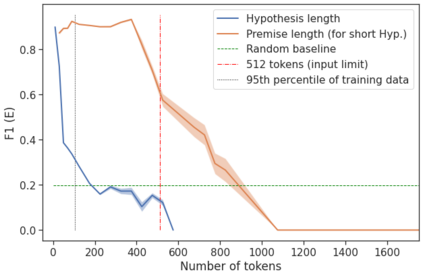
Natural Language Inference (NLI) has been extensively studied by the NLP community as a framework for estimating the semantic relation between sentence pairs. While early work identified certain biases in NLI models, recent advancements in modeling and datasets demonstrated promising performance. In this work, we further explore the direct zero-shot applicability of NLI models to real applications, beyond the sentence-pair setting they were trained on. First, we analyze the robustness of these models to longer and out-of-domain inputs. Then, we develop new aggregation methods to allow operating over full documents, reaching state-of-the-art performance on the ContractNLI dataset. Interestingly, we find NLI scores to provide strong retrieval signals, leading to more relevant evidence extractions compared to common similarity-based methods. Finally, we go further and investigate whole document clusters to identify both discrepancies and consensus among sources. In a test case, we find real inconsistencies between Wikipedia pages in different languages about the same topic.
翻译:自然语言推论(NLP)是国家语言规划局广泛研究的一个框架,用于估计对等徒刑之间的语义关系。虽然早期工作查明了国家语言规划模型中的某些偏差,但最近在建模和数据集方面的进步显示了有希望的表现。在这项工作中,我们进一步探索了国家语言规划模型在实际应用中直接零射的适用性,超越了它们经过培训的句子框设置。首先,我们分析了这些模型对于较长和超出主页的投入的稳健性。然后,我们开发了新的汇总方法,允许对完整文档进行操作,达到合同国家语言规划局数据集的最新性能。有趣的是,我们发现国家语言规划局的分数提供了强有力的检索信号,导致与基于相似性的共同方法相比更相关的证据提取。最后,我们进一步调查整个文件组,以查明来源之间的差异和共识。在试验中,我们发现不同语言的维基百科页面在相同主题上存在真正的不一致之处。