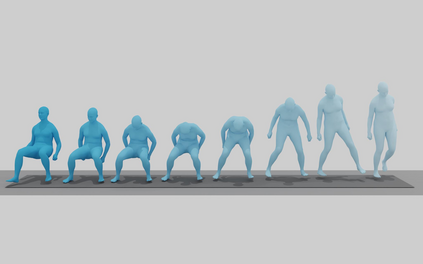This paper introduces OmniMotion-X, a versatile multimodal framework for whole-body human motion generation, leveraging an autoregressive diffusion transformer in a unified sequence-to-sequence manner. OmniMotion-X efficiently supports diverse multimodal tasks, including text-to-motion, music-to-dance, speech-to-gesture, and global spatial-temporal control scenarios (e.g., motion prediction, in-betweening, completion, and joint/trajectory-guided synthesis), as well as flexible combinations of these tasks. Specifically, we propose the use of reference motion as a novel conditioning signal, substantially enhancing the consistency of generated content, style, and temporal dynamics crucial for realistic animations. To handle multimodal conflicts, we introduce a progressive weak-to-strong mixed-condition training strategy. To enable high-quality multimodal training, we construct OmniMoCap-X, the largest unified multimodal motion dataset to date, integrating 28 publicly available MoCap sources across 10 distinct tasks, standardized to the SMPL-X format at 30 fps. To ensure detailed and consistent annotations, we render sequences into videos and use GPT-4o to automatically generate structured and hierarchical captions, capturing both low-level actions and high-level semantics. Extensive experimental evaluations confirm that OmniMotion-X significantly surpasses existing methods, demonstrating state-of-the-art performance across multiple multimodal tasks and enabling the interactive generation of realistic, coherent, and controllable long-duration motions.
翻译:暂无翻译