfake technology, especially the deep audio fake technology, misinformation detection on the social media scene meets a great challenge. Social media data often contains multimodal information which includes audio, video, text, and images. However, existing multimodal misinformation detection methods tend to focus only on some of these modalities, failing to comprehensively address information from all modalities. To comprehensively address the various modal information that may appear on social media, this paper constructs a comprehensive multimodal misinformation detection framework. By employing corresponding neural network encoders for each modality, the framework can fuse different modality information and support the multimodal misinformation detection task. Based on the constructed framework, this paper explores the importance of the audio modality in multimodal misinformation detection tasks on social media. By adjusting the architecture of the acoustic encoder, the effectiveness of different acoustic feature encoders in the multimodal misinformation detection tasks is investigated. Furthermore, this paper discovers that audio and video information must be carefully aligned, otherwise the misalignment across different audio and video modalities can severely impair the model performance.
翻译:暂无翻译