华为杨浩:小知识驱动大数据,构建知识可认知的 AI 应用

在 2021 年 11 月 25 日和 26 日,AICon 全球人工智能与机器学习大会(北京)上,我们邀请到了华为文本机器翻译实验室主任 杨浩,他将从离散知识和神经网络模型的融合角度为你带来《知识驱动的机器翻译研究和实践》,希望可以为你带来启发。
我们先来了解一下机器翻译系统的建模,它可以分为三个部分。
首先是翻译模型(Translation Model),解决从一个语言到另外一个语言的语言对齐问题,原语言到底是什么词,应该翻译成什么?
其次是语言模型(Language Model),目标语言尽可能地比较流畅。所谓的语言模型指的是,这个词后面接着的下一个词什么,或者几个词后面跟着的下一个词是什么?
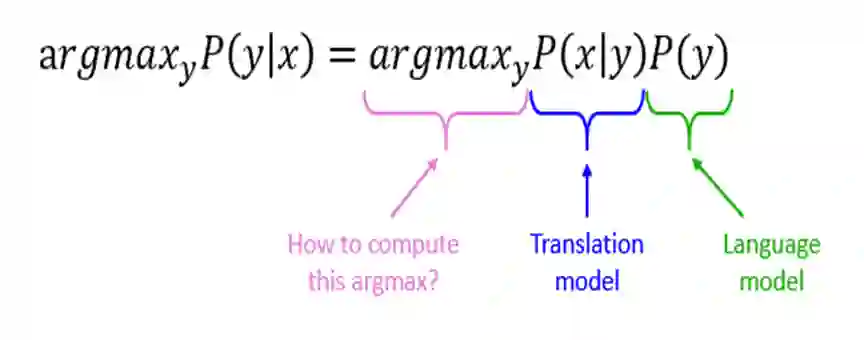
最后是 Compute argmax,这个模型是一个乘积的关系,寻找模型参数使它的乘积最大化,也就是我们通常说的训练,以上就是机器翻译的整个建模过程。
NMT(神经网络机器翻译)与统计机器翻译最大的区别,与机器学习和深度学习的区别是一样的。
机器学习与深度学习的区别,机器学习业务最典型基本上可以分为两层,一层是 Feature Extraction(特征抽取),另一层是 Downstream Task(下游任务),例如常见的 Classification。
而到了深度学习,没有显式的 Feature Extraction 和 Downstream Classification,而它是一种智能学习方式,我们将输入送进去,直接得到输出训练的过程,所以真正的 NMT 的优势可能就在于 End to End 的建模。
在文本生成的领域里面,最有名的模型是 Encode-Decoder Model,我们也称之为 Seq2Seq Model。
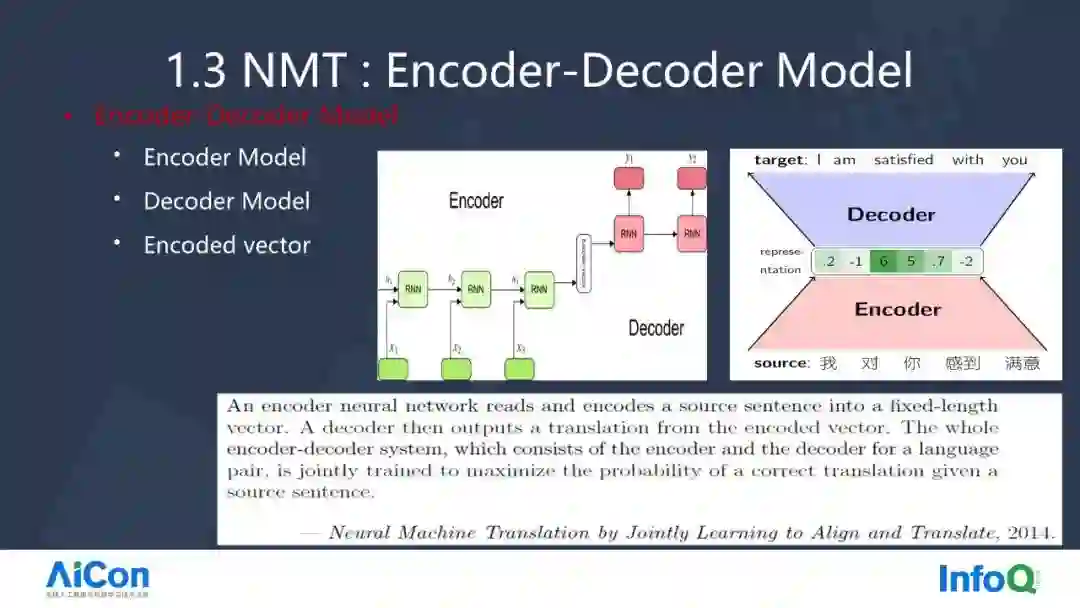
Seq2Seq 包含 Encoder,Decoder 两个 RNN Model。Encoder Model 是一个时序化建模的 RNN 网络。对数学公式: $ H1 $ 和数学公式: $ X1 $ 建模得到数学公式: $ H2 $,然后数学公式: $ H2 $ 跟数学公式: $ X2 $ 得到数学公式: $ H3 $,这样持续下去得到 Encoded vector,然后再基于编码的向量,经过 RNN 的 Decoder 解码出第一个词语,再把隐状态发送过来,然后经过第二个 RNN 解出数学公式: $ Y2 $,这就实现了整个翻译的过程。
我们拿上图右侧的例子来说明,例如“我对你感到满意”经过编码器,得到 Encoded vector ,它是一个多个维度的向量,再经过解码器得到翻译目标——I am satisfied with you。
举一个 Encoded 的动态例子,比如“how to configure s5700 arp?”
如果进行这个句子的机器翻译,整个过程是这样的,首先对每个词语分别进行编码,然后对问号做编码,最后当碰到 EOS(end of sentence)代表这个句子已经说完,那么这种时候可以的带 Encoded vector,将它送进一个 BOS(begin of sentence)。
Begin of sentence 基于上文的向量对所有词取最大的概率,那么就可以得到“如何”字段,然后将“如何”送过来解码,继而得到“配置”,接着得到“下一次”,这句话就解码完了,最后得出“如何配置 s5700 arp”,那么就得到了 Target Sentence。
我们刚才演示的过程称为 Greedy Decoding,也就是贪婪解码。所谓贪婪解码是每次只取概率为 Top1 的结果,那么假如不取 Top1 的结果,我可以取 Top k,然后每次保留 k 个分支,那么其实上类似于一个路径搜索。

上图 从<bos>

而对于 Seq2Seq 模型效果是这样的,神经网络模型优于统计机器翻译的模型。SMT 是统计记忆翻译的模型,NMT 是神经网络机器翻译,神经网络第一次以 34.81vs33.3 的成绩超过了统计机器翻译的模型。
而且神经网络的模型可以对统计机器翻译结果进行 Reranking(重排),取得 Beam Search Top50 的结果进行重排,它这个机制可以达到 36.6 的最高分。
但 Seq2seq 模型有一个问题,那就是 Encoder 永远编码成维度确定的句向量,当我们句子长短维度确定之后,这个向量无法表示足够多的句子信息。
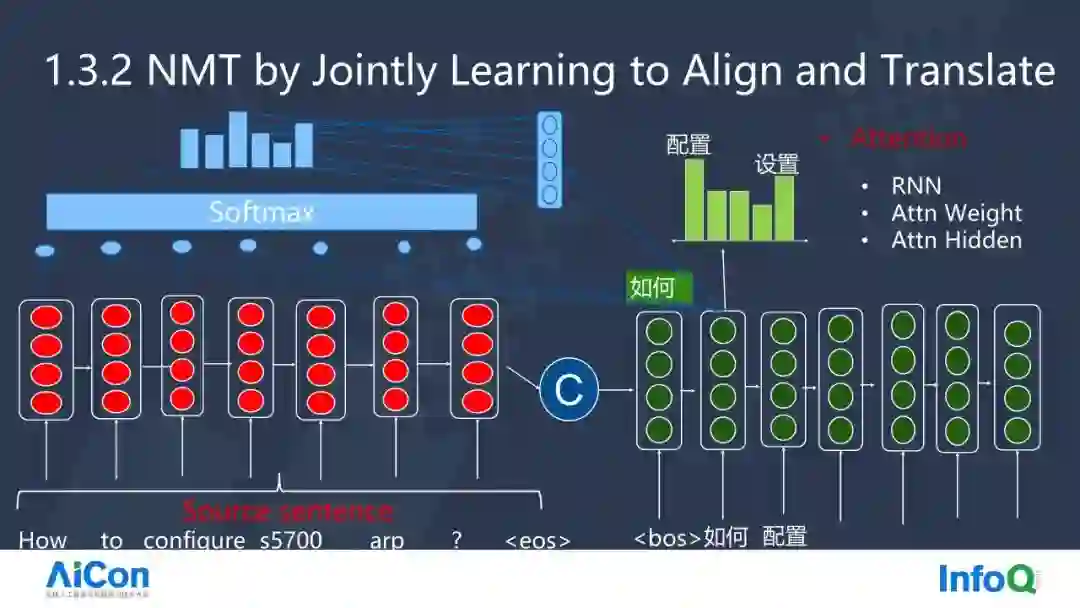
这个时候就需要引入业界很有名的 Attention 的机制。
当 Decoder 已经解码出了“如何”,得到了 Hidden state,Decoder 的“如何”会与 Source Token 进行 Attention 计算,我们可以将之理解为进行一个相似度的计算。当与所有 Source Tokens 做完 Attention 的计算后,再进行 Softmax,也就是将它的隐状态(hidden state)进行信息加权,最后得到一个向量。
这样,编码向量会和每个词相关的状态,这一个向量的状态是变化的,它能够很好地表现哪个词语已经翻译了,哪个词还没有翻译,以及接下来翻译哪个词语,这也就是 Align 与 Translate 的结合。

接下来,所有的 Encoder States 和 Decoder States 进行 Attention Scores ,然后进行加权平均(Softmax),最后加权平均的结果与每一个 Source 进行线性组合,就可以拿到最终结果。
中间是个典型的例子——The Animal didn't cross the street because it is too tired。假如说出现了 it is too tired 的话, it 的 attention weight 更多时候会 Attention 到 Animal 上面,那么相当于 it 代替的是狗或者动物;
而假如说出现 it is too wide,在经过 Attention 计算,更多对应到的是 cross the street 或者 cross the river。
从最右边的 Performance 也可以看得出来。RNNSearch 比 RNNEncode 好很多,句子长度 30 和 50,RNNsearch 分别提升了 7.2 和 7.4,最好效果可以达到 36.15。
这里 30 指的对含有 30 个词的句子进行训练,可以看到一般模型,句子越长效果越差,而 RNNSearch50 的情况下,可以看到效果基本上不变。(RNNencode 也就是之前的 Seq2Seq model,而 Attention model 在学术上称为 RNNsearch。)
并且惊喜的是,当句子超过 50 个词之后,RNNsearch50 翻译质量也不下降。

Attention is all you need 是那篇最经典的论文。
最初的 Seq2Seq without attention 有 CNN 和 RNN 进行 decoder,decoder 和 encoder 之间的关系是用静态的向量来表示的。而第二个模型 Seq2Seq with attention,则是由 CNN 和 RNN 做 decoder,中间是 attention 关联的。到了 Transformer 方面的话,所有都换成了 Attention 的模式。
就效果来看,统计机器翻译是 33.3,而在 Seq2Seq 的时候是 34.81,然后到 RNNSearch(RNNAttn)架构是 36.15,到 Transformer 架构到 41.8 了,提升非常明显。

Transformers 架构典型的三个特点有 No RNN、纯 Attention 以及 Position Embedding。
上图右边是典型的 Transformers 的架构,我们可以看到中间是 Self attention encoder,在此后面有 Feed Forward Network。接着是 Decoder self attention,然后 decode 和 encode 之间的 Attention,然后以及 Decoder Feed Forward。
这套架构 Transformers 的效果很好,BLEU 可以达到 41.8,并且 Transformer 训练时长缩短不少,这一点对工业用途很友好。
神经网络机器翻译经过了三轮迭代已经足够好了,但是它还存在命名实体、Topic、Document 以及 Consistency 等等问题,解决的方案是将我们的模型在大数据上进行训练,形成一个 Big Data+Small knowledge 的 Big knowledge 概念。
而后面的话,随着神经网络机器翻译的发展,你可以认为有一批数据在大数据上训练的模型,而我们接下来有一个理想,就是 Big Data,Big Data 加上 Smart 能够真正形成 Big Knowledge 的概念。
NMT 知识体系可以分为四部分,全局知识、领域知识、模型知识以及多模态知识。全局知识的最典型的模式是显式知识,最常用的是知识图谱。

上图是一个药品的知识图谱,有一个词语是乙酰水杨酸,它的同义词是阿司匹林,假如在没有知识驱动的情况下,就会被翻译成其他的。而当将实体 + 类型的三元组知识融合的情况下,就可以将乙酰水杨酸标准地翻译成阿司匹林,这个知识是一个显性的知识。
全局知识融合的另一种方式是隐示知识,目前典型方式是用预训练模型做初始化。阿里巴巴曾经有一个研究,使用 BERT 做 Encode 端的编码和初始化,还是用 GPT 做 Decode 端编码和初始化,训练拿到的结果是最好的。
不管是 BERT 还是 GPT 都融入了大量的知识,和我们前面的显式知识不一样,它是一种典型隐示的知识,因为它见过海量的句子,但是当前应用的是哪一个或者哪几个句子知识我们是不知道的。
了解全局知识之后,我们来聊一下领域知识,领域知识也分为显式和隐式知识。
领域知识显示的情况下,可以是 Token 和 NER Pair,也可以去解决 Decoding Constraint 或者 Grid Beam Search。
Great beam search 较为简单,比如当拿到一句漏掉“快”词语的句子,那么机器翻译模型将会重新调整这句话,然后把“Quick”增加到合适的地方,并且效果提升还是比较明显。

除词语级别之外,我们还可以做句子级别的知识融入。我们有个先验知识,原句相近,目标句也相近。在原句的后面拼接相似句,可以加强目标句解码正确的概率。
比如上图中,“胃息肉是个常见的癌症”,把这句话的翻译文字增加在下方,并且给予“胃息肉”一个显示的标签,然后与“胃息肉”相关的内容就翻译得很准确。
第三个是模型知识,模型知识也可以分为两种,整体知识和分层知识。最典型的整体知识是知识蒸馏,在 Seq2Seq 的模型里,知识蒸馏相当于利用模型生成各种伪数据,这样可以使得机器能够学得更好。
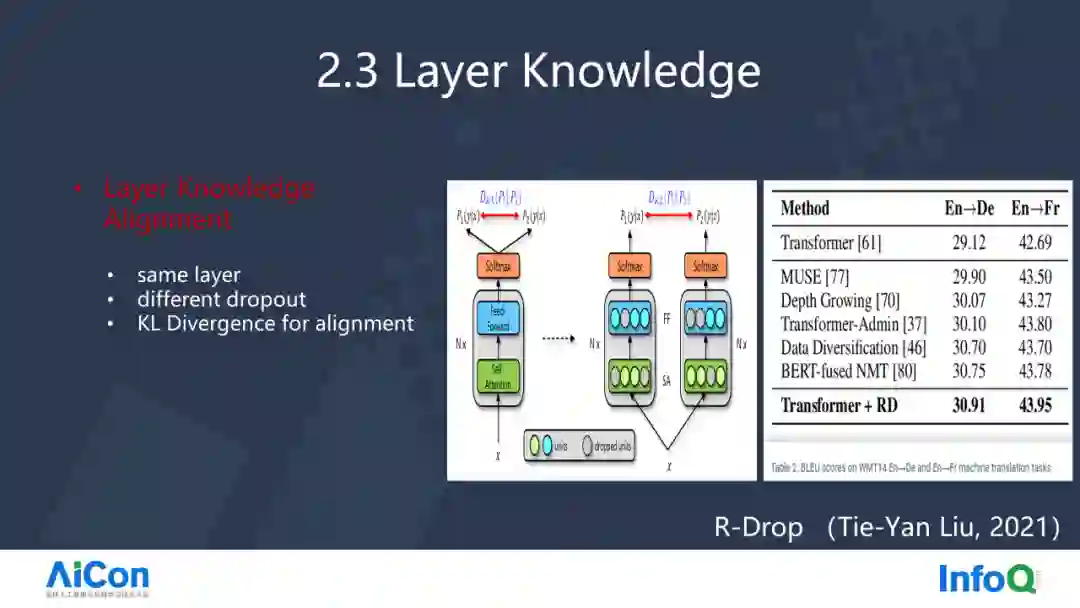
而分层知识则如上图,在训深练度学习模型的时候,Drop Out 是开启的状态,同一个句子会得到不完全一致的表示,模型越稳定的时候,不同的 Drop Out 拿到的两个句子向量(经过同一个 Encoder 得到的向量)是一样的,它才能保证解码的稳定性。所以在两个向量之间增加 KL 散度,就可以保证每次出来向量尽量一样。

最后是多模态的知识,“Rabbit is ready for cook”是要表达“兔子要吃饭了?”还是“我们要吃兔肉?”这个最典型的情况。
如何解决这个问题呢?
我们在 Encoder 这一层,将图像分割和图像的识别的特征与文本特征拼接起来,保持 Encoder 和 Decoder 模型不变,就可以解码这样的问题。
知识分类的建模过程如下:
第一,当我们已经有了内部的知识,不需要进行知识抽取的情况下, Input 经过生成模型可以得到 Output,然后直接调用内部的知识进行 Embedding。
第二,当我们需要外部知识的情况下,不管是公用领域的知识,或者一些领域外的知识,大家首先需要进行知识抽取,然后再进行知识注入和融合,再生成模型,进而得到有知识指导的输出。

而在训练的时候,知识驱动的模型会有 Knowledge Loss。当机器翻译的时候,除了保证生成的句子与目标越来越像,还需要保证不能出现 Critical Error。虽然它在整个评估指标的情况下,这类词在文本里面的比例很低,所以只能加上 Knowledge Loss 的效果才会比较好。
整体流程如下:
Input>Knowledge Acquisition>Knowledge Fusion>Output>Knowledge Sources。
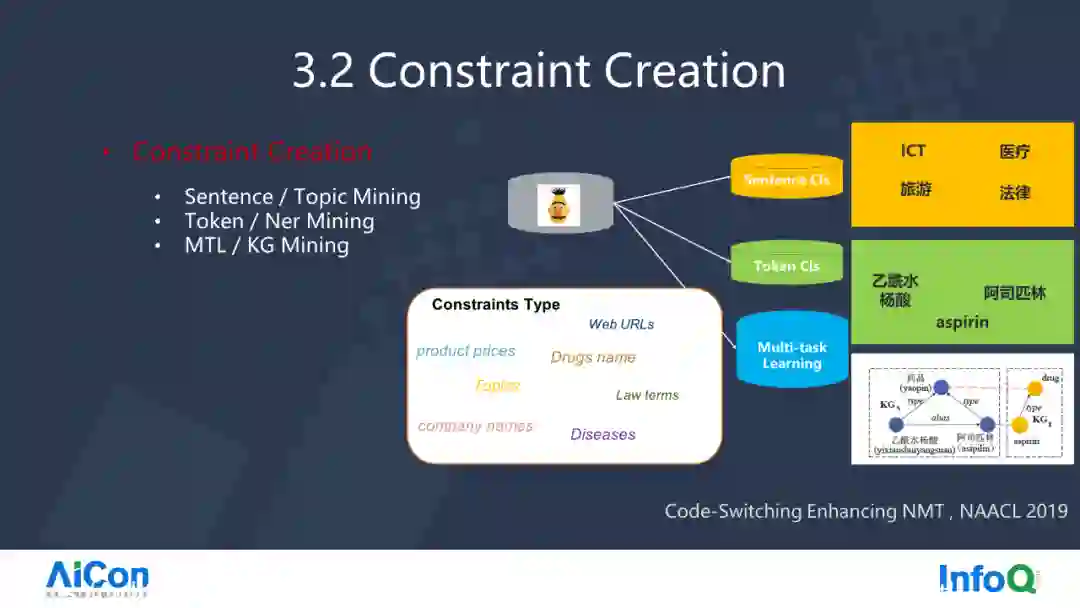
接下来讲一下约束生成,包含 Sentence/Topic Mining、Token/Ner Mining、MTL/KG Mining,Sentence 对应的领域、Token 事件词,以及 Multi-task 那些图片来做事情。
那么这样的时候就可以把 Domain 给建立起来。

当我们在解码的时候,实际上分为两种解码,分别是 Hard constraint 和 Soft constraint。Hard constraint 要求提供的约束必须出现,但是它会出现时态或语态的问题。
上图 Source 的句子中有一个词“Luptat”,它同时有争斗和脚踝的意思,但是 Unconstraint 翻译的,它会翻译成 struggle。
进行 Hard Constraint 的时候,不太好确定语态的问题,最后会翻译成 ankle,拿到了接近最优解的结果。Hard constraint 无需训练模型,直接在解码当中就行。
而当进行 Soft Constraint 时候,我们需要得到正常的 Token Pair Score、Sentence Paired score 的时候,同时验证其对齐关系和时态等语义信息平衡的最优解,换句话说,满足约束的加权得分最高,也就是 Knowledge loss 最小。
接下来我们一起进行一个知识驱动翻译实践。我们做了一个 WMT (国际机器翻译)Biomedical/Tavel 的翻译任务,它包含 Strong Domain Knowledge,和很多种语言的翻译任务。

这个任务有以下几点问题:
首先是专业领域,比如“prefers white”一般可以翻译成“喜欢白色”,但是对于体育领域或者下棋来说,应该翻译成“掷白棋”。
其次是一些 NER、漏译、过译以及风格问题。这里着重说一下风格问题,比如上图最下面翻译出来的 “20 世纪 20 年代和 30 年代”以及“1920 年代和 1930 年代”的区别还是很大的。

机器翻译的提升可以分成三个阶段:
第一阶段是 Vanilla Transformer NMT,这一阶段相当于用 In Domain 的数据来训练 Transform model。上图的训练数据有英德和英中等等,我们将数据进行预处理之后,然后进行 Proprocess Pair,接着训练 Model,然后配置训练参数之后,就可以得到上图右侧的效果,英中和中英分别得到 39 和 27,而在英德和德英的话分别拿到 31 和 37,这就相当于拿到了 Baseline Performance。
第二个阶段,随着大模型出来 Pre-training + Fine-tuning 是典型的业界范式。
Pre-training 利用具有很多数据的 Out-Domain,经过较大外部数据的机器翻译模型训练出一个大的模型,然后用小的数据来进行微调训练。
为了优化效果,还可以抽取同样接近大小的外部数据做领域的 discrimination,这一过程相当于区分领域外以及领域内的不同结果,换句话说,当提供一个句子组的时候,翻译成领域外什么样子,翻译成领域内是什么样子。
我们可以看到领域外的数据,例如拿英德和英中的 9600 万和 1500 万的数据,还有英德中大约一个亿的单语数据。

以英中为例,通过 Out-Domain 数据训练,我们得到 40 bleu,这已经比第一个模型(In Domain)要好。
然后,进行 In Domain Fine-tuning 以及 In-Out- Domain discrimination 的话,我们最终可以拿到 46.9 以及 35.5 的 performance。这已经是最好的表现了,接近 WMT 的冠军水平。
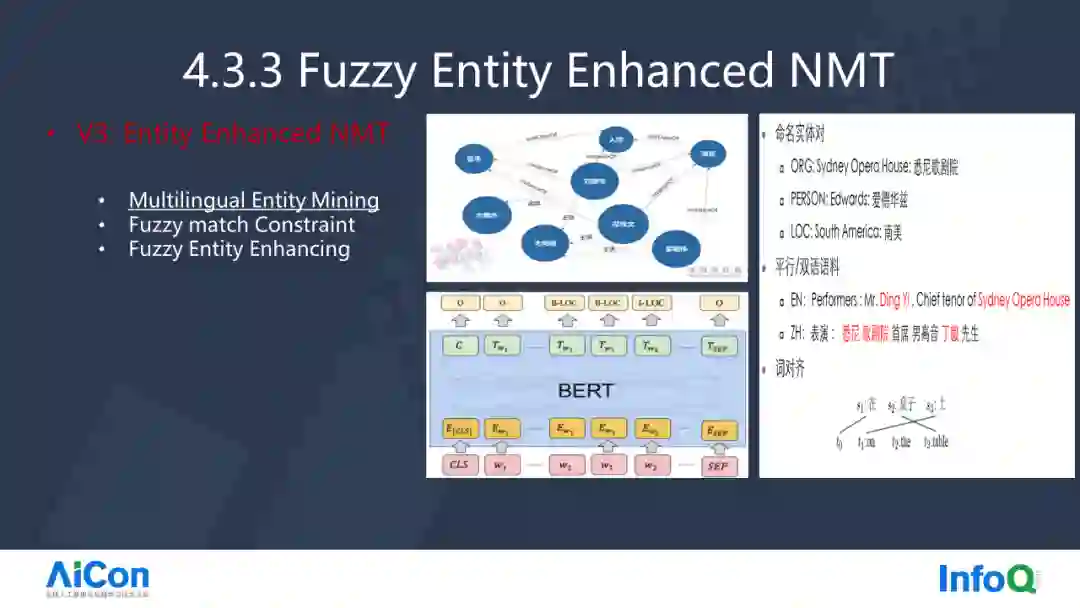
最后我们发现,还是存在一些实体词语翻译得不正确的问题,我们做了 Fuzzy Entity Enhance NMT。它指的是,训练识别 Entity 和 Entity 对齐,效果也有明显的提升。

我们对比的基线是 ACL2020 的一篇论文,这篇论文它借鉴相似句提升。比如“how long does a cold last”和“how long does the flight last”,经过对齐之后,Combien 德语后面一长串前面的几个字是一样的,在词级别打上标签,告诉模型哪几个词语是对的,哪几个词是错的,这个的效果取得了不少的提升。
但是前面的模型有两个问题,它所有的词的权重都是一样的,对齐的标签有噪声。
而我们针对性做了两个优化,首先是对实体词对实体词做加权;其次,我把目标句的标签全部修改到了原句上面,原句没有噪声问题,这相当于噪声降低了。这个模型相较前面的几个模型有百分之一点几的提升,并且在有实体词的情况下提升很明显,将近有 2% 左右,不过在没有实体词情况下,我们略有下降。
对于神经网络和机器翻译的畅想,首先是大模型或者自迁移的方向;其次是更准确多任务的 AI 服务;最后是知识性和可解释 AI 服务。
嘉宾介绍:
杨浩,华为文本机器翻译实验室主任,北京邮电大学通信与信息系统博士,师承两院院士陈俊亮老师,在搜索推荐和机器翻译等人工智能相关领域有十年以上研发经验。有 10+ICLR/ICASSP 等顶会论文和国内外专利,带领团队获得 WMT/WAT NEWS/DOMAIN/QE/APE 冠军。希望致力于机器翻译等技术方向,共建高质量全栈的人工智能服务和平台。
在 4 月 24-25 日,ArchSummit 全球架构师峰会即将落地上海,数字化转型是大趋势,不管是金融转型,还是汽车产业数字化转型,制造业数字化转型,一定会涉及到企业的产品形态,这里面包括市场定位和可行性的诸多因素,还有 ROI 评估模型。
除了在业务上的转型,在技术上也需要底层技术支持,例如微服务架构实践,数据库管理,前端开发,质量提升等等,共同保证项目落地。基于这些需求,ArchSummit 架构师峰会上邀请了国内较有经验的专家来分享各自的案例,帮助大家少踩坑,多复用,快速解决工作中的问题,了解更多请点击阅读原文或扫描下方二维码即可参与。




