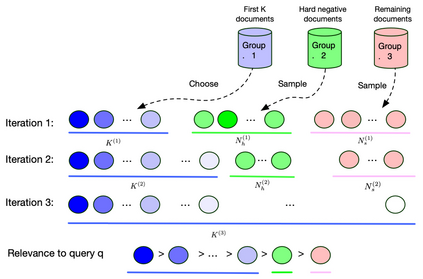
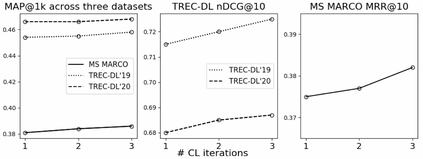
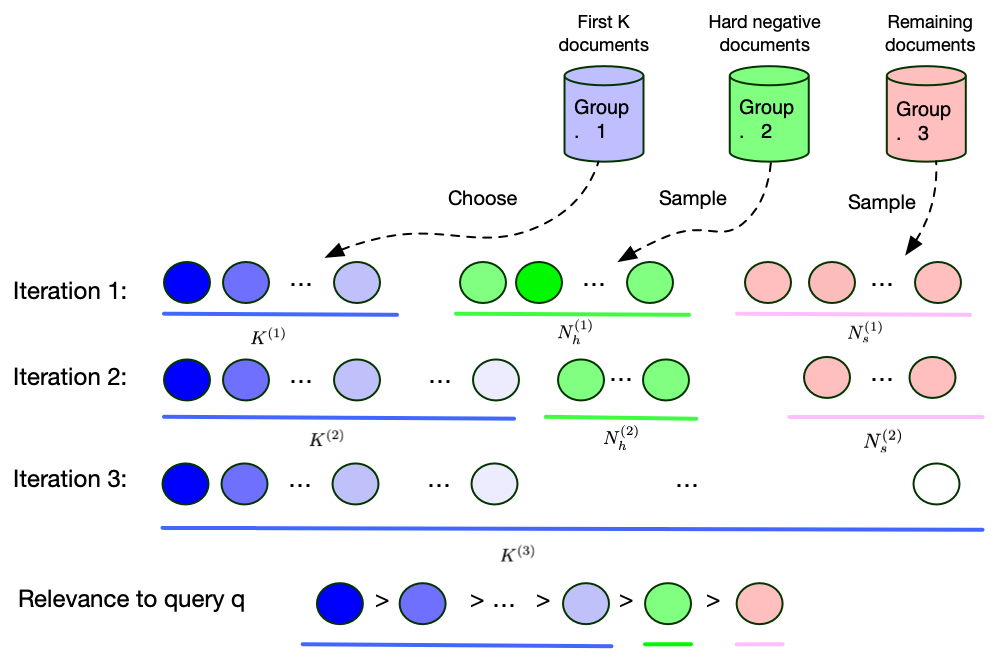
Recent work has shown that more effective dense retrieval models can be obtained by distilling ranking knowledge from an existing base re-ranking model. In this paper, we propose a generic curriculum learning based optimization framework called CL-DRD that controls the difficulty level of training data produced by the re-ranking (teacher) model. CL-DRD iteratively optimizes the dense retrieval (student) model by increasing the difficulty of the knowledge distillation data made available to it. In more detail, we initially provide the student model coarse-grained preference pairs between documents in the teacher's ranking and progressively move towards finer-grained pairwise document ordering requirements. In our experiments, we apply a simple implementation of the CL-DRD framework to enhance two state-of-the-art dense retrieval models. Experiments on three public passage retrieval datasets demonstrate the effectiveness of our proposed framework.
翻译:最近的工作表明,通过从现有的基准重新排序模型中提取知识,可以取得更有效的密集检索模型。在本文中,我们提议了一个以通用课程学习为基础的优化框架,称为CL-DRD,以控制重新排序(教师)模型产生的培训数据难度。CL-DRD通过增加提供给它的知识提炼数据难度,迭代优化密集检索(学生)模型。更详细地说,我们最初提供学生模型,即教师排名中的文件之间粗糙的偏好配对,并逐步转向精细的双向文件订购要求。在我们的实验中,我们采用简单实施CL-DRD框架来加强两种最先进的密集检索模型。在三个公共通道检索数据集上进行的实验显示了我们提议的框架的有效性。