发布两个用于改进自然语言理解模型的新数据集
文 / Yuan Zhang, 研究员和 Yinfei Yang, 软件工程师, Google Research
-
Flights from New York to Florida. 从纽约飞往佛罗里达的航班。 -
Flights to Florida from New York. 从纽约飞往佛罗里达的航班。 Flights from Florida to New York. 从佛罗里达飞往纽约的航班。
三个句子均使用完全相同的单词。但第 1 句和第 2 句意思相同,称为 释义对 (Paraphrase Pairs);而第 1 句和第 3 句的意思截然不同,称为 非释义对 (Non-Paraphrase Pairs)。识别对应语句对是否为释义对的任务称为释义识别 (Paraphrase Identification),对自然语言理解 (Natural Language Understanding, NLU) 的实际应用(如问答系统)至关重要。
可能有些出乎意料,但如果仅在现有的数据集上训练,即使是 BERT 等最高水准 (SOTA) 模型也无法正确识别许多非释义对之间的差异(如上文中的第 1 句和第 3 句)。这是由于现有的数据集缺乏针对这种情况的训练数据。因此,即使能够理解复杂的上下文句式的机器学习模型,也很难理解此类任务。
为解决这一问题,我们发布两个新数据集以帮助社区进行相关研究:
-
PAWS (Paraphrase Adversaries from Word Scrambling) 英文数据集; PAWS-X 数据集,基于 PAWS 数据集并扩展为六种不同语言:法语、西班牙语、德语、中文、日语和朝鲜语。
两个数据集均包含结构完整、单词重叠度较高的句对,其中约有一半是释义对,而另一半是非释义对。通过在 SOTA 模型的训练数据中加入新数据,我们将算法的精确度从低于 50% 提升至 85-90%。
与之前相比,即便使用新的训练示例,无法获得非本地上下文信息的模型同样会训练失败。因此,新数据集也成为了测量模型对词序和单词结构敏感度的实用工具。
PAWS 数据集包含 108,463 个由人工标记的英文句对,这些数据来源于 Quora Question Pairs (QQP) 和维基百科。PAWS-X 包含 23,659 个由人工翻译的 PAWS 评估句对 (Evaluation Pairs) 和 296,406 个机器翻译的训练句对。下表列出了两个数据集的详细统计数据。
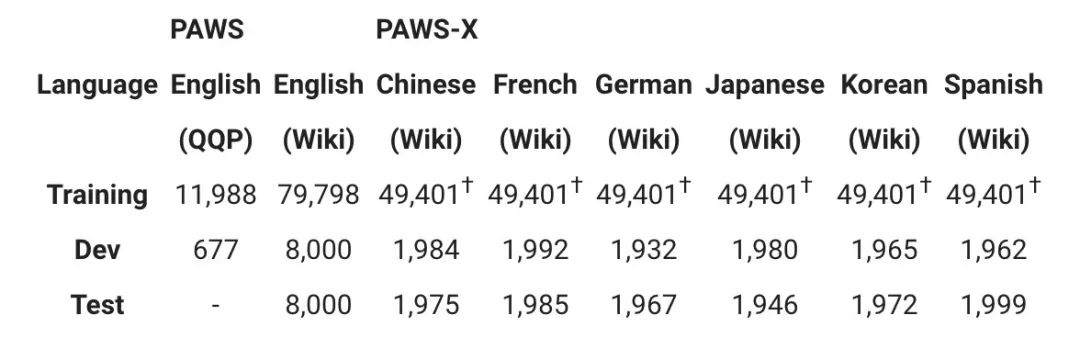
† PAWS-X 的训练集是 PAWS Wiki 英文数据集中某个子集的机器翻译
创建 PAWS 英文数据集
在 “PAWS:Paraphrase Adversaries from Word Scrambling” 中,我们介绍了一种生成句对的工作流程,可生成单词高度重叠,但释义对和非释义对的数量大约各占一半的句对。
首先将源语句传递给一个专用语言模型,模型通过交换具有语义的单词生成变体句。但无法保证新生成的变体句是否与原句为释义对,这时需要由人类测评员先判断句子语法是否正确,然后多名测评员判断这些句子是否为释义对。
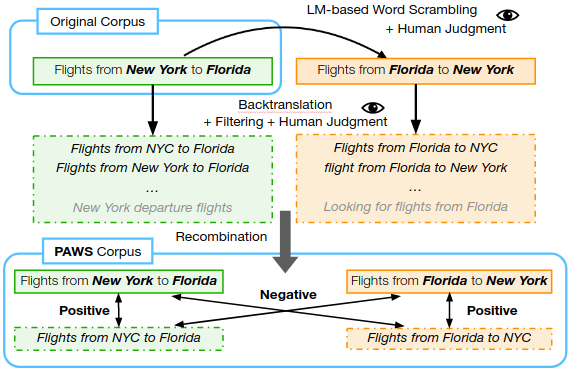
创建 PAWS 语料库的工作流
-
“Why do bad things happen to good people” 为什么坏事会发生在好人身上 “Why do good things happen to bad people” 为什么好事会发生在坏人身上
为确保释义对和非释义对之间的平衡,我们基于反向翻译 (Back-translation) 添加了一些数据。反向翻译与上述策略恰好相反,它在保留了句子原义的同时改变了词序和词汇选择。我们通过这两种策略让 PAWS 语料库够达到总体平衡,尤其是维基百科的数据。
创建 PAWS-X 多语言数据集
在创建 PAWS 后,我们将该数据集扩展为六种语言:中文、法语、德语、朝鲜语、日语和西班牙语。我们采用人工翻译来完成多语言扩展和测试集的翻译工作,并使用神经机器翻译 (Neural Machine Translation, NMT) 服务来翻译训练集。
针对六种语言中的每种语言,我们从 PAWS 扩展集中随机抽取了 4,000 个句对,然后针对抽取的数据集进行相应的人工翻译(均为母语翻译,共计 48,000 条)。句对中的每个句子均独立出现,这样翻译就不会受上下文的影响。然后由另一名工作人员验证一个随机抽取的子集。最终数据集的错误率低于 5%。
请注意,当句子不完整或语义模糊时,我们允许翻译人员不进行翻译。平均而言,未翻译的句对仅占不到 2%,我们将其排除。最后,我们将得到的翻译句对分为新的扩展集和测试集,每个集合约含 2,000 个句对。
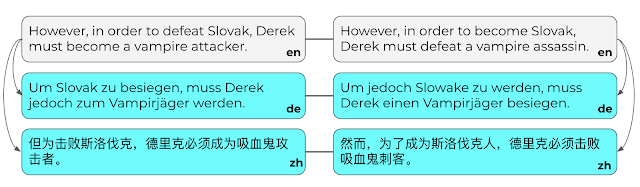
德语 (DE) 和中文 (ZH) 的人工翻译句对示例
使用 PAWS 和 PAWS-X 理解语言
我们在创建的数据集上训练多个模型,并测量评估集的分类精度。相较于现有的 Quora Question Pairs (QQP) 数据集,当使用 PAWS 进行训练时,BERT 和 DIIN 等稳健模型具有显著改进。
如针对来自 QQP (PAWS-QQP) 的 PAWS 数据,BERT 在现有的 QQP 数据集上只能获得 33.5 的精度,而当使用 PAWS 训练示例时,其精度可提升至 83.1。与 BERT 不同,简单的 Bag-of-Words (BOW) 模型无法从 PAWS 训练数据中进行学习,这也透露出该模型在捕获非本地上下文信息方面的缺陷。这些结果表明,PAWS 能够有效测出模型对词序和单词结构的敏感度。
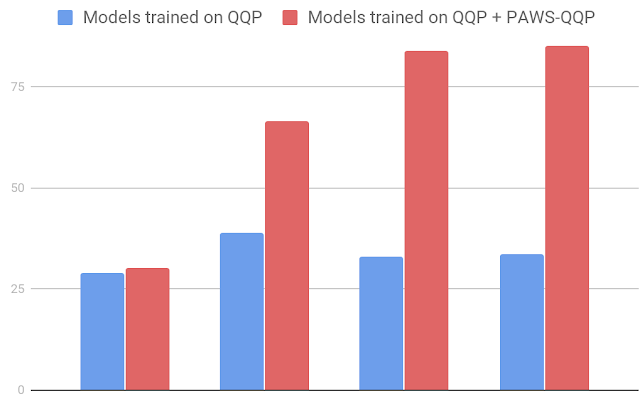
使用 PAWS-QQP 评估集(英文)的精度比较
-
零样本:使用 PAWS 英文训练数据训练模型,然后直接使用其他数据对其进行评估。该策略 不涉及 机器翻译。 -
翻译测试样本:使用英文训练数据训练模型,然后通过机器翻译将所有测试示例翻译成英文进行评估。 -
翻译训练样本:通过机器翻译将英文训练数据翻译成每种目标语言,从而为训练每种模型提供数据。 -
多语言样本:使用各种语言训练多语言模型,其中包括原始英文句对和所有其他语言的机器翻译数据。
结果表明,跨语言训练方法有一定帮助,同时也为释义识别问题的多语言研究留下了巨大发展空间。
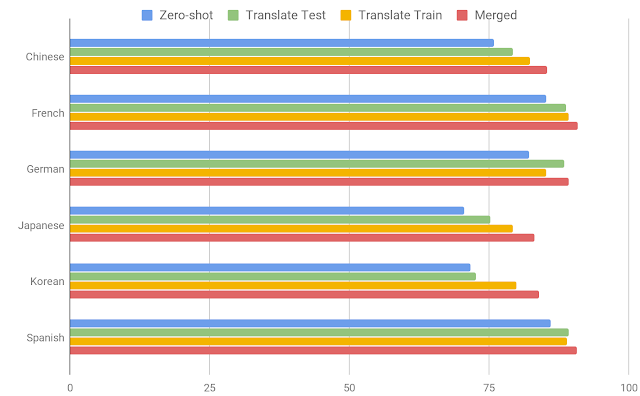
使用 BERT 模型的 PAWS-X 测试集精度
我们希望这些数据集能帮助研究社区进一步发展多语言模型,以便更好地针对句子结构、上下文和成对比较。
致谢
本次研究的核心团队成员包括 Luheng He、Jason Baldridge、Chris Tar。感谢 Google Research 的语言团队,特别是 Emily Pitler 对我们的论文提出的深刻见解。此外,也非常感谢 Ashwin Kakarla、Henry Jicha 和 Mengmeng Niu 在注释方面提供的帮助。
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
BERT
https://github.com/google-research/bert
https://arxiv.org/pdf/1810.04805PAWS: Paraphrase Adversaries from Word Scrambling
https://github.com/google-research-datasets/paws
https://arxiv.org/abs/1904.01130PAWS-X
https://github.com/google-research-datasets/paws/tree/master/pawsx单词重叠度
https://en.wikipedia.org/wiki/Lexical_similarity
Quora Question Pairs
https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs
语言模型
https://en.wikipedia.org/wiki/Language_model数据集扩展为六种语言
https://arxiv.org/abs/1908.11828神经机器翻译 (NMT) 服务
https://cloud.google.com/translateDIIN
https://arxiv.org/abs/1709.04348Bag-of-Words
https://en.wikipedia.org/wiki/Bag-of-words_model多语言 BERT
https://github.com/google-research/bert/blob/master/multilingual.md
更多 AI 相关阅读:





