编辑:袁榭 好困
【新智元导读】一个看似简单的算法,不仅彻底改变了神经网络处理语言的方式,而且还逐渐地影响到了整个计算机视觉领域。也许,它所带来的可能性远不止这些。
现在在AI业界家喻户晓的Transformer,究竟是怎样在短短时间爆火的?
想象一下你逛附近的五金店,在货架上看到一种新型的锤子。它比其他锤子敲得更快、更准确,在过去几年里,它已经淘汰了许多其他锤子,至少在大多数用途中是这样。
而且通过一些调整——这里加个附件,那里加个扭矩——这个工具还能变成了一把锯子!它的切割速度和精确度不亚于任何同类产品。
事实上,一些处于五金开发前沿的专家表示,这把锤子可能只是所有五金工具将融合到单个设备中的前兆。
那个「多功能的新锤子」是称为Transformer的人工神经网络,这是一种通过对现有数据进行训练来「学习」如何完成某些任务的节点网络。
最初,Transformer被用于语言处理,不过最近则影响到了更多的领域。
2017年,Transformer首次出现在谷歌研究人员发表的论文中,该论文题目是神秘的「Attention Is All You Need」。
之前其他人工智能的通用路径是,系统会首先关注输入数据局部的块,然后再去构建整体。例如,在语言模型中,邻近的单词首先会被组合在一起。
而Transformer的运行路径,则会让输入数据中的每个单元都相互联系或得到关注,研究人员将此称为「自注意力」。这意味着一旦开始训练,Transformer就可以看到整个数据集的处理轨迹。
论文链接:
https://arxiv.org/abs/1706.03762
很快,Transformer就成为专注于分析和预测文本的单词识别等应用程序的领头羊。它催生了一批新的AI工具,比如OpenAI的GPT-3,它可以训练数千亿个单词并持续生成语义可读的新文本,智能到令人不安。
Transformer的成功让AI业界好奇它还能完成其他哪些任务,而答案正在揭晓。
在诸如图像分类的视觉任务中,使用Transformer的神经网络更快、更准确。而那些需要一次性处理多种输入数据/计划任务的新兴任务也预示着,Transformer能执行的工作还可以更多。
就在10年前,AI学界的不同子领域之间几乎没有共通语言。但Transformer的到来表明了融合的可能性。
德克萨斯大学奥斯汀分校的计算机科学家Atlas Wang说:「我认为Transformer之所以如此受欢迎,是因为它暗含着全领域通用的潜力。我们有充分的理由想要在整个AI科学范围内尝试使用Transformer」。
在「Attention Is All You Need」论文发布几个月后,扩大Transformer应用范围的最有前途的举措之一就开始了。
当时在柏林的谷歌研究部门工作的计算机科学家Alexey Dosovitskiy,正在研究计算机视觉,这是一个专注于教计算机如何处理和分类图像的AI子领域。
与该领域的几乎所有其他人一样,他当时的常用工具是卷积神经网络(CNN),多年来,这种技术推动了深度学习、尤其是计算机视觉领域的所有重大飞跃。
CNN的工作原理是反复对图像中的像素使用滤波器,以建立对特征的识别。正是由于卷积功能,照片应用程序可以按面孔组织图片库,或者将云与鳄梨区别开来。
由此,CNN也成为了视觉任务处理中必不可少的工具。
Dosovitskiy正在研究该领域最大的挑战之一,即扩大CNN的规模,以训练越来越高分辨率图像带来的越来越大的数据集,同时不增延处理时间。
这时他注意到,Transformer在NLP任务中几乎已经完全取代了此前所有的工具。
这个想法很有洞见。毕竟,如果Transformer可以处理单词的大数据集,为什么不能处理图片的呢?
最终的结果是一个名为「视觉Transformer」或ViT的神经网络,研究人员在2021年5月的一次会议上展示了该网络。
论文链接:
https://arxiv.org/abs/2010.11929
该模型的架构与2017年提出的第一个Transformer的架构几乎相同,只进行了微小的更改,使其能够分析图像而非文字。
ViT团队知道他们无法完全模仿Transformer处理语言数据的方法,因为每个像素的自注意力要在模型运行中全部完成,将会极其耗时。
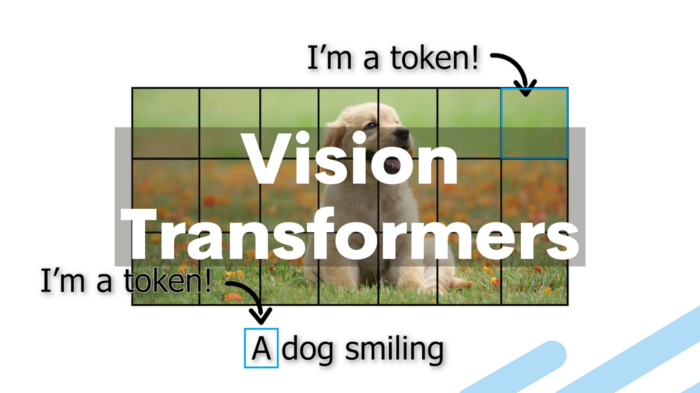
相反,他们将较大的图像划分为正方形的单元,也就是所谓的词元(token)。词元大小是任意的,因为可以根据原始图像的分辨率变大或变小(默认是每边16像素)。
通过分单元处理像素,并对每个单元应用自注意力,ViT可以快速处理大量训练数据集,从而产生越来越准确的分类。
Transformer以超过90%的准确率对图像进行分类,这比Dosovitskiy预期的结果要好得多。在ImageNet分类挑战赛这项业界标杆性图像识别比赛中,ViT迅速获得榜首。
ViT的成功表明,CNN可能不像很多研究人员认为的那样,是计算机视觉的唯一基础。
与Dosovitskiy合作开发ViT的Neil Houlsby说:「我认为CNN很可能在不久的未来被视觉Transformer或其衍生品所取代。」
在2022年初的测试中,ViT的更新版本仅次于将CNN与Transformer相结合的新方法。而之前的冠军CNN模型,现在勉强进入前10名。
ImageNet的结果表明,Transformer的确可以与CNN相抗衡。
但是,谷歌的计算机科学家Maithra Raghu想知道它们是否像CNN那样「看到」图像。
虽然神经网络是一个臭名昭著的黑匣子,但有一些方法可以窥探其内部情况。
比如。通过逐层检查网络的输入和输出,从而了解训练数据是如何流动的。
论文链接:
https://arxiv.org/abs/2108.08810
对于CNN来说,它会逐个像素地识别图像,通过从局部到全局的方式识别每一个角落或线条的特征。
在自注意力的加持下,Transformer甚至可以在神经网络的第一层,就把分布在图像两头的信息建立联系。
如果说CNN的方法就像从一个像素开始放大,那么Transformer则是慢慢地将整个模糊的图像变得清晰。
这种差异在语言领域更容易理解。比如,猫头鹰发现了一只松鼠。它试图用爪子抓住它,但只抓到了它的尾巴末端。第二个句子的结构令人困惑。
这些「它」指的是什么?一个只关注紧挨着「它」字的CNN会很费劲,但一个将每个字与其他字联系起来的Transformer可以看出,猫头鹰做了抓取的动作,而松鼠则失去了部分尾巴。
现在研究人员希望将Transformer应用于一项更艰巨的任务:生成新图像。
就像GPT-3等语言工具可以根据其训练数据生成新文本一样。
于是,在2021年发表的一篇论文中,Wang结合了两个Transformer模型,试图对图像做同样的事情。这是一个困难得多的任务。
论文链接:https://arxiv.org/abs/2102.07074
当双Transformer网络在超过20万名人的面部图片上进行训练时,它以中等分辨率合成了新的面部图像。
根据初始分数(一种评估神经网络生成图像的标准方法),Transformer生成的名人图片令人印象深刻,并且至少与CNN生成的名人图片一样令人信服。
Transformer在生成图像方面的成功,比ViT在图像分类方面的能力更令人惊叹。
同样,在多模态处理方面,Transformer也有了一席之地。
在以前孤立的方法中,每种类型的数据都有自己的专门模型。而多模态网络则可以让一个程序除了听声音外,还可以读取一个人的嘴唇。也就是可以同时处理多种类型数据的模型,如原始图像、视频和语言。
「你可以拥有丰富的语言和图像信息表示数据,」Raghu说,「而且比以前更深入。」
新兴项目表明了Transformer在其他AI领域的一系列新用途,包括教机器人识别人体运动、训练机器识别语音中的情绪以及检测心电图体现的患者压力程度。
另一个带有Transformer组件的程序是AlphaFold,2021年它因其快速预测蛋白质结构的能力而成为头条新闻——这项任务以前需要十年的时间深入分析。
即使Transformer可以有助于AI工具的融合和改进,新兴技术通常也会带来高昂的代价,Transformer也不例外。
Transformer在预训练阶段需要更高的算力支撑,然后才能发挥击败传统竞争对手的准确性。
Wang表示,人们总会对高分辨率图像越来越有兴趣。而由此带来的模型训练成本上涨,可能是Transformer广泛铺开的一个缺陷。
不过,Raghu认为此类训练障碍可以通过复杂的滤波器和其他工具轻松克服。
Wang还指出,尽管视觉Transformer已经引发了推动AI前进发展的新项目——包括他自己的项目在内,但许多新模型仍然包含了卷积功能的最精华部分。
这意味着未来的模型更有可能同时使用CNN与Transformer,而不是完全放弃CNN。而这预示了此类混合架构的诱人前景。
或许,我们不应该急于得出Transformer将成为最终模型的结论。
不过可以肯定的是,Transformer越来越有可能成为从业者常光顾的AI五金店里任何一种新的超级工具的必备组件。
参考资料:
https://www.quantamagazine.org/will-transformers-take-over-artificial-intelligence-20220310/
![]()