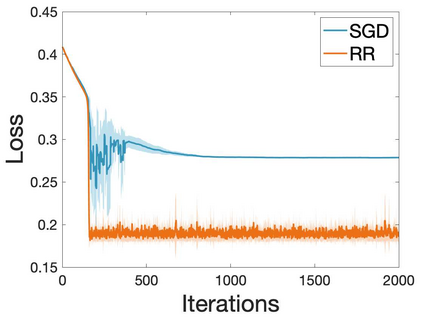
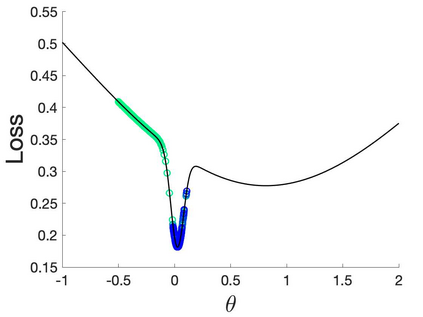
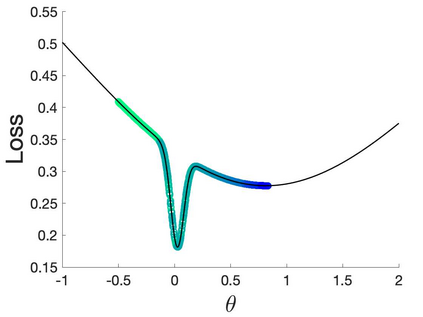
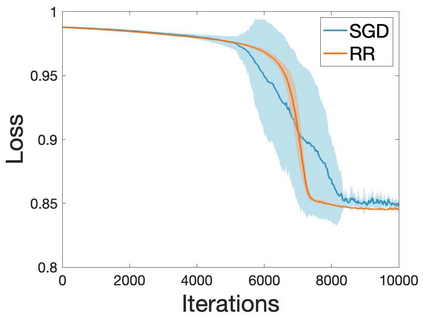
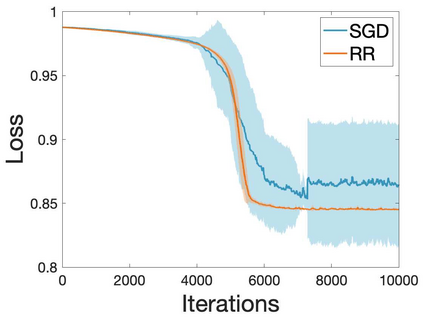
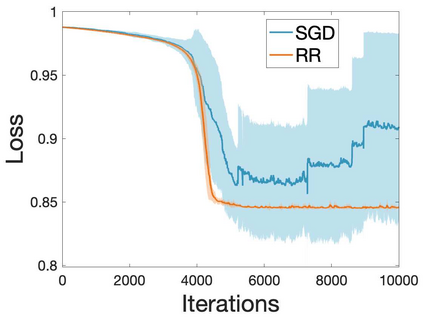
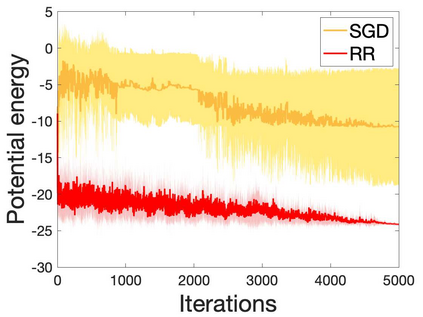
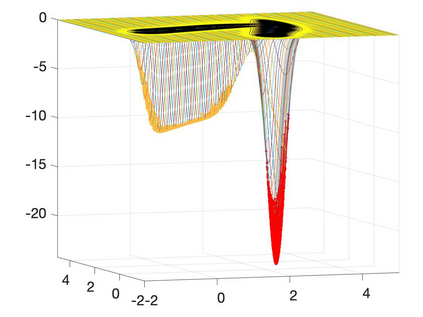
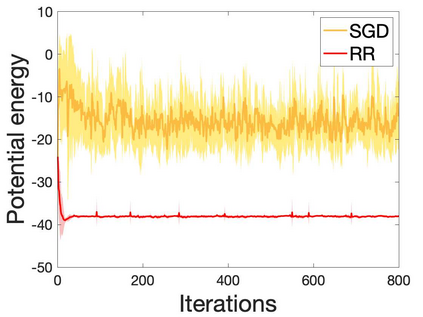
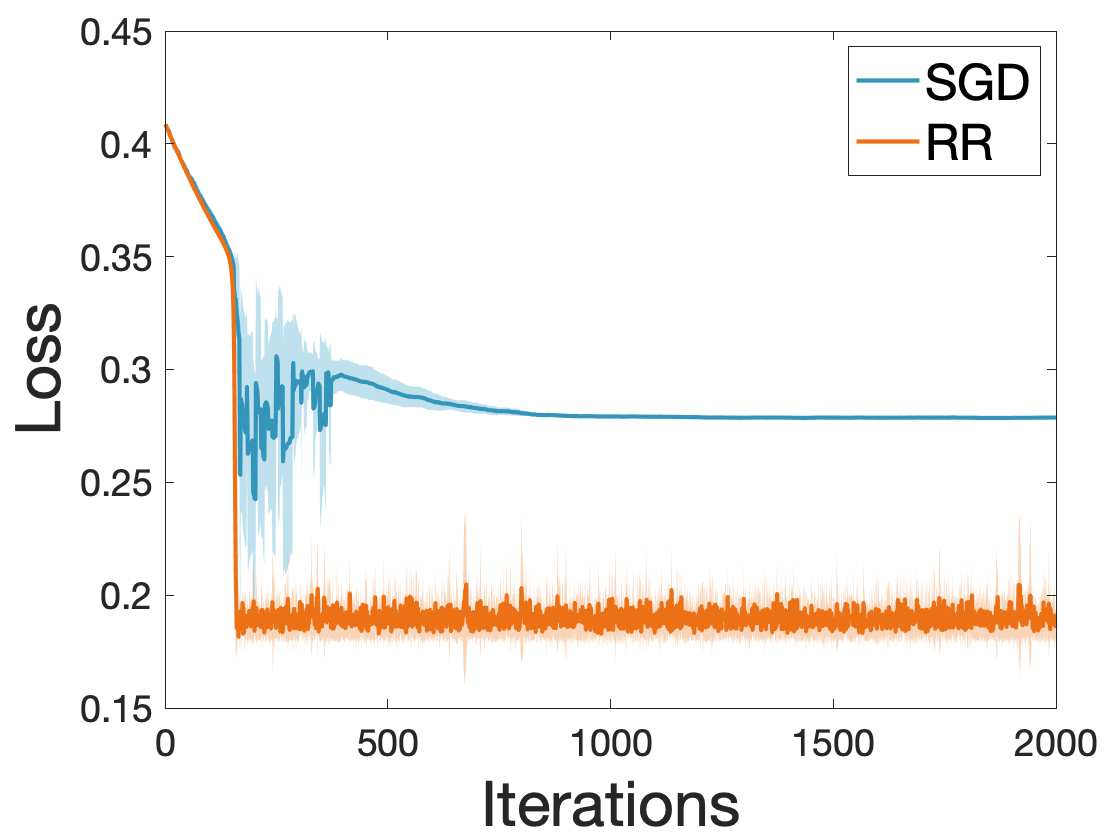
Many machine learning and data science tasks require solving non-convex optimization problems. When the loss function is a sum of multiple terms, a popular method is the stochastic gradient descent. Viewed as a process for sampling the loss function landscape, the stochastic gradient descent is known to prefer flat minima. Though this is desired for certain optimization problems such as in deep learning, it causes issues when the goal is to find the global minimum, especially if the global minimum resides in a sharp valley. Illustrated with a simple motivating example, we show that the fundamental reason is that the difference in the Lipschitz constants of multiple terms in the loss function causes stochastic gradient descent to experience different variances at different minima. In order to mitigate this effect and perform faithful optimization, we propose a combined resampling-reweighting scheme to balance the variance at local minima and extend to general loss functions. We explain from the numerical stability perspective how the proposed scheme is more likely to select the true global minimum, and the local convergence analysis perspective how it converges to a minimum faster when compared with the vanilla stochastic gradient descent. Experiments from robust statistics and computational chemistry are provided to demonstrate the theoretical findings.
翻译:许多机器学习和数据科学任务都需要解决非convex优化问题。 当损失函数是多个条件的总和时, 一个流行的方法是随机梯度下降。 被视为对损失函数景观进行抽样的过程, 随机梯度下降被认为是平坦的迷你。 虽然这是某些优化问题( 如深层学习)所希望的, 但当目标是找到全球最低值时, 特别是当全球最低值位于一个尖锐的山谷时, 它会产生问题。 以简单的激励示例为例, 我们显示, 根本原因是, Lipschitz 常数在损失函数中存在多种条件的差异, 导致随机梯度下降在不同迷你间出现差异。 为了减轻这一影响, 并实现忠实的优化, 我们提议了一个综合的重新加权办法, 以平衡本地最低值的差异, 并扩展到一般的损失函数。 我们从数字稳定性角度来解释, 拟议的计划如何更可能选择真正的全球最低值, 并且本地趋同分析如何在与 Vanilla 的梯度梯度梯度梯度下降相比, 将它集中到最小的最小化为最小值。 实验从稳健的统计到显示。