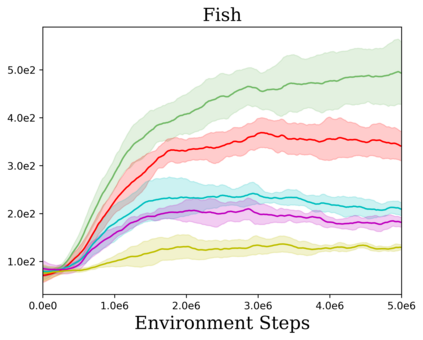
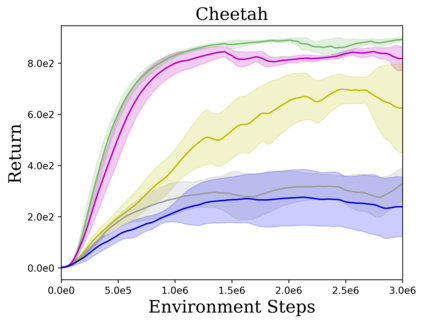
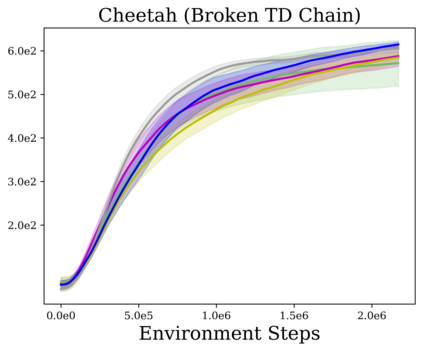
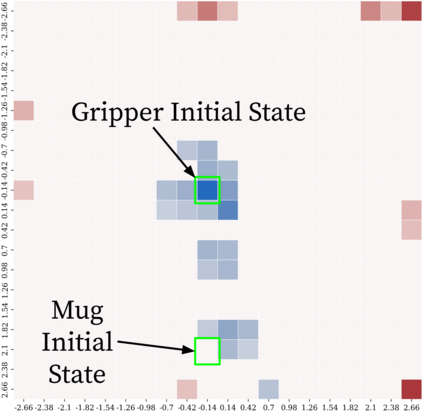
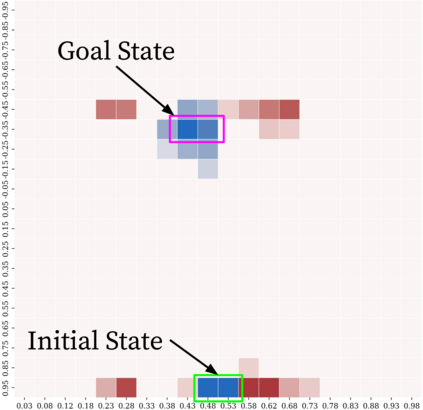
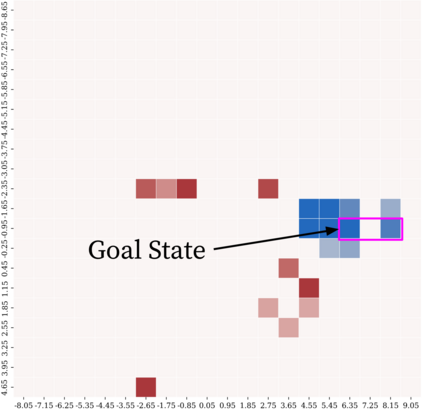
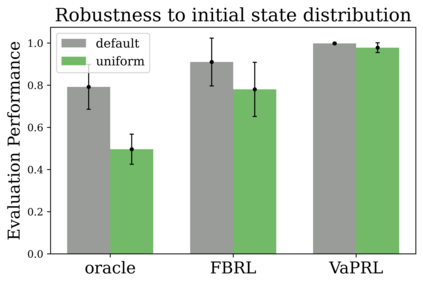
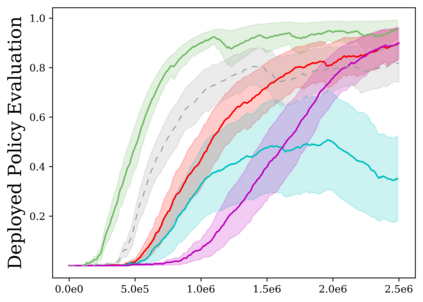
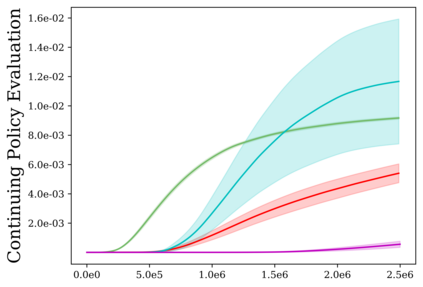
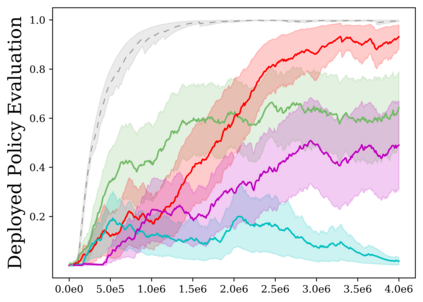
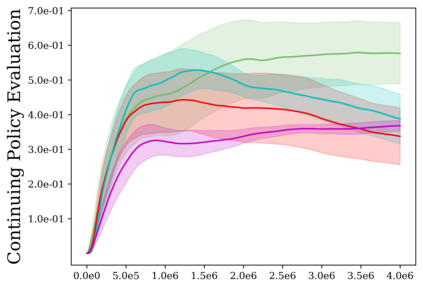
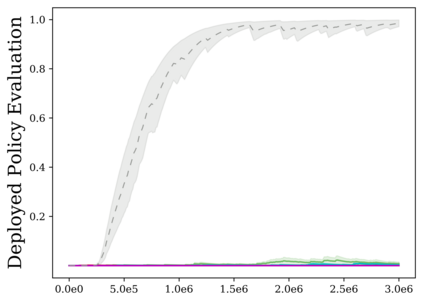
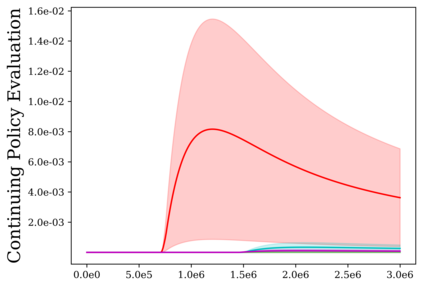
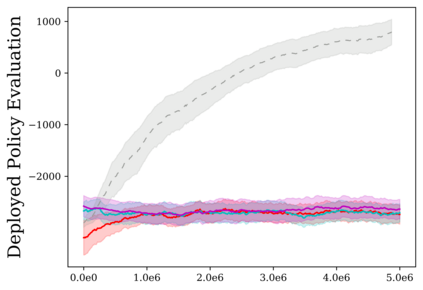
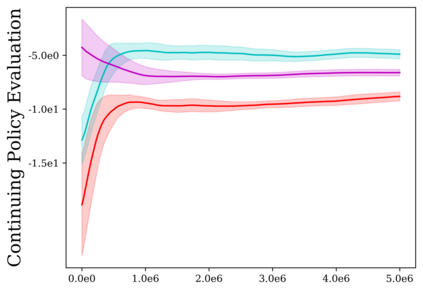
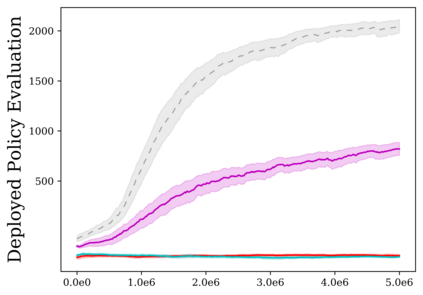
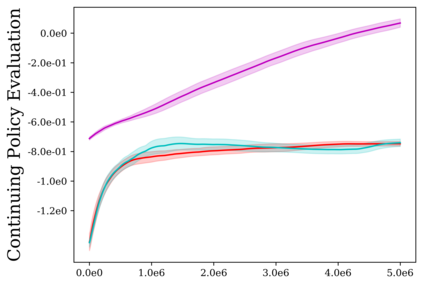
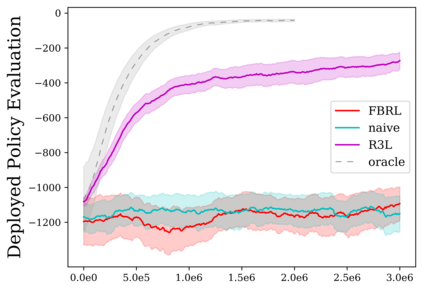
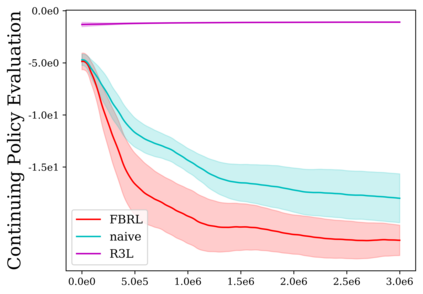
Reinforcement learning (RL) provides a naturalistic framing for learning through trial and error, which is appealing both because of its simplicity and effectiveness and because of its resemblance to how humans and animals acquire skills through experience. However, real-world embodied learning, such as that performed by humans and animals, is situated in a continual, non-episodic world, whereas common benchmark tasks in RL are episodic, with the environment resetting between trials to provide the agent with multiple attempts. This discrepancy presents a major challenge when attempting to take RL algorithms developed for episodic simulated environments and run them on real-world platforms, such as robots. In this paper, we aim to address this discrepancy by laying out a framework for Autonomous Reinforcement Learning (ARL): reinforcement learning where the agent not only learns through its own experience, but also contends with lack of human supervision to reset between trials. We introduce a simulated benchmark EARL around this framework, containing a set of diverse and challenging simulated tasks reflective of the hurdles introduced to learning when only a minimal reliance on extrinsic intervention can be assumed. We show that standard approaches to episodic RL and existing approaches struggle as interventions are minimized, underscoring the need for developing new algorithms for reinforcement learning with a greater focus on autonomy.
翻译:强化学习(RL)为通过试验和错误进行学习提供了一个自然的自然框架,这既因为它简单又有效,又因为它与人类和动物如何通过经验获得技能相似,因此具有吸引力。然而,现实世界所体现的学习,例如人类和动物的学习,位于一个持续、非分裂的世界,而实验室的共同基准任务是零星的,而试验之间的环境重新设置,以便为代理提供多种尝试。这种差异在试图采用为模拟的硬性模拟环境开发的RL算法并在机器人等现实世界平台上运行这些算法时是一个重大挑战。在本文件中,我们旨在通过建立一个自主强化学习的框架,例如人类和动物的学习;加强学习,因为代理人不仅通过自己的经验学习,而且还认为在两次试验之间缺乏人的监督。我们在这个框架周围引入了模拟的EARL基准,其中含有一套多样化和具有挑战性的模拟任务,反映了在仅对极限干预(如机器人)依赖最小程度时学习时引入的障碍。我们的目标是消除这种差异。我们在本文中,通过建立自主强化现有标准方法,以学习更高的自主性研究重点。