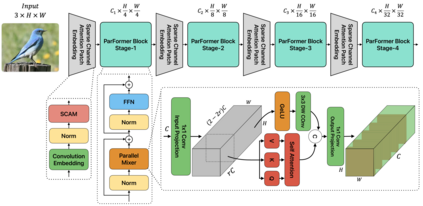
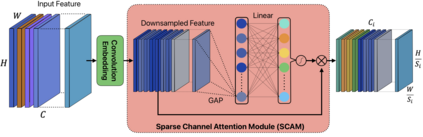
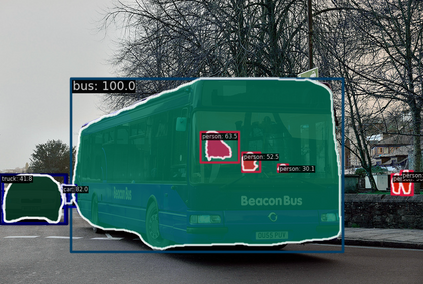
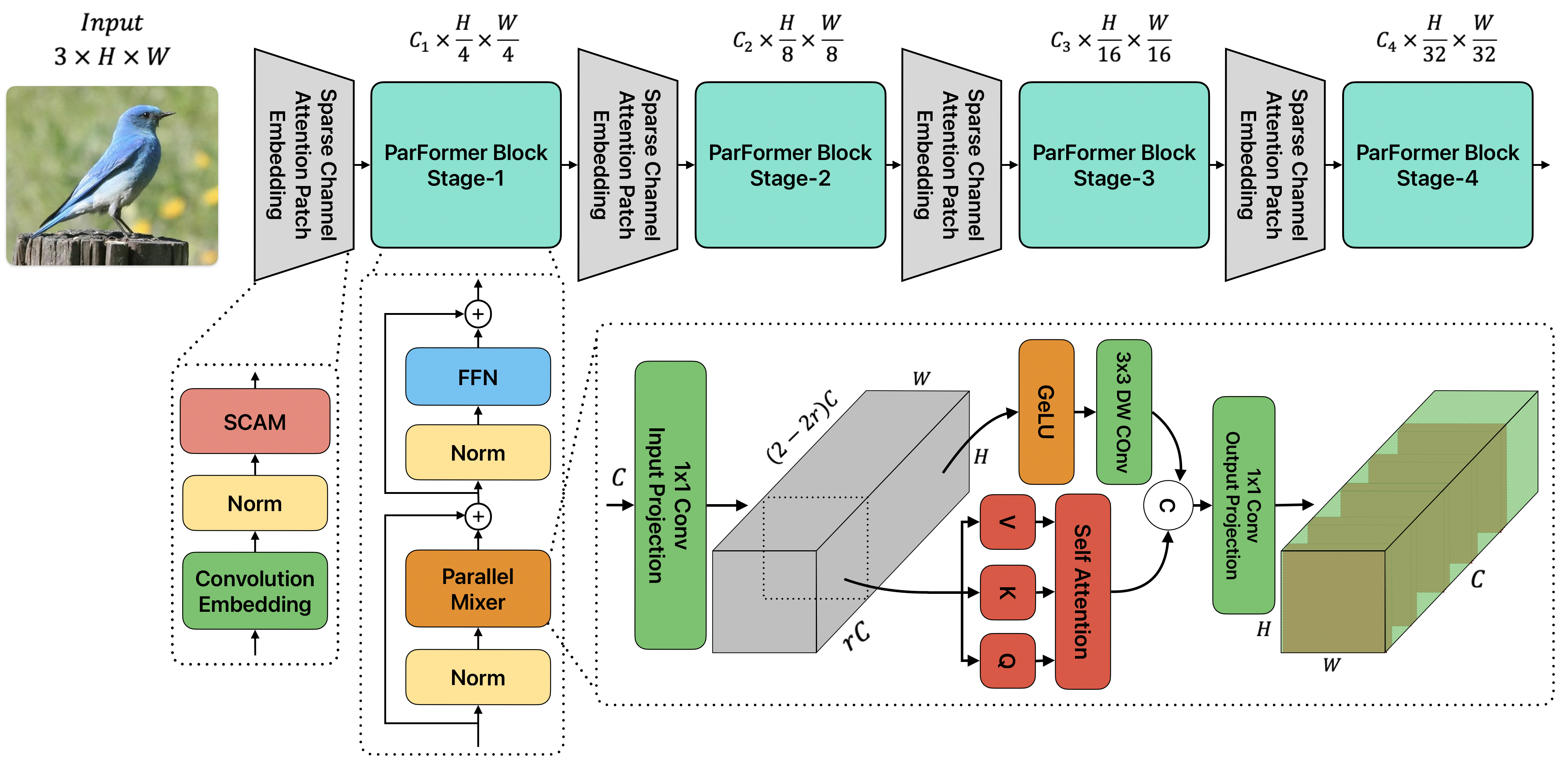
Convolutional Neural Networks (CNNs) and Transformers have achieved remarkable success in computer vision tasks. However, their deep architectures often lead to high computational redundancy, making them less suitable for resource-constrained environments, such as edge devices. This paper introduces ParFormer, a novel vision transformer that addresses this challenge by incorporating a Parallel Mixer and a Sparse Channel Attention Patch Embedding (SCAPE). By combining convolutional and attention mechanisms, ParFormer improves feature extraction. This makes spatial feature extraction more efficient and cuts down on unnecessary computation. The SCAPE module further reduces computational redundancy while preserving essential feature information during down-sampling. Experimental results on the ImageNet-1K dataset show that ParFormer-T achieves 78.9\% Top-1 accuracy with a high throughput on a GPU that outperforms other small models with 2.56$\times$ higher throughput than MobileViT-S, 0.24\% faster than FasterNet-T2, and 1.79$\times$ higher than EdgeNeXt-S. For edge device deployment, ParFormer-T excels with a throughput of 278.1 images/sec, which is 1.38 $\times$ higher than EdgeNeXt-S and 2.36$\times$ higher than MobileViT-S, making it highly suitable for real-time applications in resource-constrained settings. The larger variant, ParFormer-L, reaches 83.5\% Top-1 accuracy, offering a balanced trade-off between accuracy and efficiency, surpassing many state-of-the-art models. In COCO object detection, ParFormer-M achieves 40.7 AP for object detection and 37.6 AP for instance segmentation, surpassing models like ResNet-50, PVT-S and PoolFormer-S24 with significantly higher efficiency. These results validate ParFormer as a highly efficient and scalable model for both high-performance and resource-constrained scenarios, making it an ideal solution for edge-based AI applications.
翻译:暂无翻译