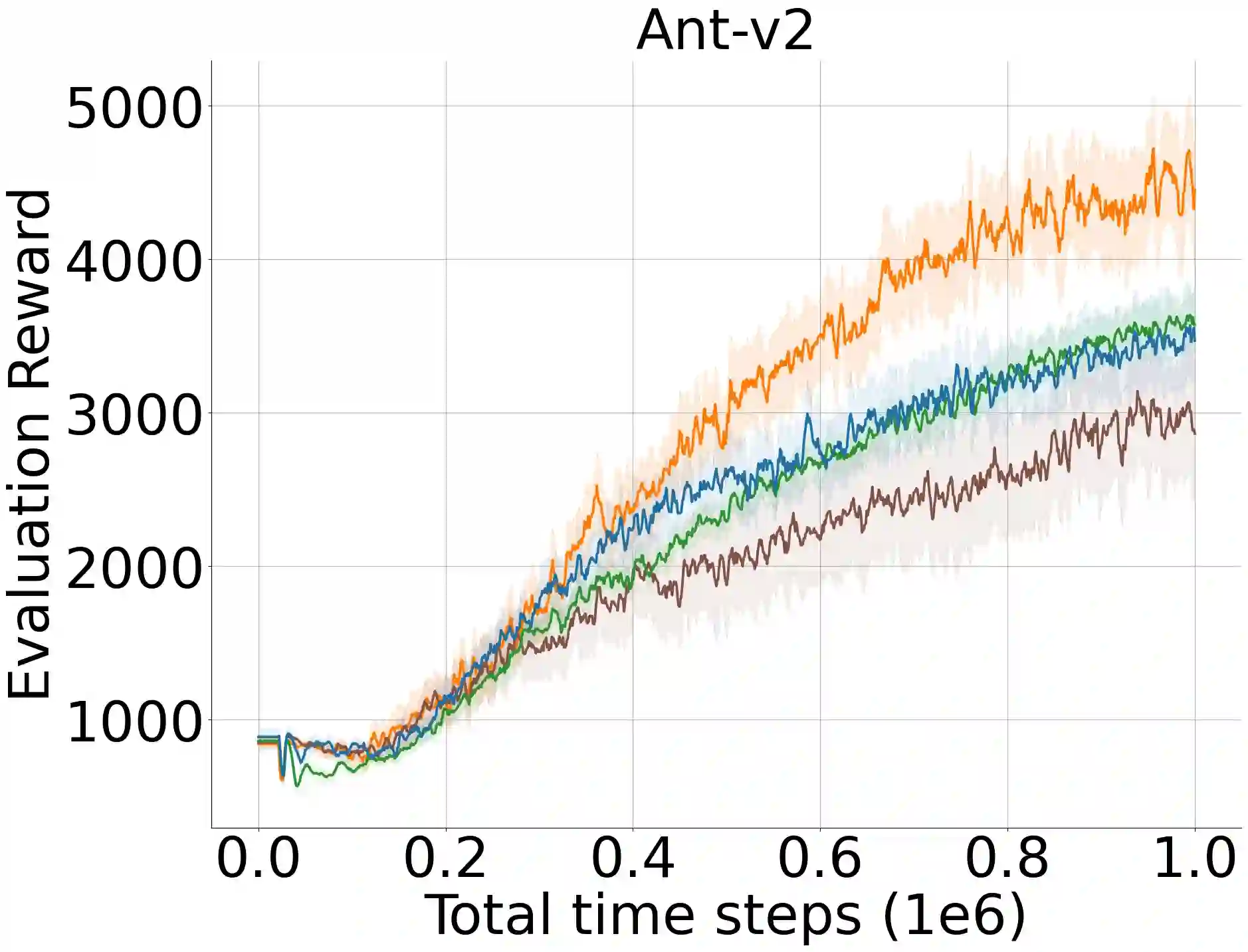
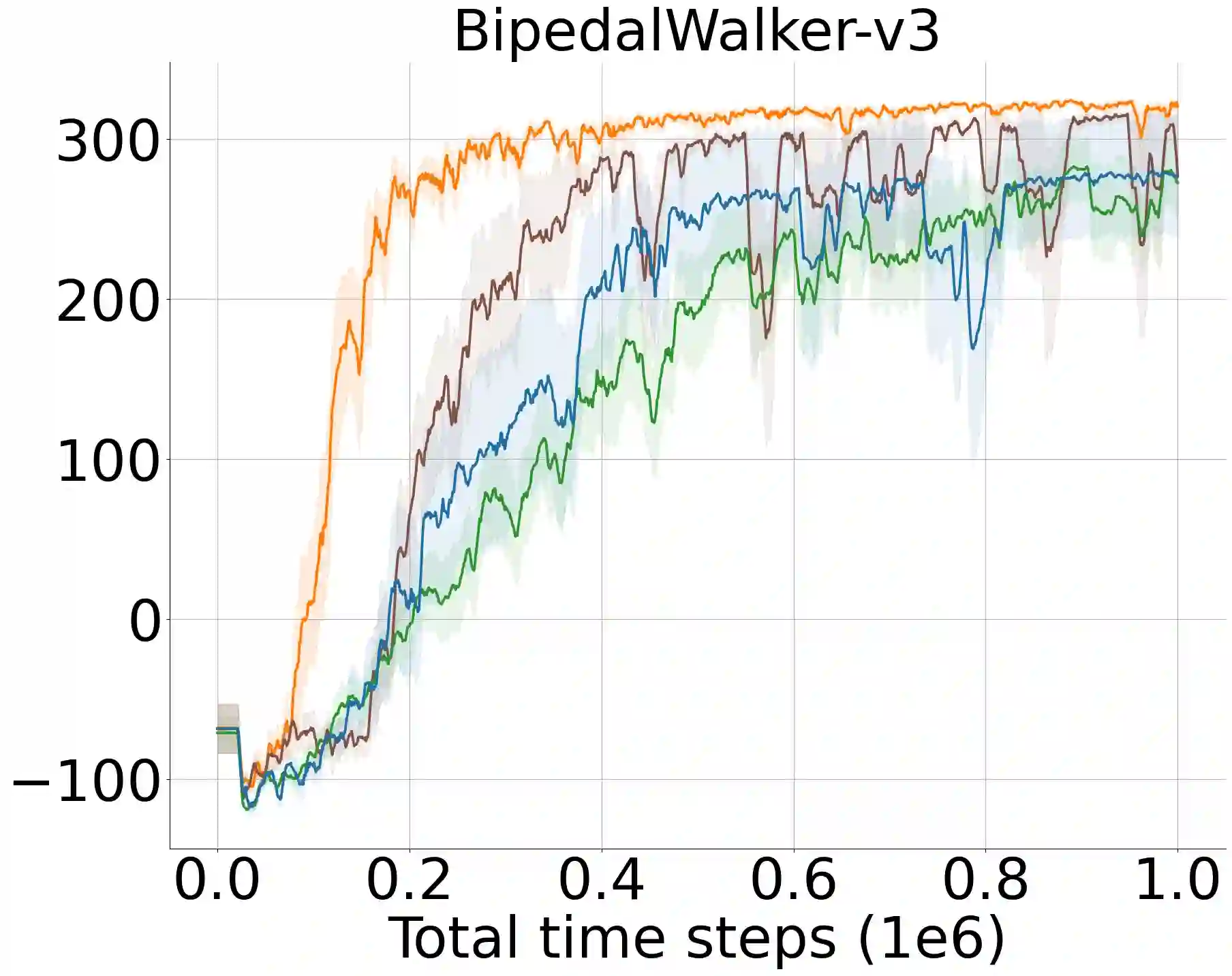
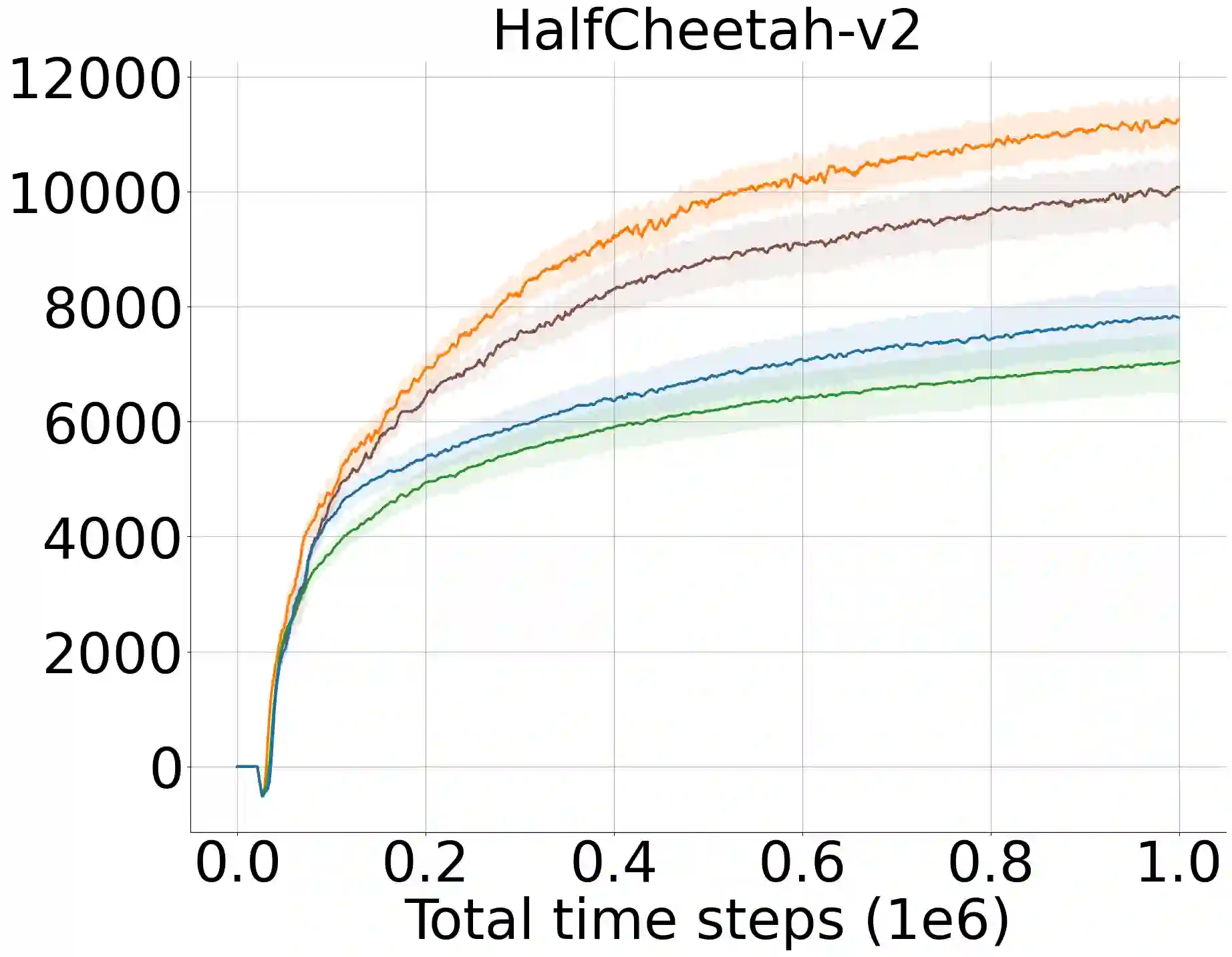
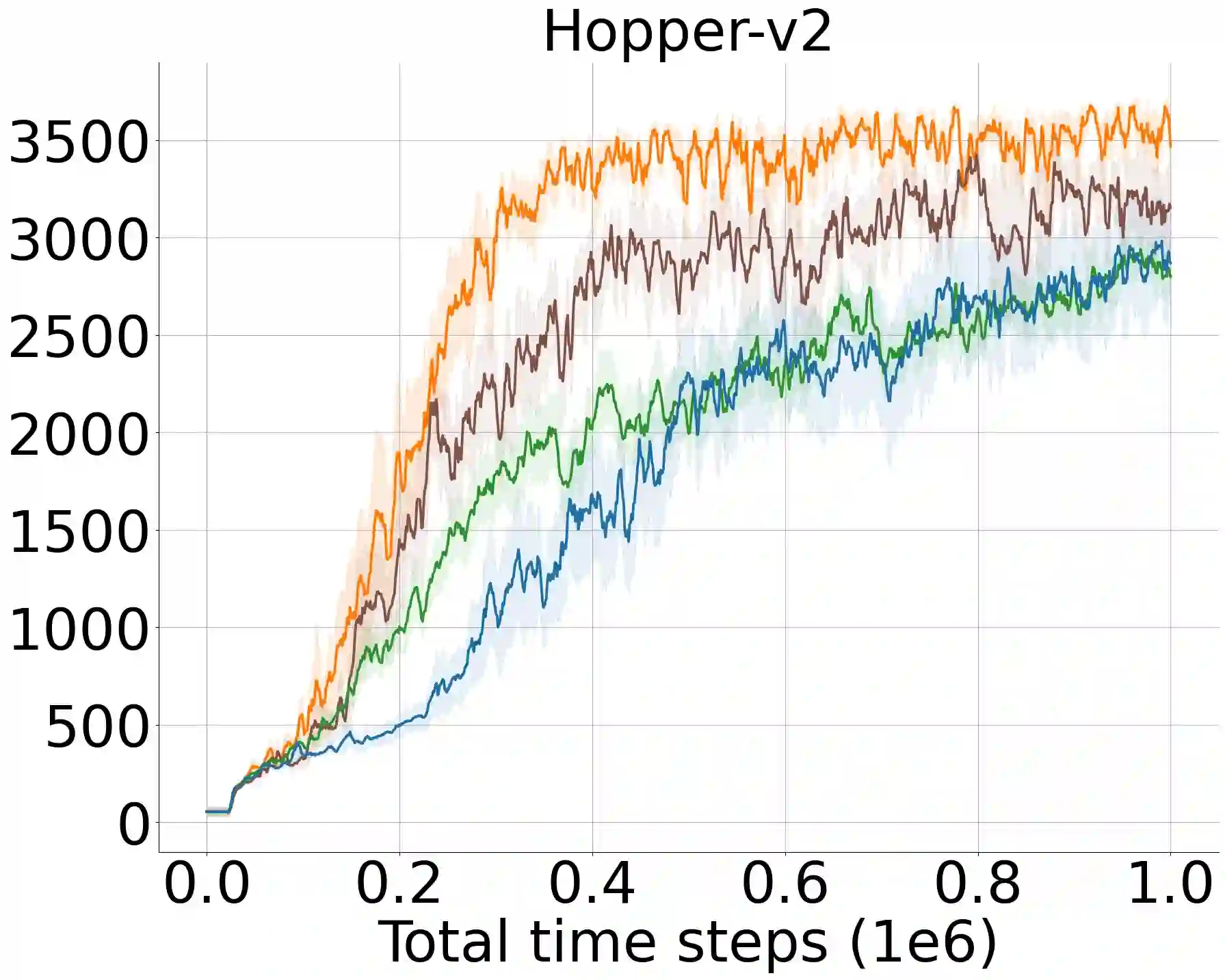
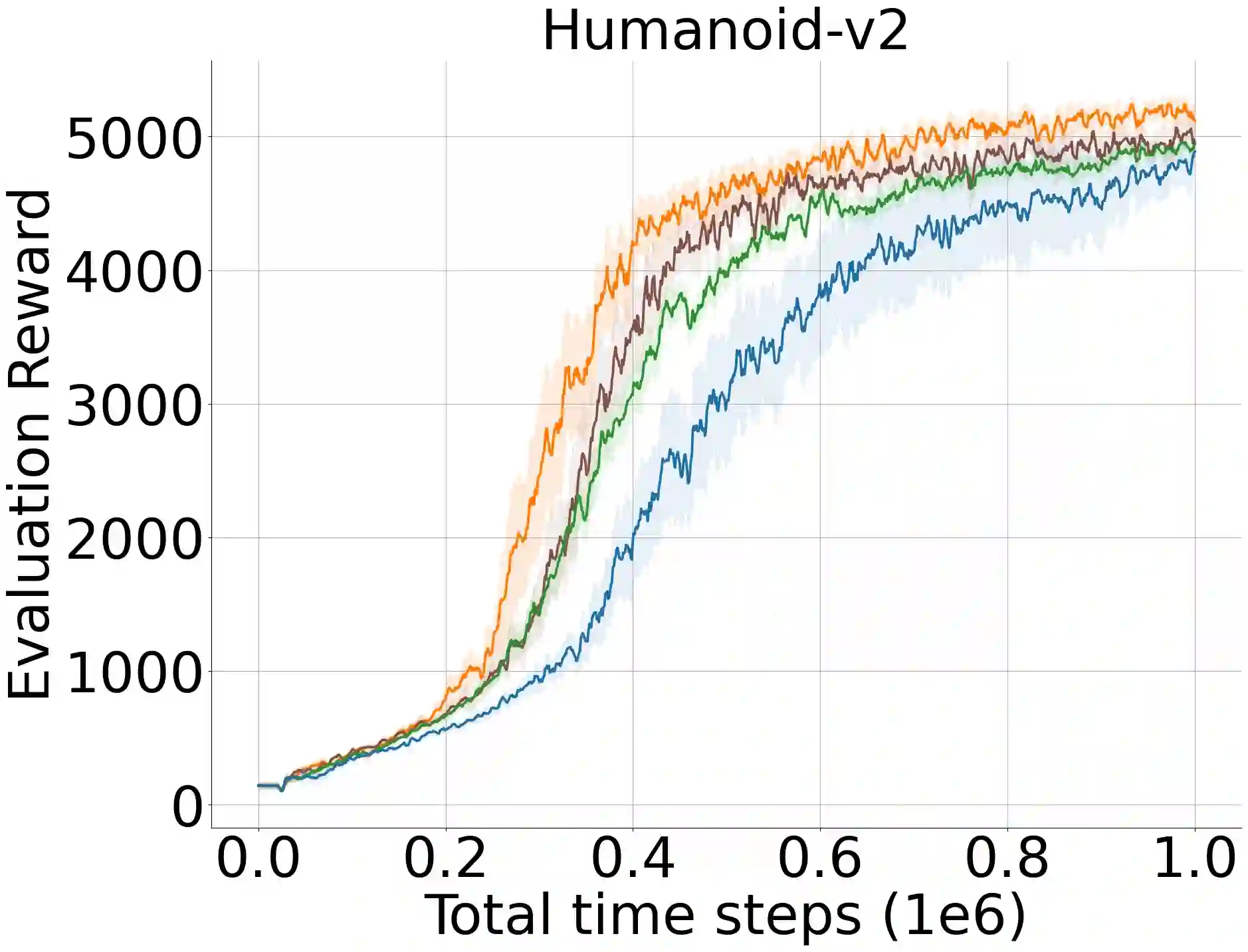
A widely-studied deep reinforcement learning (RL) technique known as Prioritized Experience Replay (PER) allows agents to learn from transitions sampled with non-uniform probability proportional to their temporal-difference (TD) error. Although it has been shown that PER is one of the most crucial components for the overall performance of deep RL methods in discrete action domains, many empirical studies indicate that it considerably underperforms actor-critic algorithms in continuous control. We theoretically show that actor networks cannot be effectively trained with transitions that have large TD errors. As a result, the approximate policy gradient computed under the Q-network diverges from the actual gradient computed under the optimal Q-function. Motivated by this, we introduce a novel experience replay sampling framework for actor-critic methods, which also regards issues with stability and recent findings behind the poor empirical performance of PER. The introduced algorithm suggests a new branch of improvements to PER and schedules effective and efficient training for both actor and critic networks. An extensive set of experiments verifies our theoretical claims and demonstrates that the introduced method significantly outperforms the competing approaches and obtains state-of-the-art results over the standard off-policy actor-critic algorithms.
翻译:广泛研究的深入强化学习(RL)技术,称为优先经验回放(PER),使代理商能够从与其时间差异(TD)错误成正比的非统一概率抽样的过渡中学习。虽然已经表明,PER是分立行动领域深层次RL方法总体性能的最关键组成部分之一,但许多实证研究表明,它在连续控制中大大低于行为者-批评算法的性能;我们理论上表明,行为体网络无法在过渡中有效培训,而过渡存在巨大的TD错误。因此,在Q-网络下计算的政策梯度与在最佳Q功能下计算的实际梯度相差很大。我们受此驱动,为行为者-批评方法引入了一个全新的重放取样框架,其中也涉及稳定性问题和最近发现PER业绩不佳的原因。引入的算法表明,对PER进行新的改进,并安排对行为者和评论网络进行有效和高效的培训。广泛的实验证实了我们的理论主张,并表明,采用的方法大大超越了相互竞争的方法,并获取了标准的行为者-演算法结果。