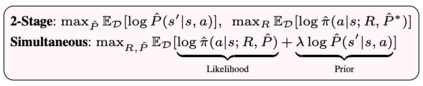
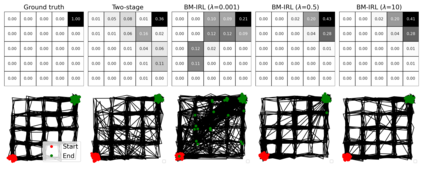
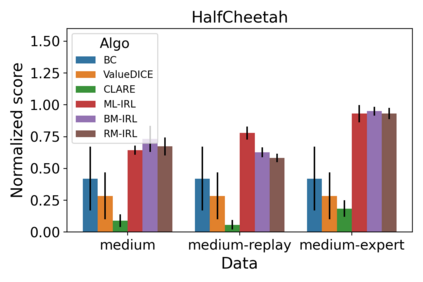
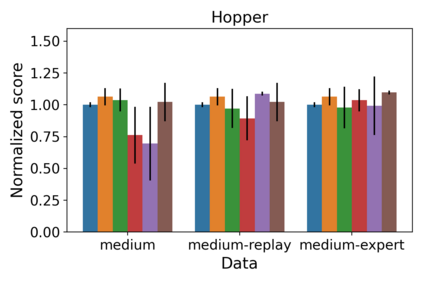
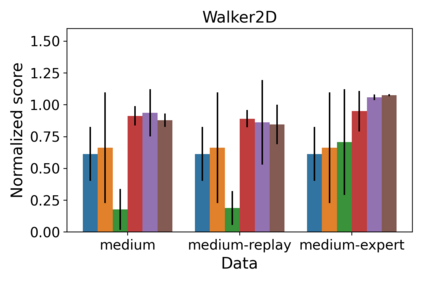
We consider a Bayesian approach to offline model-based inverse reinforcement learning (IRL). The proposed framework differs from existing offline model-based IRL approaches by performing simultaneous estimation of the expert's reward function and subjective model of environment dynamics. We make use of a class of prior distributions which parameterizes how accurate the expert's model of the environment is to develop efficient algorithms to estimate the expert's reward and subjective dynamics in high-dimensional settings. Our analysis reveals a novel insight that the estimated policy exhibits robust performance when the expert is believed (a priori) to have a highly accurate model of the environment. We verify this observation in the MuJoCo environments and show that our algorithms outperform state-of-the-art offline IRL algorithms.
翻译:暂无翻译