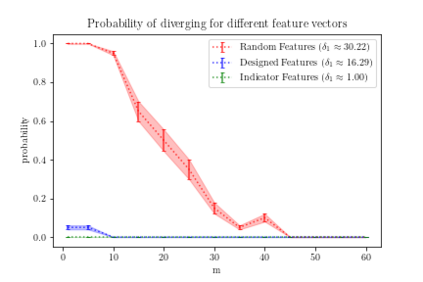
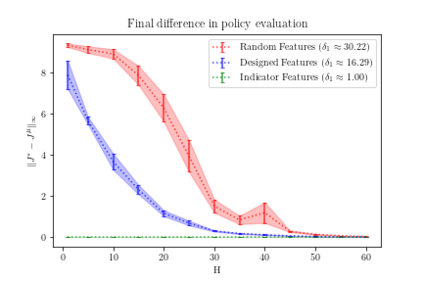
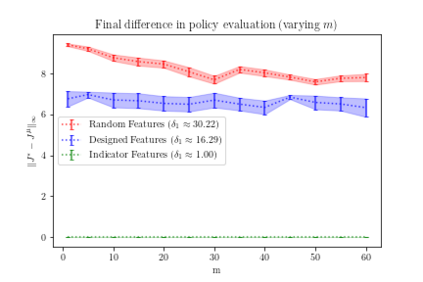
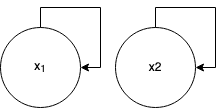
Reinforcement learning uses a number of techniques to learn a near-optimal optimal policy for very large MDPs by approximately solving the dynamic programming problem, including lookahead, approximate policy evaluation using an m-step return, function approximation, and gradient descent. In a recent paper, (Efroni et al. 2019) studied the impact of lookahead on the convergence rate of approximate dynamic programming. In this paper, we show that these convergence results change dramatically when function approximation is used in conjunction with lookahead and approximate policy evaluation using an m-step return. Specifically, we show that when linear function approximation is used to represent the value function, a certain minimum amount of lookahead and multi-step return is needed for the algorithm to even converge. And when this condition is met, we characterize the performance of policies obtained using such approximate policy iteration.
翻译:强化学习使用一些技术,为大型多功能DP学习近乎最佳的政策,通过大致解决动态的方案编制问题,包括外观、使用微步返回的近似政策评价、功能近似和梯度下降。在最近的一篇论文中(Efroni等人,2019年)研究了外观对近似动态方案编制趋同率的影响。在本文中,我们表明,当功能近似与外观结合使用时,以及使用微步返回的近似政策评价时,这些趋同结果发生了巨大变化。具体地说,我们表明,当使用线性功能代表价值函数时,需要一定数量的外观和多步返回才能使算法趋同。如果满足这一条件,我们用这种近似的政策重复来描述政策的执行情况。