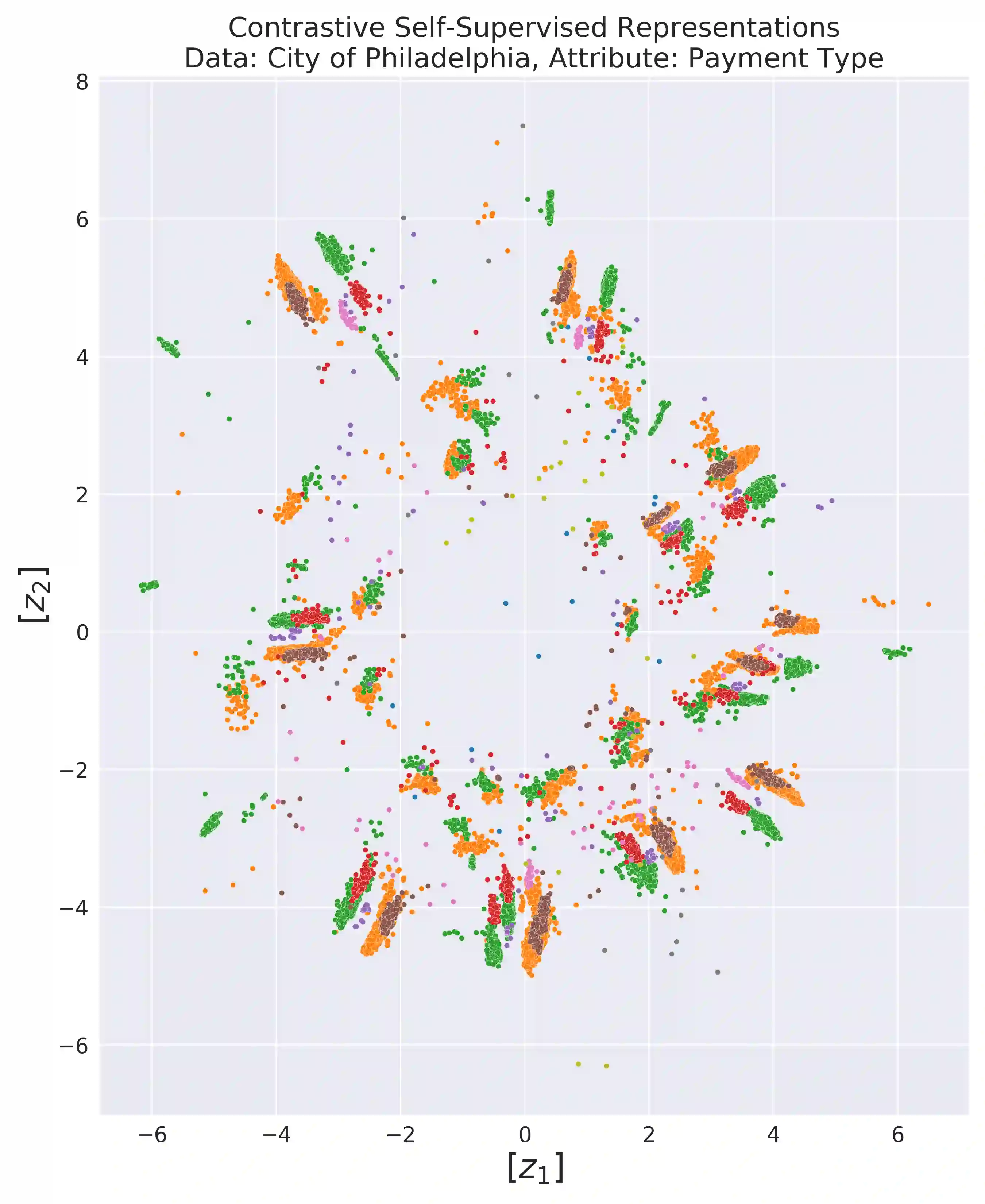
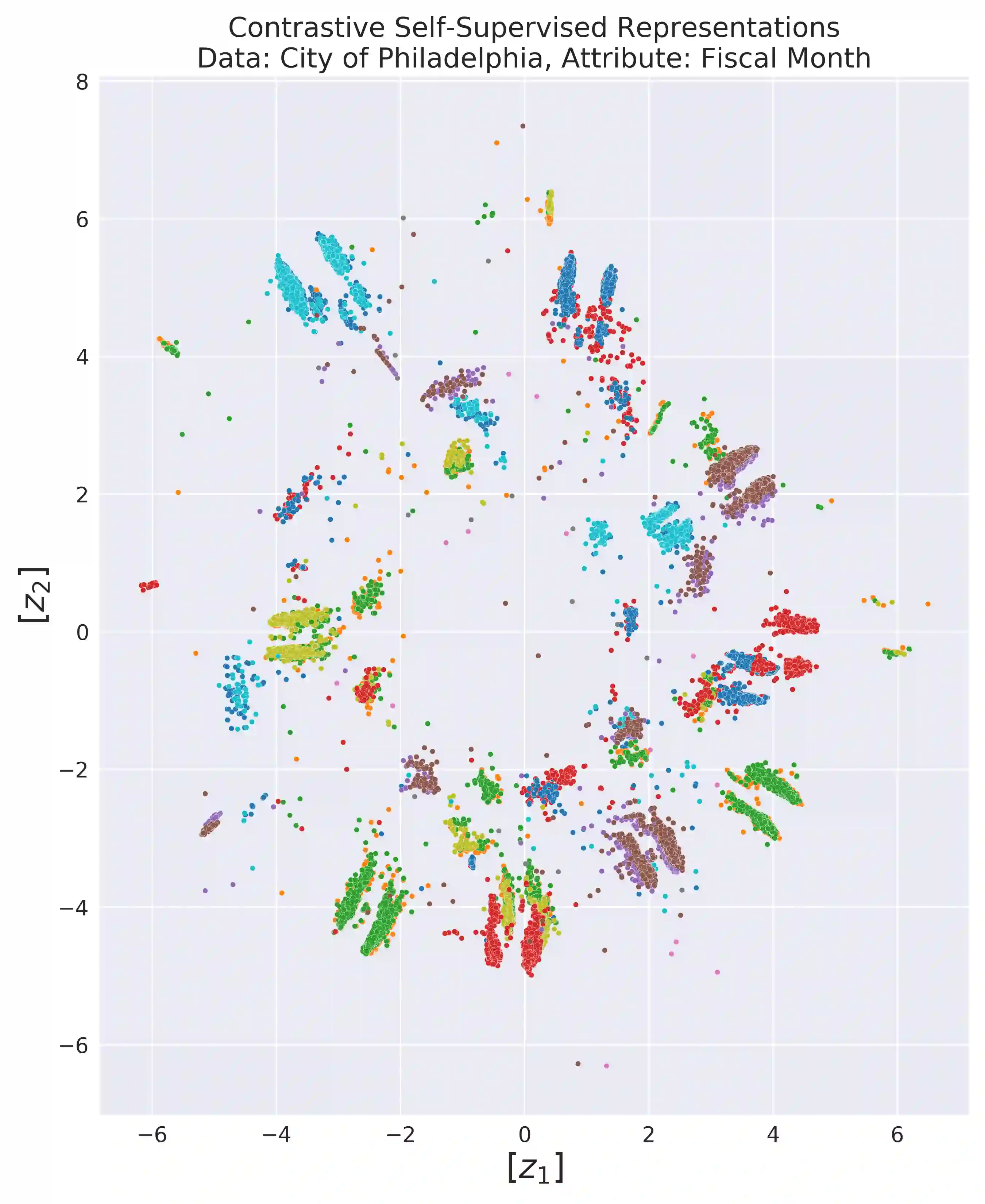
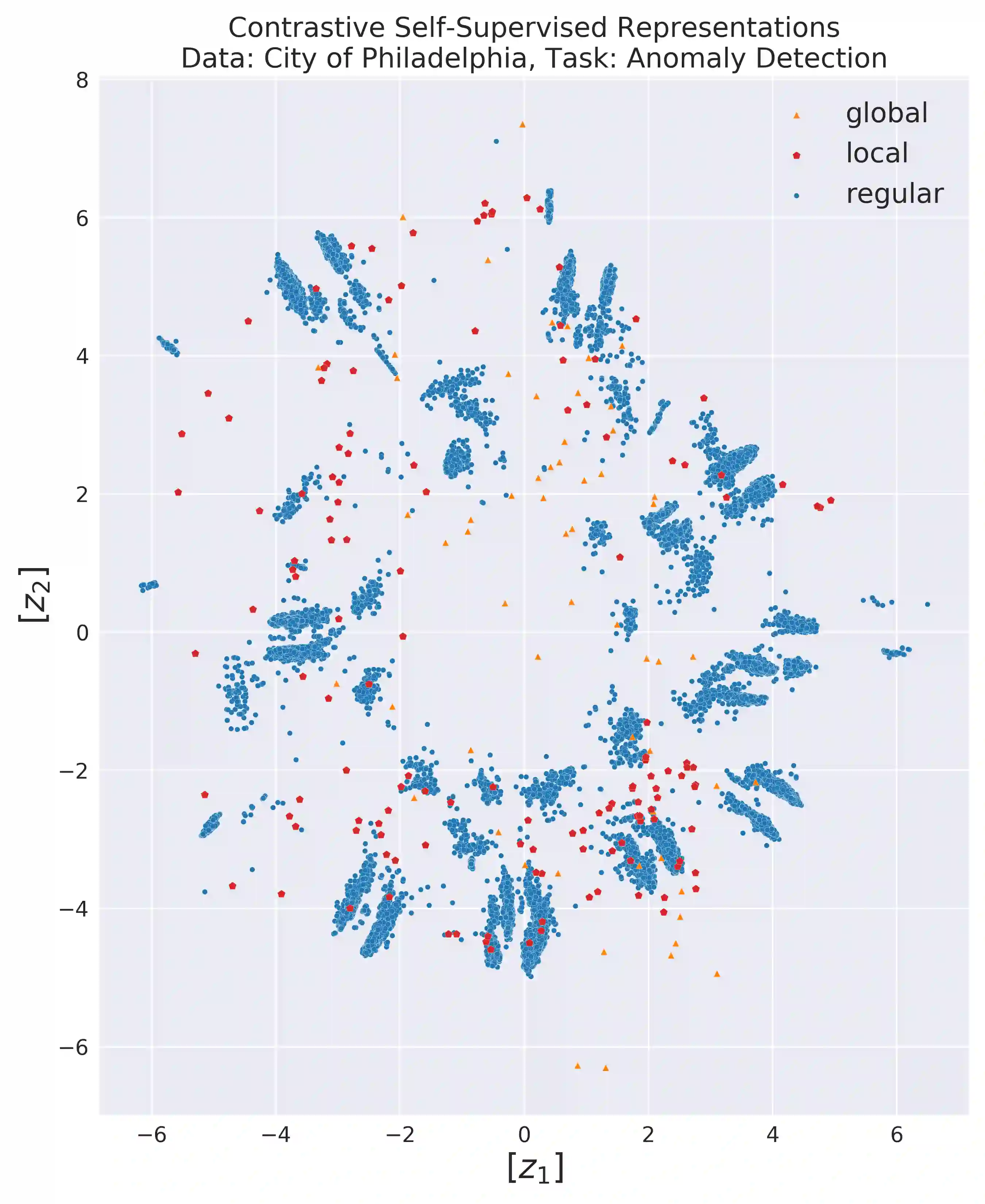
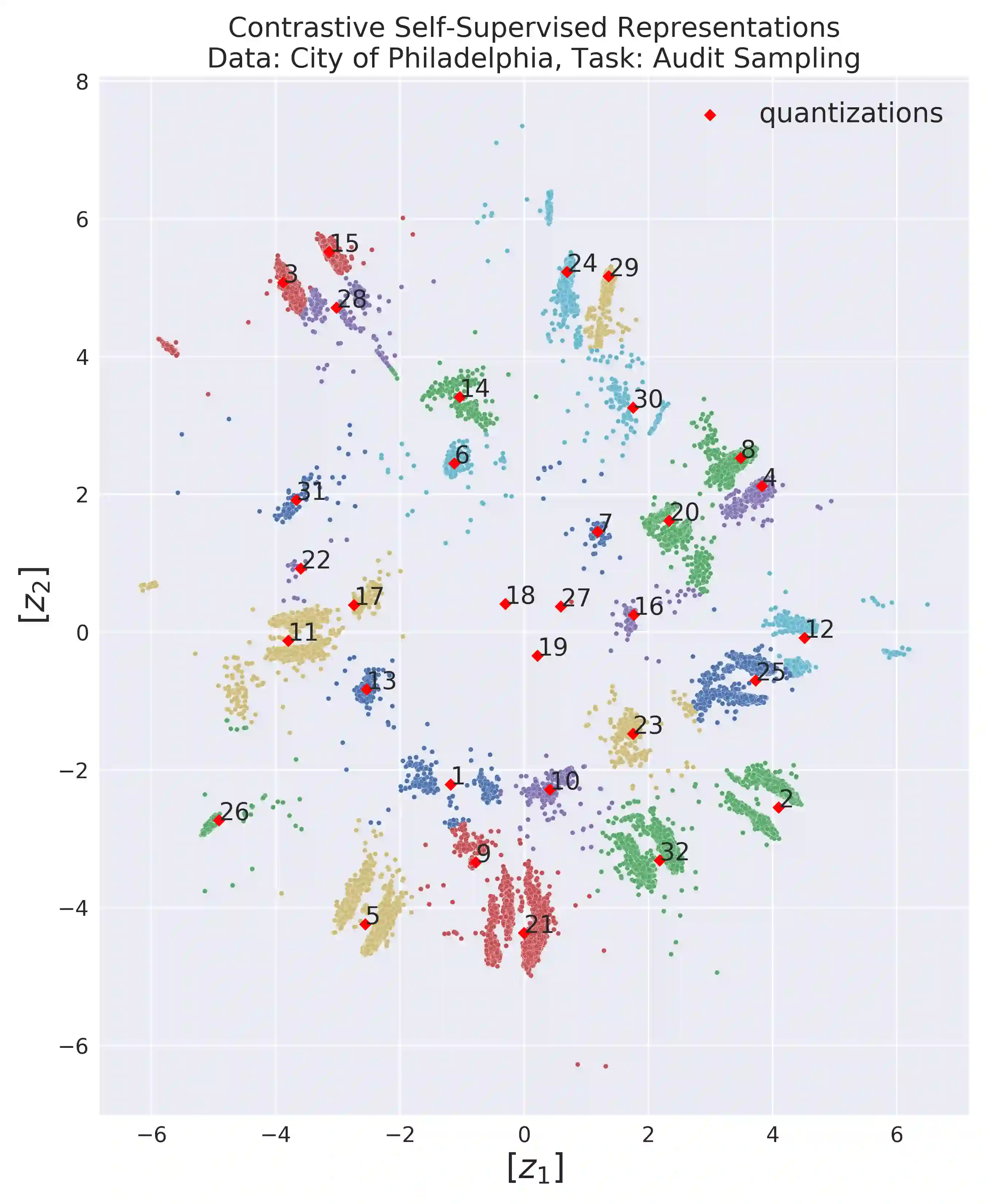
International audit standards require the direct assessment of a financial statement's underlying accounting transactions, referred to as journal entries. Recently, driven by the advances in artificial intelligence, deep learning inspired audit techniques have emerged in the field of auditing vast quantities of journal entry data. Nowadays, the majority of such methods rely on a set of specialized models, each trained for a particular audit task. At the same time, when conducting a financial statement audit, audit teams are confronted with (i) challenging time-budget constraints, (ii) extensive documentation obligations, and (iii) strict model interpretability requirements. As a result, auditors prefer to harness only a single preferably `multi-purpose' model throughout an audit engagement. We propose a contrastive self-supervised learning framework designed to learn audit task invariant accounting data representations to meet this requirement. The framework encompasses deliberate interacting data augmentation policies that utilize the attribute characteristics of journal entry data. We evaluate the framework on two real-world datasets of city payments and transfer the learned representations to three downstream audit tasks: anomaly detection, audit sampling, and audit documentation. Our experimental results provide empirical evidence that the proposed framework offers the ability to increase the efficiency of audits by learning rich and interpretable `multi-task' representations.
翻译:最近,在人工智能的进步推动下,在审计大量日记入数据领域出现了深层次的学习启发性审计技术。如今,大多数这类方法都依靠一套专门模型,每个模型都经过特定审计工作的培训。与此同时,审计小组在进行财务报表审计时,面临:(一) 具有挑战性的时间预算限制,(二) 广泛的文件记录义务,以及(三) 严格的可解释性示范要求。结果,审计人员倾向于在整个审计工作中只使用一种最好“多用途”的单一模式。我们提出一个对比式的自我监督学习框架,旨在学习各种会计数据表述中的审计工作,以满足这一要求。框架包括周密地利用日记入数据属性的强化数据政策。我们评价两个城市支付真实世界数据集的框架,并将所学到的表述转移到三个下游审计任务:异常情况检测、审计抽样和审计文件。我们提出的实验结果提供了实证证据,证明拟议的框架能够通过学习丰富的解释和可解释的方式提高审计效率。