如何有效提升中文NER性能?词汇增强方法总结

众所周知,与英文NER相比,中文NER通常采取基于字符的方式。究其缘由,由于中文分词存在误差,基于字符的NER系统通常好于基于词汇(经过分词)的方法。而引入词汇信息(词汇增强)的方法,通常能够有效提升中文NER性能。本文对「词汇增强」的系列方法进行介绍。
一、为什么要进行词汇增强?
从另一个角度看,由于NER标注数据资源的稀缺,BERT等预训练语言模型在一些NER任务上表现不佳。特别是在一些中文NER任务上,词汇增强的方法会好于或逼近BERT的性能。因此,关注「词汇增强」方法在中文NER任务很有必要。
二、词汇增强方法有哪些?
近年来,基于词汇增强的中文NER主要分为2条主线[9]:
Dynamic Architecture:设计一个动态框架,能够兼容词汇输入;
Adaptive Embedding :基于词汇信息,构建自适应Embedding;

Dynamic Architecture范式通常需要设计相应结构以融入词汇信息。
[1] Lattice LSTM:Chinese NER Using Lattice LSTM(ACL2018)
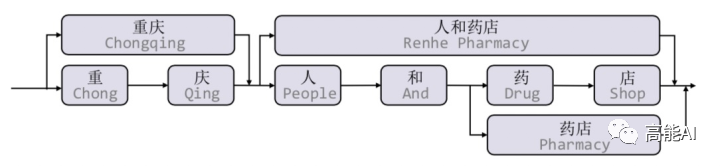
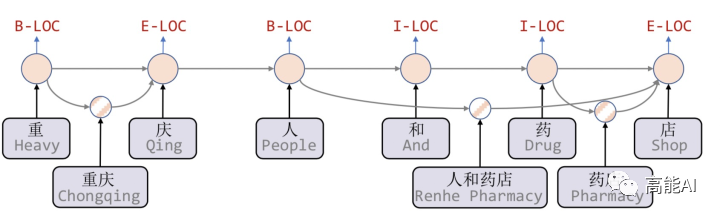
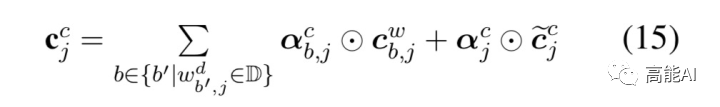
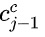 ,即不保留对词汇信息的持续记忆。
,即不保留对词汇信息的持续记忆。
计算性能低下,不能batch并行化。究其原因主要是每个字符之间的增加word cell(看作节点)数目不一致;
信息损失:1)每个字符只能获取以它为结尾的词汇信息,对于其之前的词汇信息也没有持续记忆。如对于「药」,并无法获得‘inside’的「人和药店」信息。2)由于RNN特性,采取BiLSTM时其前向和后向的词汇信息不能共享。
可迁移性差:只适配于LSTM,不具备向其他网络迁移的特性。
[2] LR-CNN:CNN-Based Chinese NER with Lexicon Rethinking(IJCAI2019)
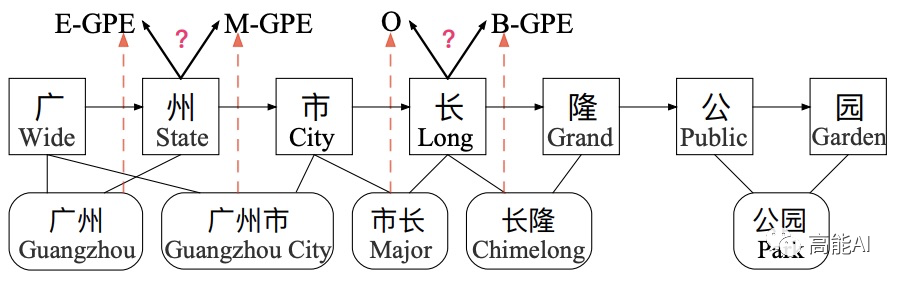
Lattice LSTM采取RNN结构,导致其不能充分利用GPU进行并行化。此外,Lattice LSTM无法有效处理词汇信息冲突问题,如上图所示:字符 [长] 可以匹配到词汇 [市长] 和 [长隆],不同的匹配会导致[长] 得到不同的标签,而对于RNN结构:仅仅依靠前一步的信息输入、而不是利用全局信息,无法有效处理这一冲突问题。显而易见,对于中文NER,这种冲突问题很常见,在不参考整个句子上下文和高层信息的前提下很难有效解决。
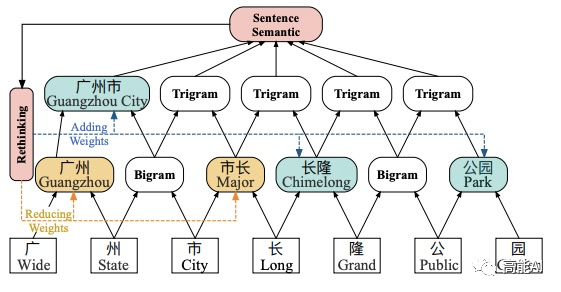
本篇论文LR-CNN为解决这一问题,提出了Lexicon-Based CNNs和Refining Networks with Lexicon Rethinking:
Lexicon-Based CNNs:采取CNN对字符特征进行编码,感受野大小为2提取bi-gram特征,堆叠多层获得multi-gram信息;同时采取注意力机制融入词汇信息;
Refining Networks with Lexicon Rethinking:由于上述提到的词汇信息冲突问题,LR-CNN采取rethinking机制增加feedback layer来调整词汇信息的权值:具体地,将高层特征最为输入通过注意力模块调节每一层词汇特征分布。
[3] CGN: Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network( EMNLP2019)
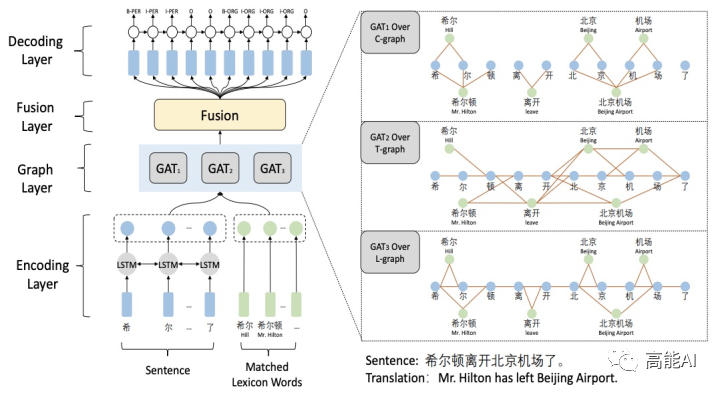
Word-Character Containing graph (C-graph):字与字之间无连接,词与其inside的字之间有连接。
Word-Character Transition graph(T-graph):相邻字符相连接,词与其前后字符连接。
Word-Character Lattice graph(L-graph):相邻字符相连接,词与其开始结束字符相连。
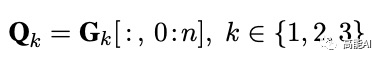
特征融合则将基于字符的上下文表征H与图网络表征加权融合:
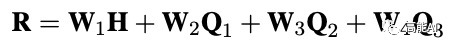
涉及GAN的相关计算公式可参考原论文。
[4] LGN:A Lexicon-Based Graph Neural Network for Chinese NER(EMNLP2019)
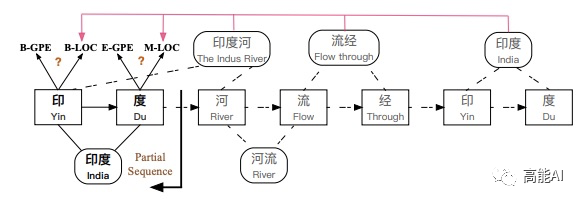
本篇论文与LR-CNN出发点类似,Lattice LSTM这种RNN结构仅仅依靠前一步的信息输入,而不是利用全局信息,如上图所示:字符 [流]可以匹配到词汇 [河流] 和 [流经]两个词汇信息,但Lattice LSTM却只能利用 [河流] ;字符 [度]只能看到前序信息,不能充分利用 [印度河] 信息,从而造成标注冲突问题。
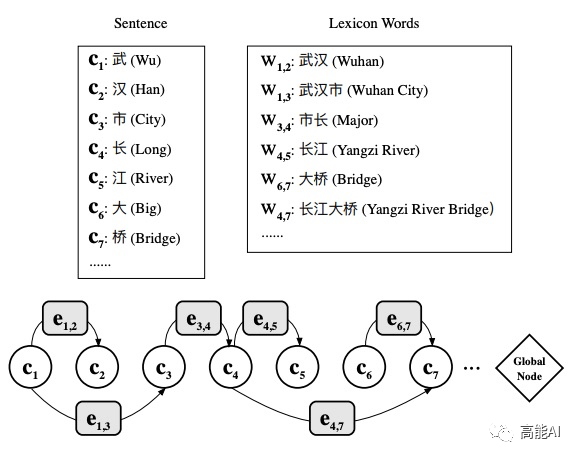
[5] FLAT: Chinese NER Using Flat-Lattice Transformer(ACL2020)
Lattice-LSTM和LR-CNN采取的RNN和CNN结构无法捕捉长距离依赖,而动态的Lattice结构也不能充分进行GPU并行。
而CGN和LGN采取的图网络虽然可以捕捉对于NER任务至关重要的顺序结构,但这两者之间的gap是不可忽略的。其次,这类图网络通常需要RNN作为底层编码器来捕捉顺序性,通常需要复杂的模型结构。
因此,我们可以将Lattice结构展平,将其从一个有向无环图展平为一个平面的Flat-Lattice Transformer结构,由多个span构成:每个字符的head和tail是相同的,每个词汇的head和tail是skipped的。
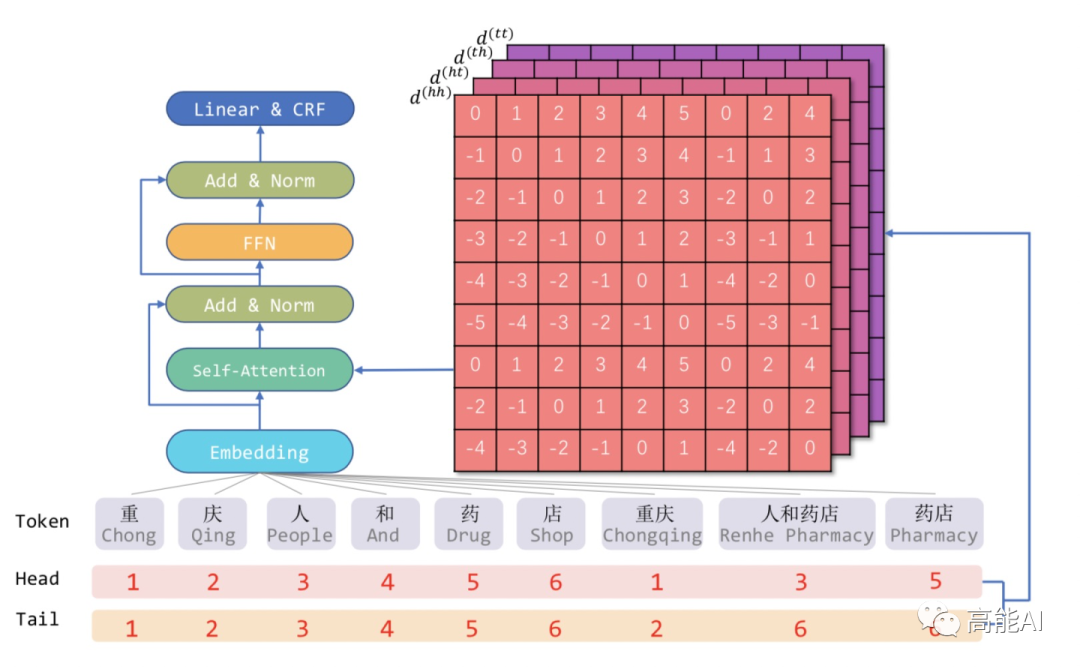
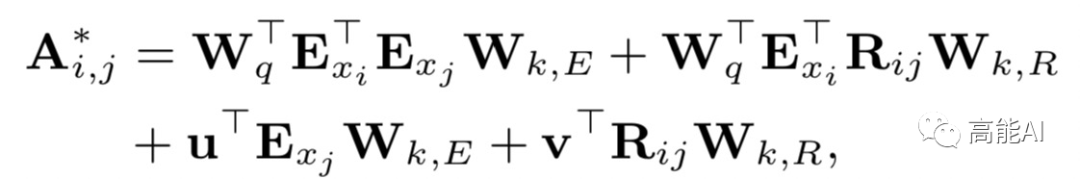
论文提出四种相对距离表示token之间的关系,同时也考虑字符和词汇之间的关系:
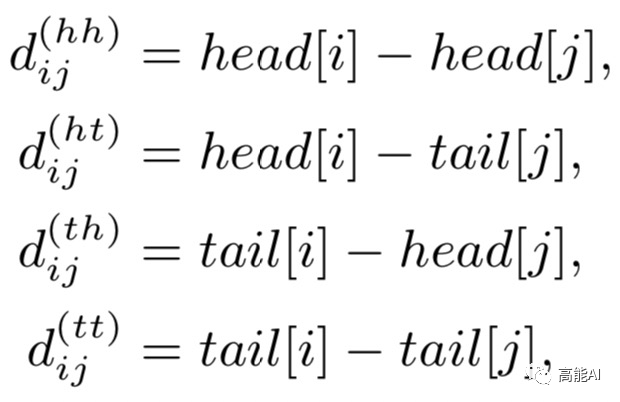
Adaptive Embedding范式
Adaptive Embedding范式仅在embedding层对于词汇信息进行自适应,后面通常接入LSTM+CRF和其他通用网络,这种范式与模型无关,具备可迁移性。
[6] WC-LSTM: An Encoding Strategy Based Word-Character LSTM for Chinese NER Lattice LSTM(NAACL2019)
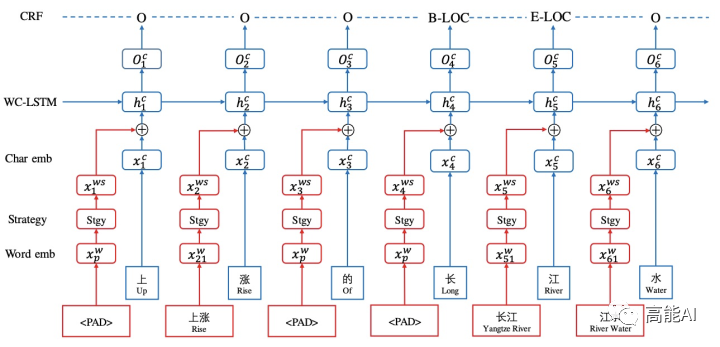
WC-LSTM仍然存在信息损失问题,无法获得‘inside’的词汇信息,不能充分利用词汇信息。虽然是Adaptive Embedding范式,但WC-LSTM仍然采取LSTM进行编码,建模能力有限、存在效率问题。
[7] Multi-digraph: A Neural Multi-digraph Model for Chinese NER with Gazetteers(ACL2019)
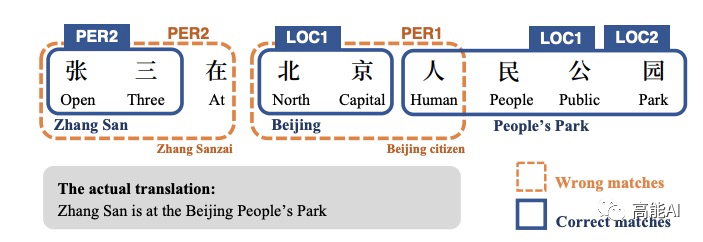
虽然引入实体词典等有关知识信息对NER性能可能会有所帮助,但实体词典可能会包含不相关甚至错误的信息,这会损害系统的性能。如上图所示,利用4个实体词典:「PER1」、「PER2」、「LOC1」、「LOC2」进行匹配,错误实体就有2个。
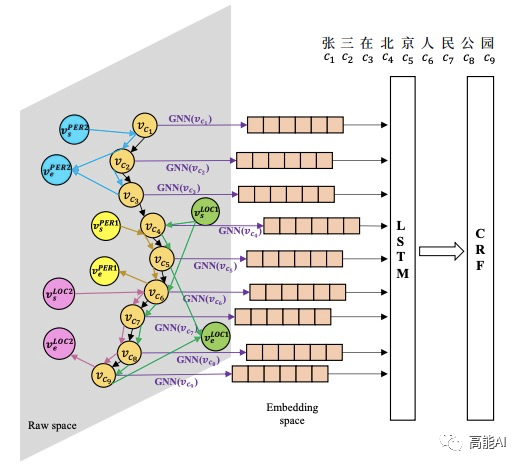
具体地,本文通过图结构建模Gazetteers信息,关键在于怎么融入不同词典的信息。上述图结构中「边」的label信息即包含字符间的连接信息,也包含来自不同m个Gazetteers的实体匹配信息,共有L个label:
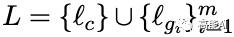
而传统的GGNN不能处理带有不同label信息的「边」,为了能够处理上述的多图结构,本文将邻接矩阵A扩展为包括不同标签的边,对边的每一个label分配相应的可训练参数:
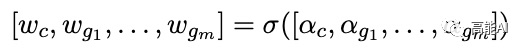
上述图结构的隐状态采用GRU更新,具体更新方式可参考原论文。最后,将基于GGNN提取字符所对应的特征表示喂入LSTM+CRF中。
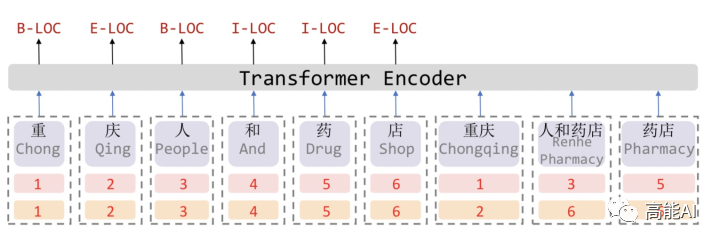
[8] Simple-Lexicon:Simplify the Usage of Lexicon in Chinese NER(ACL2020)
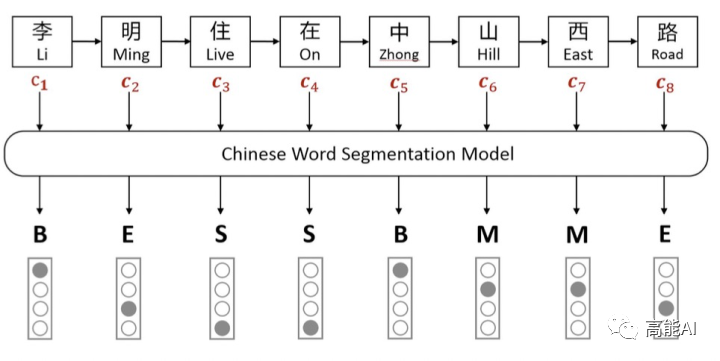
如上图所示,Softword通过中文分词模型后,对每一个字符进行BMESO的embedding嵌入。显而易见,这种Softword方式存在由分词造成的误差传播问题,同时也无法引入词汇对应word embedding。
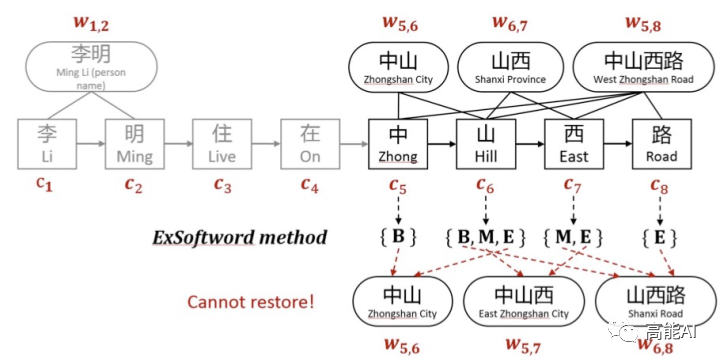
ExtendSoftword也会存在一些问题:
仍然无法引入词汇对应的word embedding;
也会造成信息损失,无法恢复词汇匹配结果,例如,假设有两个词汇列表[中山,山西,中山西路]和[中山,中山西,山西路],按照ExtendSoftword方式,两个词汇列表对应字符匹配结果是一致的;换句话说,当前ExtendSoftword匹配结果无法复原原始的词汇信息是怎样的,从而导致信息损失。
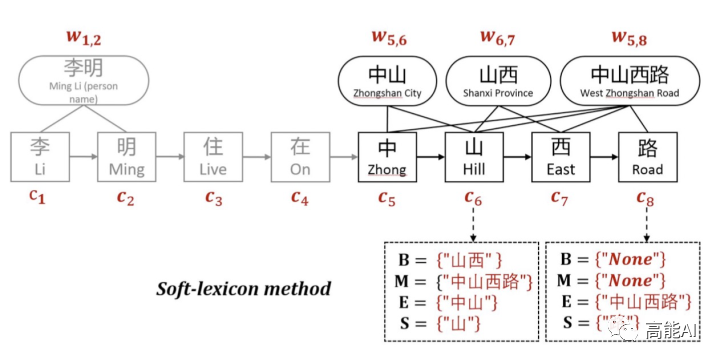
为了解决Softword和ExtendSoftword存在的问题,Soft-lexicon对当前字符,依次获取BMES对应所有词汇集合,然后再进行编码表示。
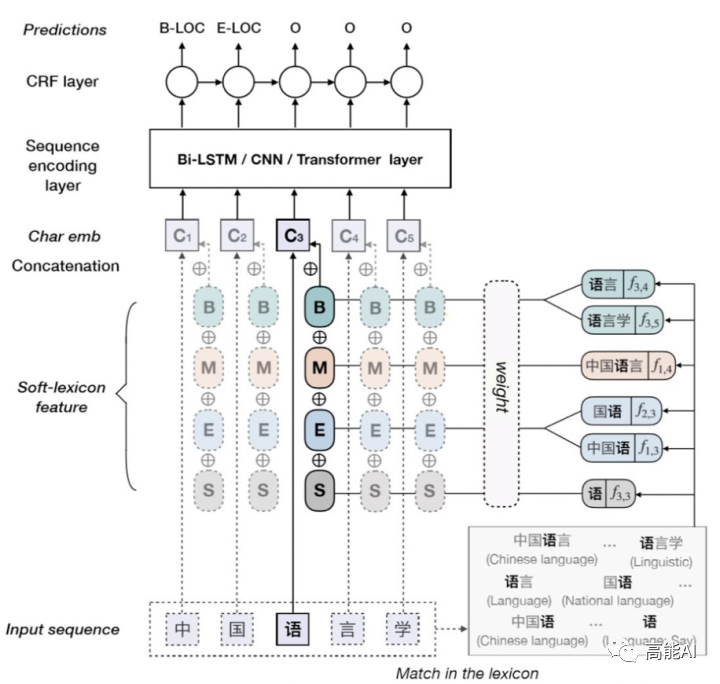
由上图可以看出,对于字符[语],其标签B对应的词汇集合涵盖[语言,语言学];标签M对应[中国语言];标签E对应[国语、中国语];标签S对应[语]。当前字符引入词汇信息后的特征表示为:
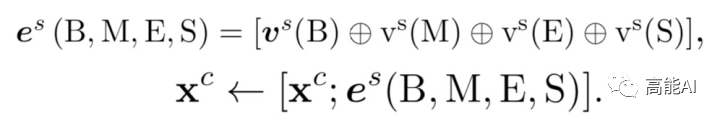
很容易理解,上述公式则将BMES对应的词汇编码与字符编码进行拼接,其计算方式为:
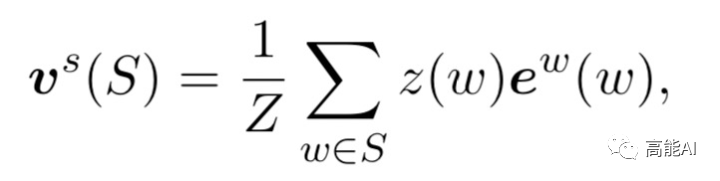
综上可见,Soft-lexicon这种方法没有造成信息损失,同时又可以引入word embedding,此外,本方法的一个特点就是模型无关,可以适配于其他序列标注框架。
三、总结对比:结果分析
下面对于上述「词汇增强」方法进行汇总:

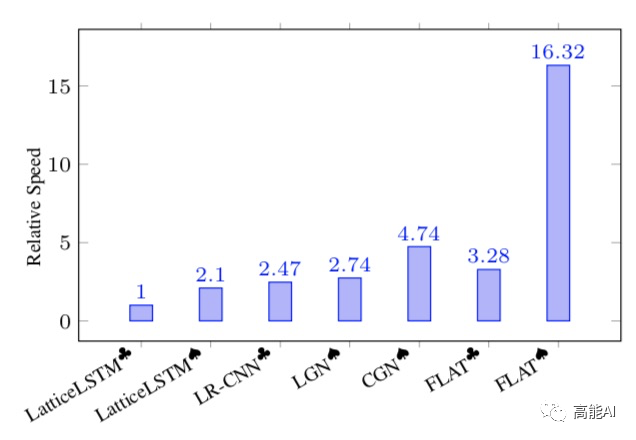
最后,我们来看一下,上述各种「词汇增强」方法在中文NER任务上的性能:
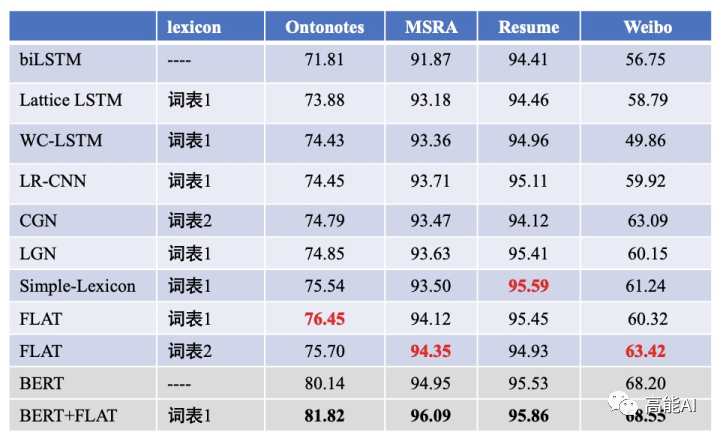
上图可以发现:总的来看,ACL2020中的FLAT和Simple-Lexicon效果最佳。具体地说:
引入词汇信息的方法,都相较于baseline模型biLSTM+CRF有较大提升,可见引入词汇信息可以有效提升中文NER性能。
采用相同词表对比时,FLAT和Simple-Lexicon好于其他方法。
结合BERT效果会更佳。
获取更多「信息抽取」相关的信息,可关注DeepIE
DeepIE介绍:https://github.com/loujie0822/DeepIE,基于深度学习的信息抽取技术集散地,欢迎大家关注,包含实体、关系、属性、事件、链接&标准化等。
Reference
[1] Lattice LSTM:Chinese NER Using Lattice LSTM
[2] LR-CNN:CNN-Based Chinese NER with Lexicon Rethinking
[3] CGN:Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network
[4] LGN: A Lexicon-Based Graph Neural Network for Chinese NER
[5] FLAT: Chinese NER Using Flat-Lattice Transformer
[6] WC-LSTM: An Encoding Strategy Based Word-Character LSTM for Chinese NER Lattice LSTM
[7] Multi-digraph: A Neural Multi-digraph Model for Chinese NER with Gazetteers
[8] Simple-Lexicon:Simplify the Usage of Lexicon in Chinese NER
[9] 结合词典的中文命名实体识别 (复旦大学自然语言处理组)
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇




