黄仁勋:芯片每代性能都翻倍,而且下个「TensorFlow」级 AI 工具可是我英伟达出的。
每年春天,AI 从业者和游戏玩家都会期待英伟达的新发布,今年也不例外。
北京时间 3 月 22 日晚,新一年度的 GTC 大会如期召开,英伟达创始人、CEO 黄仁勋这次走出了自家厨房,进入元宇宙进行 Keynote 演讲:
![]()
「我们已经见证了 AI 在科学领域发现新药、新化合物的能力。人工智能现在学习生物和化学,就像此前理解图像、声音和语音一样。」黄仁勋说道「一旦计算机能力跟上,像制药这样的行业就会经历此前科技领域那样的变革。」
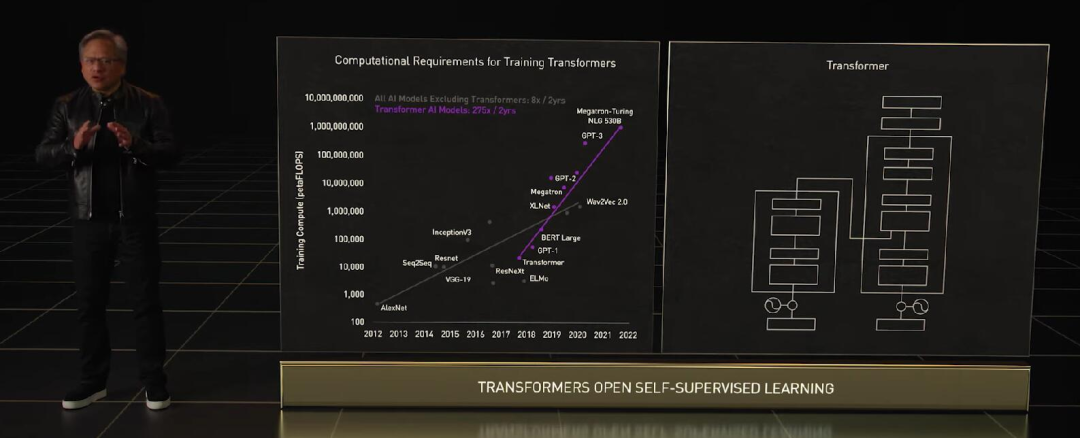
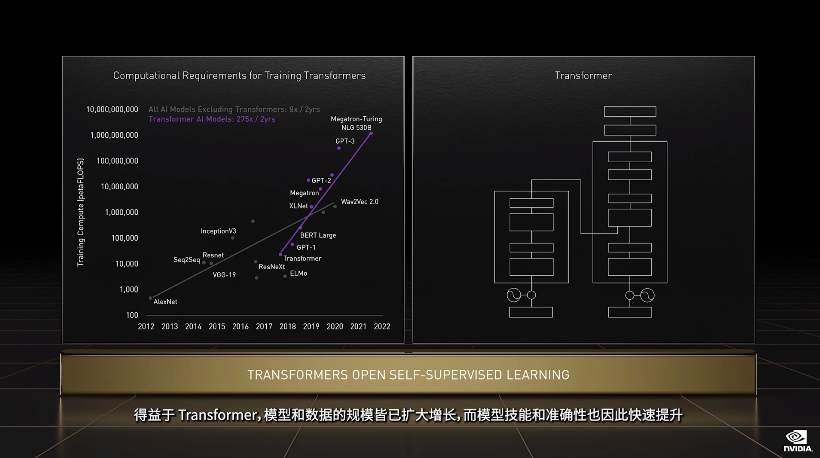
GPU 发展引爆的 AI 浪潮从开始到今天还没过去十年,Transformer 这样的预训练模型和自监督学习模型,已经不止一次出现「算不起」的情况了。
算力需求因为大模型呈指数级上升,老黄这次拿出的是面向高性能计算(HPC)和数据中心的下一代 Hopper 架构,搭载新一代芯片的首款加速卡被命名为 H100,它就是 A100 的替代者。
![]()
Hopper 架构的名称来自于计算机科学先驱 Grace Hopper,其延续英伟达每代架构性能翻倍的「传统」,还有更多意想不到的能力。
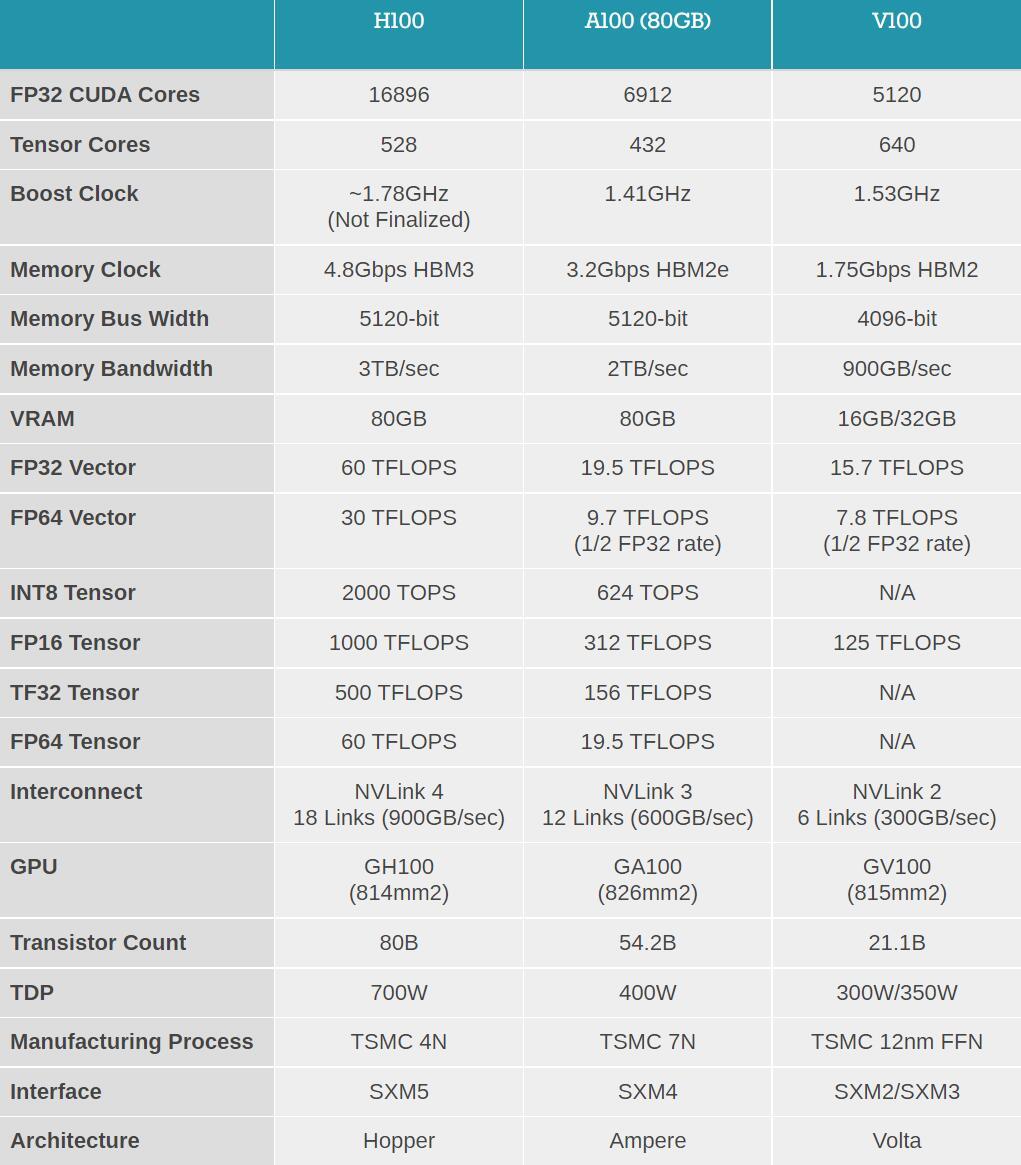
H100 使用台积电 5nm 定制版本制程(4N)打造,单块芯片包含 800 亿晶体管。它同时也是全球首款 PCI-E 5 和 HBM 3 显卡,一块 H100 的 IO 带宽就是 40 terabyte 每秒。
「为了形象一点说明这是个什么数字,20 块英伟达 H100 带宽就相当于全球的互联网通信,」黄仁勋说道。
黄仁勋列举了 Hopper 架构相对上代安培的五大革新:
首先是性能的飞跃式提升,这是通过全新张量处理格式 FP8 实现的。H100 的 FP8 算力是 4PetaFLOPS,FP16 则为 2PetaFLOPS,TF32 算力为 1PetaFLOPS,FP64 和 FP32 算力为 60TeraFLOPS。
虽然比苹果 M1 Ultra 的 1140 亿晶体管数量要小一些,但 H100 的功率可以高达 700W——上代 A100 还是 400W。「在 AI 任务上,H100 的 FP8 精度算力是 A100 上 FP16 的六倍。这是我们历代最大的性能提升,」黄仁勋说道。
Transformer 类预训练模型是当前 AI 领域里最热门的方向,英伟达甚至以此为目标专门优化 H100 的设计,提出了 Transformer Engine,它集合了新的 Tensor Core、FP8 和 FP16 精度计算,以及 Transformer 神经网络动态处理能力,可以将此类机器学习模型的训练时间从几周缩短到几天。
Transformer 引擎名副其实,是一种新型的、高度专业化的张量核心。简而言之,新单元的目标是使用可能的最低精度来训练 Transformer 而不损失最终模型性能。
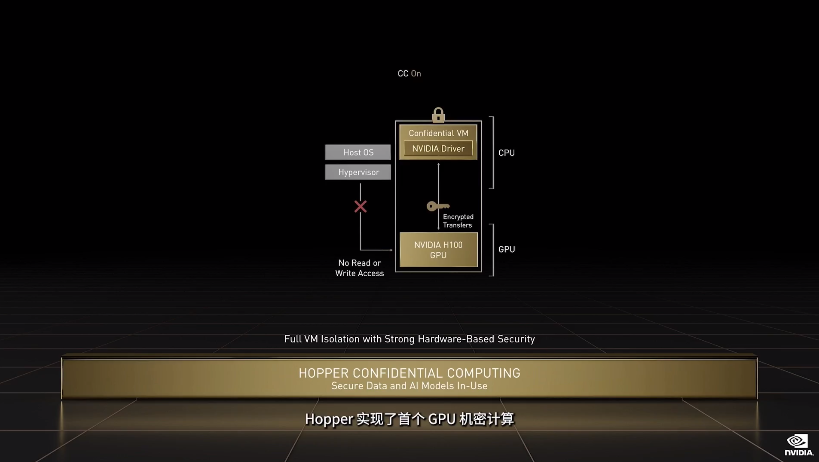
针对服务器实际应用,H100 也可以虚拟化为 7 个用户共同使用,每个用户获得的算力相当于两块全功率的 T4 GPU。而且对于商业用户来说更好的是,H100 实现了业界首个基于 GPU 的机密计算。
Hopper 还引入了 DPX 指令集,旨在加速动态编程算法。动态编程可将复杂问题分解为子问题递归解决,Hopper DPX 指令集把这种任务的处理时间缩短了 40 倍。
Hopper 架构的芯片和 HBM 3 内存用台积电 CoWoS 2.5D 工艺封装在板卡上,形成「超级芯片模组 SXM」,就是一块 H100 加速卡:
这块显卡拿着可得非常小心——它看起来整体异常紧凑,整个电路板上塞满各种元器件。另一方面,这样的结构也适用于液冷——H100 设计 700W 的 TDP 已经非常接近散热处理的上限了。
「科技公司处理、分析数据,构建 AI 软件,已经成为智能的制造者。他们的数据中心就是 AI 的工厂,」黄仁勋说道。
基于 Hopper 架构的 H100,英伟达推出了机器学习工作站、超级计算机等一系列产品。8 块 H100 和 4 个 NVLink 结合组成一个巨型 GPU——DGX H100,它一共有 6400 亿晶体管,AI 算力 32 petaflops,HBM3 内存容量高达 640G。
![]()
新的 NVLINK Swith System 又可以最多把 32 台 DGX H100 直接并联,形成一台 256 块 GPU 的 DGX POD。
「DGX POD 的带宽是每秒 768 terbyte,作为对比,目前整个互联网的带宽是每秒 100 terbyte,」黄仁勋说道。
基于新 superPOD 的超级计算机也在路上,英伟达宣布基于 H100 芯片即将自建一个名叫 EoS 的超级计算机,其由 18 个 DGX POD 组成,一共 4608 个 H100 GPU。以传统超算的标准看,EoS 的算力是 275petaFLOPS,是当前美国最大超算 Summit 的 1.4 倍,Summit 目前是基于 A100 的。
从 AI 计算的角度来看,EoS 输出 18.4 Exaflops,是当今全球第一超算富岳的四倍。
总而言之,EoS 将会是世界上最快的 AI 超级计算机,英伟达表示它将会在几个月之后上线。
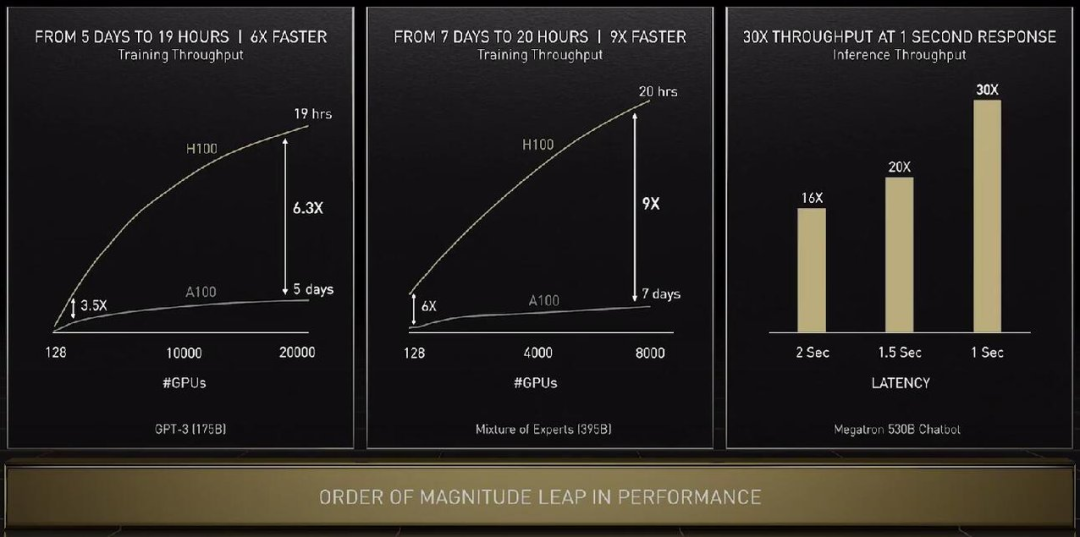
下面看看 H100 在具体任务上的性能提升:单看 GPU 算力的话训练 GPT-3 速度提升 6.3 倍,如果结合新的精度、芯片互联技术和软件,提升增至 9 倍。在大模型的推理工作上,H100 的吞吐量是 A100 的 30 倍。
对于传统服务器,英伟达提出了 H100 CNX,通过把网络与 H100 直接并联的方式绕过 PCIE 瓶颈提升 AI 性能。
英伟达更新了自家的服务器 CPU,新的 Grace Hopper 可以在同一块主板上两块并联,形成一个拥有 144 核 CPU,功耗 500W,是目前产品性能的 2-3 倍,能效比也是两倍。
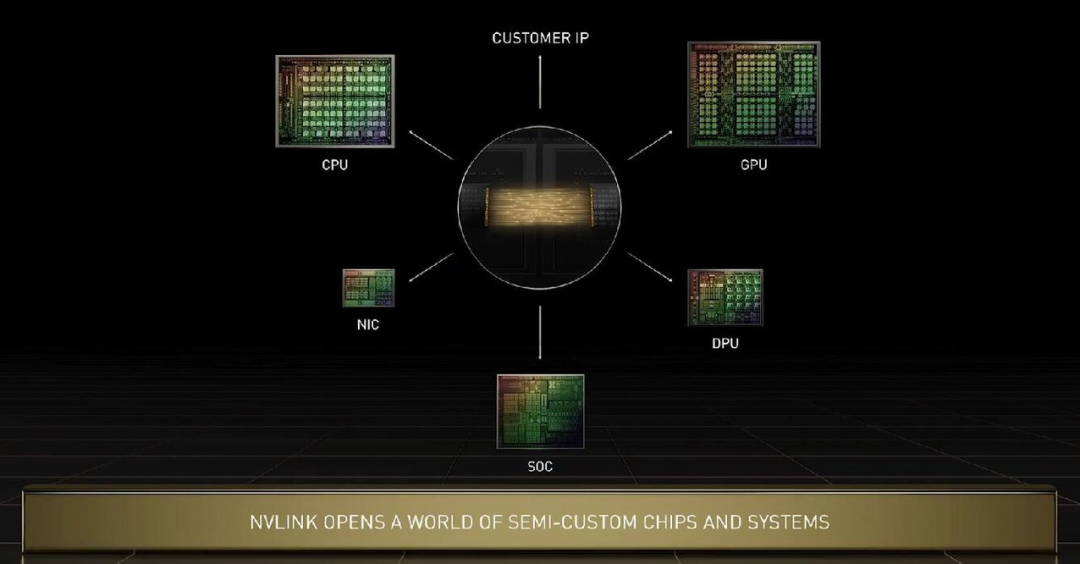
在 Grace 上,几块芯片之间的互联技术是新一代 NVlink,其可以实现晶粒到晶粒、芯片到芯片、系统到系统之间的高速互联。黄仁勋特别指出,Grace CPU 与 Hopper 可以通过 NVlink 进行各种定制化配置。英伟达的技术可以满足所有用户需求,在未来英伟达的 CPU、GPU、DPU、NIC 和 SoC 都可以通过这种技术实现芯片端高速互联。
英伟达计划在今年三季度推出配备 H100 的系统,包括 DGX、DGX SuperPod 服务器,以及来自 OEM 合作伙伴使用 HGX 基板和 PCIe 卡服务器。
至于价格,昨天老黄并没有说「the more you buy, the more you save.」
此前有传闻说专用于游戏的 Ada Lovelace 架构,昨天并没有出现在黄仁勋的 keynote 中,看来还要再等等。
「第一波 AI 学习了生物的预测推断能力,如图像识别、语言理解,也可以向人们推荐商品。下一波 AI 将是机器人:AI 做出计划,在这里是数字人、物理的机器人进行感知、计划并行动,」黄仁勋说道。「TensorFlow 和 PyTorch 等框架是第一波 AI 必须的工具,英伟达的 Omniverse 是第二波 AI 的工具,将会开启下一波 AI 浪潮。」
在元宇宙这件事上,英伟达可以说一直走在最前面,其提出的 Omniverse 是连接所有元宇宙的门户。但在以往,Omniverse 是面向数据中心设计的,其中的虚拟世界偏向于工业界。
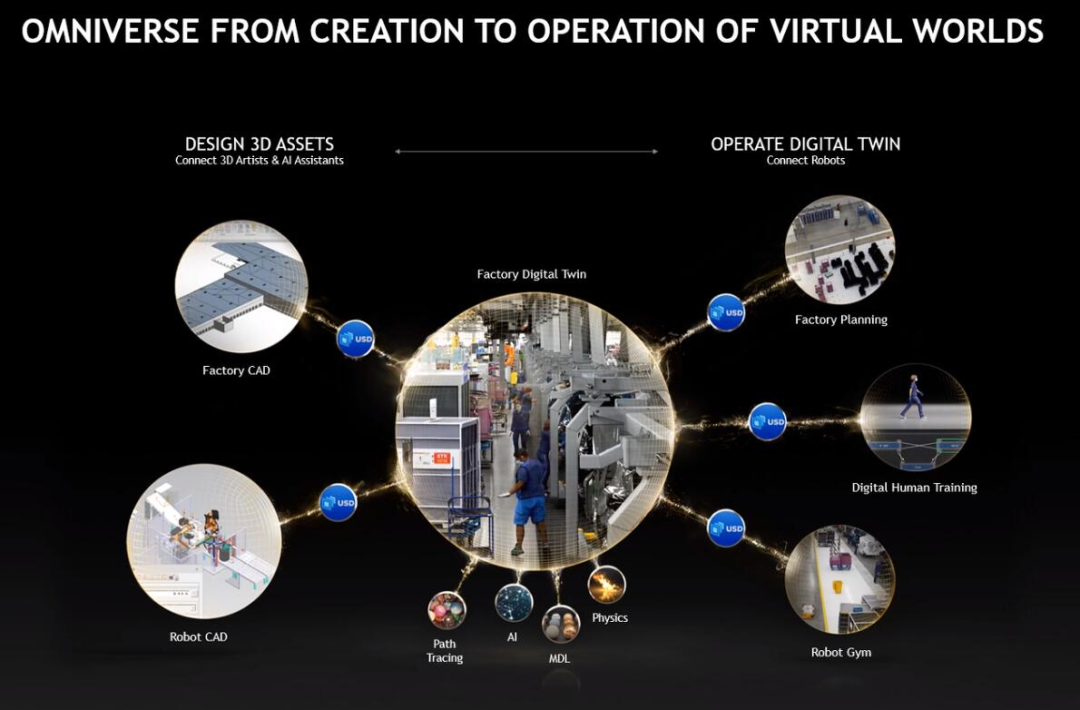
黄仁勋表示,英伟达的 Omniverse 涵盖了数字孪生、虚拟世界和互联网的下一次演进。下图为几种典型应用场景:
而对于数字孪生而言,Omniverse 软件和计算机必须具备可扩展、低延迟和支持精确时间的特点。所以,创建同步的数据中心非常重要。基于此,英伟达推出了 NVIDIA OVX——用于工业数字孪生的数据中心可扩展 Omniverse 计算系统。
第一代 NVIDIA OVX Omniverse 计算机由 8 个 NVIDIA A40 GPU、3 个 NVIDIA ConnectX-6 200 Gbps 网卡、2 个 Intel Ice Lake 8362 CPU 以及 1TB 系统内存和 16TB NVMe 存储组成。
然后,英伟达利用 Spectrum-3 200 Gpbs 交换机连接 32 台 OVX 服务器构成了 OVX SuperPOD。
目前,全球各大计算机制造商纷纷推出 OVX 服务器。第一代 OVX 正由英伟达和早期客户运行,第二代 OVX 也正从骨干网络开始构建当中。会上,英伟达宣布推出带宽高达 51.2Tbps 且带有 1000 亿个晶体管的 Spectrum-4 交换机,它可以在所有端口之间公平分配带宽,提供自适应路由和拥塞控制功能,显著提升数据中心的整体吞吐量。
凭借 ConenctX-7 和 BlueField-3 适配器以及 DOCA 数据中心基础架构软件,Spectrum-4 成为世界上第一个 400Gbps 的端到端网络平台。与典型数据中心数毫秒的抖动相比,Spectrum-4 可以实现纳秒级计时精度,即 5 到 6 个数量级的改进。黄仁勋表示,样机预计将于第四季度末发布。
![]()
说到元宇宙,则不得不提英伟达 Omniverse Avatar 平台。在本次 GTC 大会上,黄仁勋与「自己」(虚拟人)展开了一番对话。
![]()
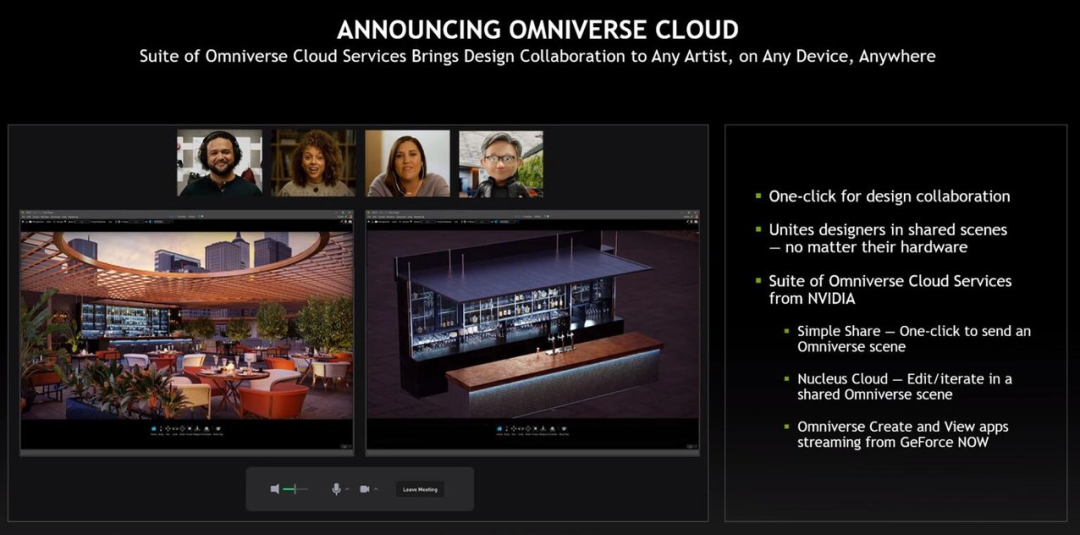
同时,英伟达还希望 Omniverse 为设计师、创作者、AI 研究人员提供帮助,因而推出了 Omniverse Cloud。只需点击几下,用户及其协作者可以完成连接。使用 NVIDIA RTX PC、笔记本电脑和工作站,设计师们可以实时协同工作。即使没有 RTX 计算机,他们也可以从 GeForce Now 上一键启动 Omniverse。
比如下图中远程工作的几位设计师在网络会议中使用 Omniverse View 来评审项目,他们可以连接彼此,并唤出一个 AI 设计师。也即是,他们通过 Omniverse Cloud 协作创建了一个虚拟世界。
在这场 GTC 大会上,黄仁勋打开了元宇宙的大门。
![]()
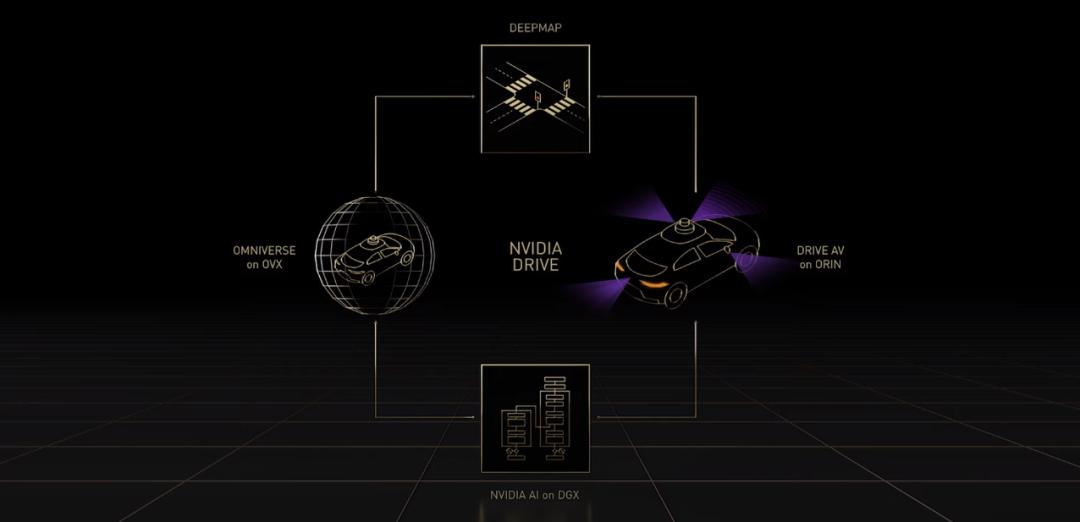
既然机器人系统会是下一波 AI 浪潮,黄仁勋表示,英伟达正在构建多个机器人平台——用于自动驾驶汽车的 DRIVE、用于操纵和控制系统的 ISAAC、用于自主式基础架构的 Metropolis 和用于机器人医疗器械的 Holoscan。这里只介绍 DRIVE 自动驾驶汽车系统。
机器人系统的工作流程很复杂,通常可以简化为四个支柱:收集和生成真值数据、创建 AI 模型、使用数字孪生进行仿真和操作机器人。Omniverse 是整个工作流程的核心。
DRIVE 自动驾驶汽车系统本质上是「AI 司机」。与其他平台一样,NVIDIA DRIVE 是全栈式端到端平台,对开发者开放,他们可以使用整个平台或者其中一部分。在运行过程中,英伟达使用 DeepMap 高清地图等收集和生成真值数据,使用 DGX 上的 NVIDIA AI 来训练 AI 模型。Omniverse 中的 DRIVE Sim 在 OVX 上运行,它属于数字孪生。DRIVE AV 是一款运行在车载 Orin 计算平台上的自动驾驶应用。
在使用最新版 DRIVE 系统的实际行驶中,驾驶员可以启动 DRIVE Pilot 导航,语音输入指令。信心视图(Confidence View)向车上的人展示汽车看到和打算要做的事。AI 助手可以探测到特定的人,多模态 AI 助手可以回答驾驶员的问题,AI 辅助停车可以检测可用的停车位,环绕视图(Surround View)和高级可视化(Advanced Visualization)方便驾驶员泊车。
![]()
所有这一切都离不开英伟达自动驾驶汽车硬件结构——Hyperion 8,它也是整个 DRIVE 平台的构建基础。Hyperion 8 是由多个传感器、网络、两台 Chauffeur AV 计算机、一台 Concierge AI 计算机、一个任务记录仪以及(网络)安全系统组成。它可以使用 360 度摄像头、雷达、激光雷达和超声波传感器套件实现全自动驾驶,并将分别从 2024 年起在梅赛德斯奔驰汽车、2025 年起在捷豹路虎汽车中搭载。
![]()
DRIVE Sim 中构建的 Hyperion 8 传感器可以提供真实世界的视图。
今天,英伟达宣布 Hyperion 9 将从 2026 年起在汽车上搭载。相较于前代,Hyperion 9 将拥有 14 个摄像头、9 个雷达、3 个激光雷达和 20 个超声传感器。整体而言,它处理的传感器数据量是 Hyperion 8 的两倍。
在电动汽车领域,英伟达 DRIVE Orin 是理想汽车的集中式自动驾驶和 AI 计算平台。黄仁勋在会上宣布,Orin 将于本月发售。不仅如此,比亚迪也将为 2023 年上半年投产的电动汽车搭载英伟达 DRIVE Orin 系统。
「Omniverse 在英伟达 AI 和机器人领域的工作中非常重要,下一波 AI 浪潮需要这样的平台,」黄仁勋最后说道。
参考内容:
https://www.anandtech.com/show/17327/nvidia-hopper-gpu-architecture-and-h100-accelerator-announced
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com