如果你有 100 万个 GPU hour,你会训练什么样的语言模型?
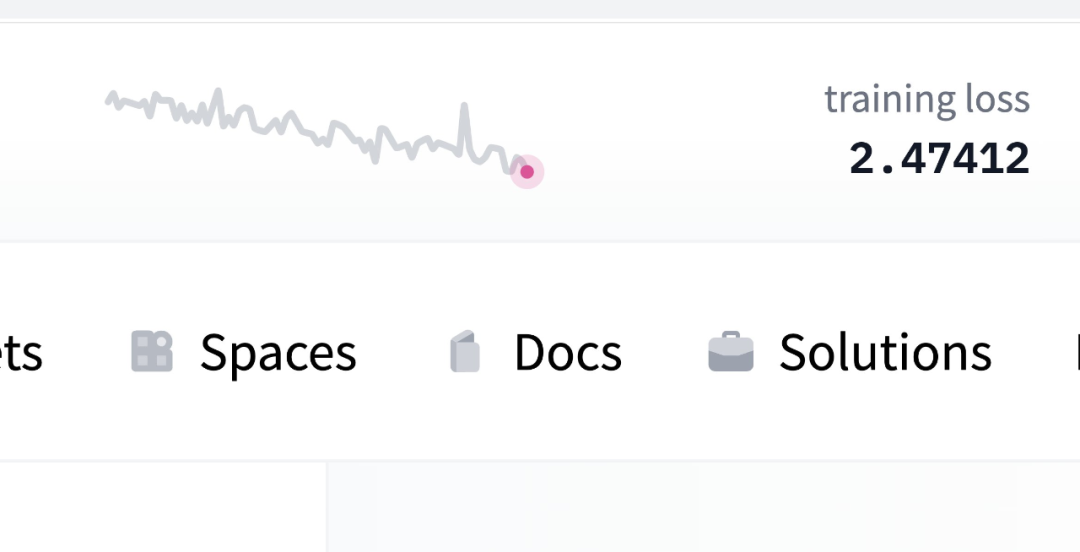
到昨天为止,大模型「BigScience」已训练了 5%。
![]()
这个模型仅 bf16 权重就有 329GB,正在用 384 块 A100 进行训练,吞吐量每秒约 150TFLOPS。
![]()
与很多公司未开源大模型不同的是,BigScience 模型训练的参数所有人都可见,根据项目组织者的预测,距离完成目标还有三个月的时间。
人工智能给人类社会带来了根本性的影响,但与互联网的兴起不同,AI 极度依赖在更大的数据集上训练更大的模型。因此,这场科技变革的资源主要掌握在大型科技巨头手中。从研究进展、环境、伦理和社会影响的角度看,这种现状给 AI 技术造成了束缚。例如,外界无法访问训练数据集或检查点,这使得其他研究者无法确切分析模型的能力、局限性、潜在改进、偏见等重要方面。
从 2021 年 5 月到 2022 年 5 月,在(预计)长达一年的时间里,来自 60 个国家和 250 多个机构的 900 名研究人员正在共同创建一个非常大的多语言神经网络模型和一个非常大的多语言文本数据集,并在算力 28 petaflops 的法国 Jean Zay (IDRIS) 核电超级计算机上运行。这个项目被命名为 BigScience。
开放的科学合作是其他学科领域已获成功的研究模式,已有多个对全世界有益的大型共享研究中心,例如欧洲核子研究中心 CERN。
类似地,BigScience 项目旨在以一种新的方式在 AI/NLP 研究社区中创建、研究和共享大型语言模型,探索大模型的新型合作模式。围绕 BigScience 项目创建的大型研究社区将能够提前探索超大型语言模型的许多研究问题(能力、局限性、潜在改进、偏见、通用人工智能等),并展开学术讨论,促进科技的发展。
简单来说,BigScience 模型是一个 1760 亿参数的多语言模型,它有以下特点:
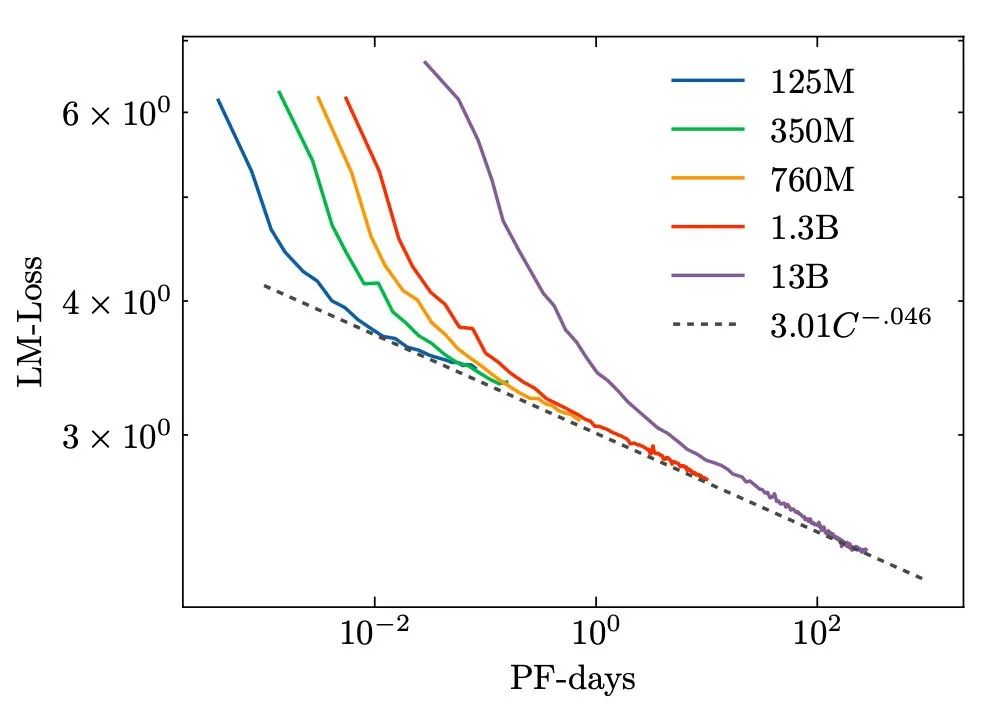
首先,研究者推导出扩展定律,计算了能提供的「最佳」模型上限:从 ~1650 亿的数据 token 中训练 ~3920 亿参数。
但是扩展定律没有考虑服务 / 推理成本、下游任务性能等。此外,该研究还需要确保低资源语言在预训练期间仍然获得足够多的 token。研究者不希望 BigScience 模型需要对整个语言进行零样本学习,因此他们决定至少应该预训练 3000-4000 亿 个 token。
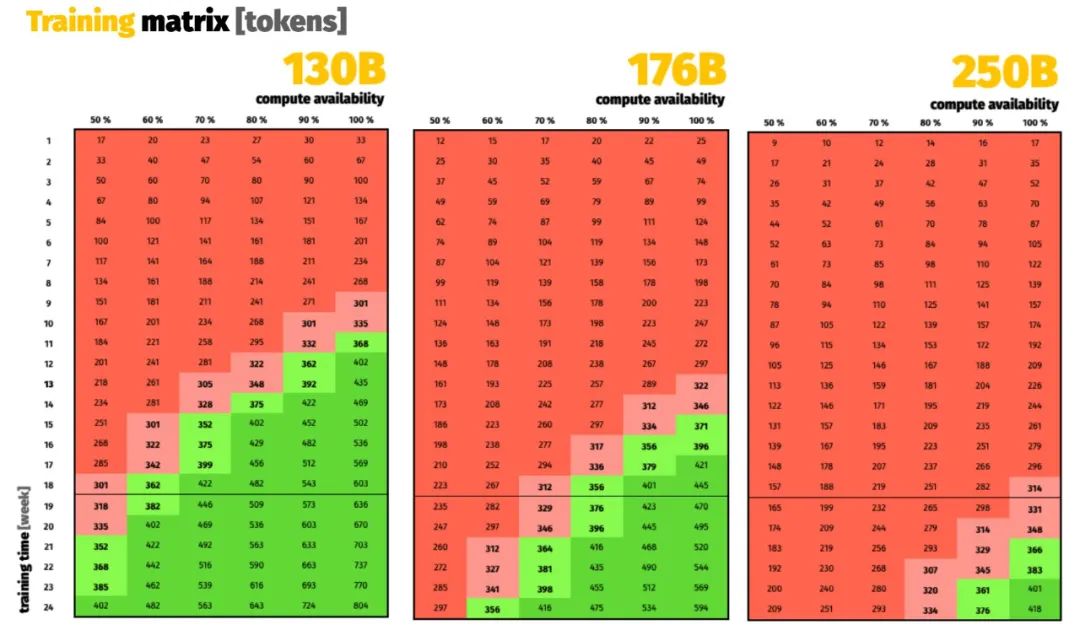
回到预算:法国国家大型计算中心 GENCI 在超级计算机 Jean Zay 上为项目提供了 384 块英伟达 A100 80GB 的 18 周时间,即 1161261 个 A100-hour!
值得一提的是,Jean Zay 是法国在 2019 年建成的超级计算机,硬件由惠普供货,2020 年扩容后峰值性能达到 28 Pflops/s。由于接入法国电网,这台超算是由核电站供能的。为了将训练对环境的影响进一步降低,他们甚至将硬件产生的热量用于校园建筑的供暖。
在正式开发之前,研究者评估了适合训练的模型大小,并考虑了系统的安全方面。最后的评估结果即:~1750 亿参数的模型,其对应的 token 量有机会达到甚至超过 4000 亿。
![]()
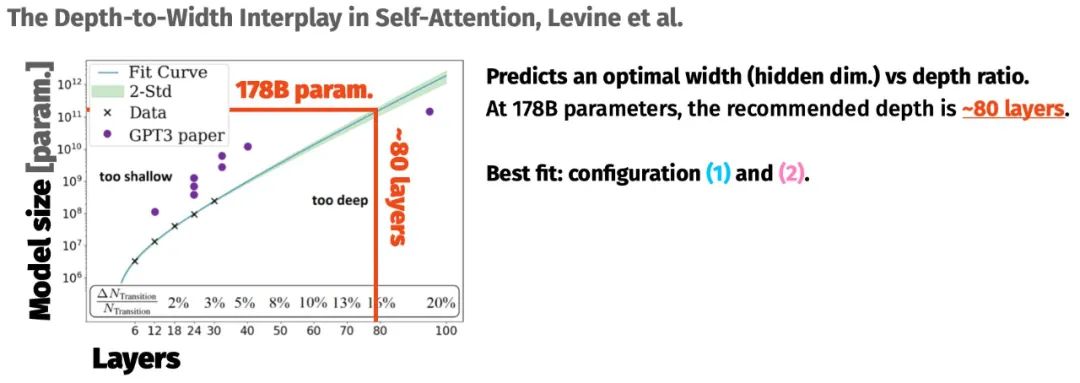
在训练之前,研究者分析了其他超过 1000 亿参数的大模型是如何形成的。对于模型体量如何随规模增加而变化,也有很多研究可以参考:特别是 Kaplan 等人(2020 年)和 Levine 等人(2020 年)的研究。
![]()
![]()
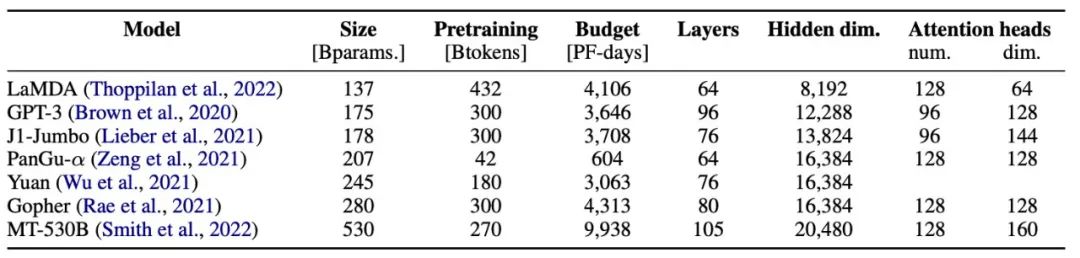
最后,BigScience 的杰出工程师 Stas Bekman 对数百种配置进行了基准测试,以找到最快的配置。你可以在其网站中阅读更多相关信息。这一切都是为了找到一组 magic number,避免诸如 tile / 波量化之类的影响。
项目最终获取了三个有希望的配置,首先排除(1),因为注意力头过大,最终选择(3)是因为它比(2)快。速度很重要:每增加一点吞吐量就意味着更多的总计算量,能够带来更多的预训练 token,并形成更好的模型。
![]()
此外,BigScience 模型在检查点方面,仅 bf16 权重就有 329GB,具有优化器状态的完整检查点有 2.3TB。
BigScience 的 1760 亿参数大模型训练始于美国西海岸时间 2022 年 3 月 11 日上午 11 点 42 分。
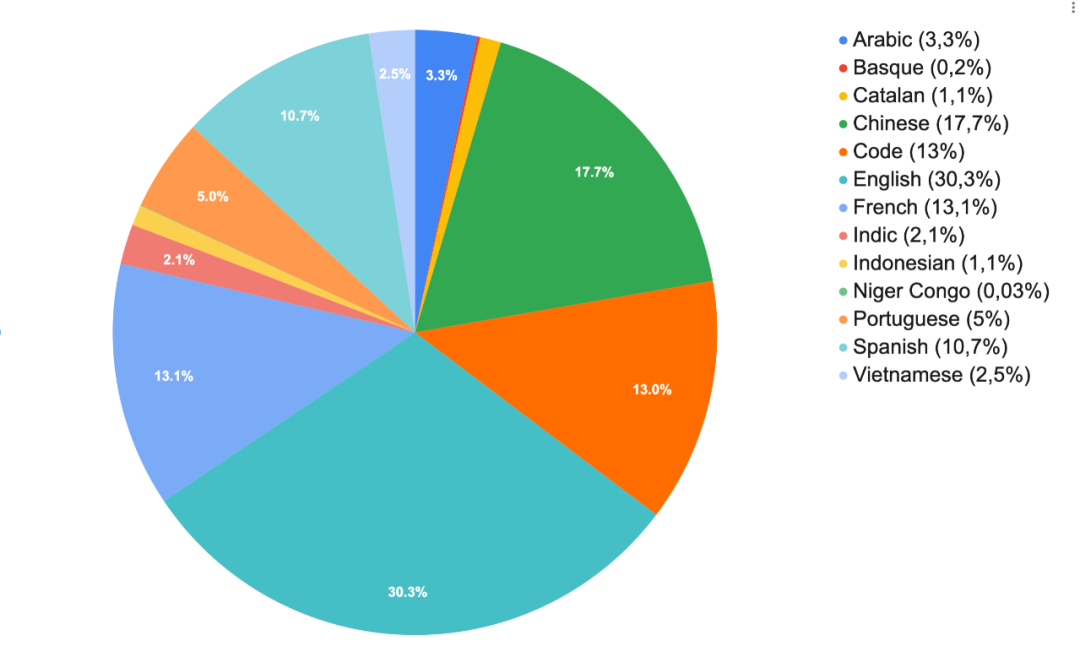
这个项目要用到一个 TB 级的多语言数据集,包含 1.5 TB(3500 亿 token)的文本数据。这个数据量是什么概念呢?如果你把它打印到 A4 纸上,这些纸可以堆成 141 座埃菲尔铁塔或 5 座珠穆朗玛峰。
![]()
为了构建这个数据集,项目组成员分工完成了以下工作:
数据治理小组帮助定义了指导数据工作的具体价值,并提出了一个新的国际数据治理结构,包括一些支持性的技术和法律工具;
数据来源小组在全球范围内组织黑客松,帮助参与者利用当地专业知识建立了 246 种语言资源目录,并准备了 605 个相关网站的列表;
隐私工作小组致力于分类和策略,以降低隐私风险;
法律学术小组开发了一套涵盖九个司法管辖区的法律手册,其中包含不同的隐私和数据保护法规,以帮助 ML 从业者了解他们工作的法律背景。
由于数据规模过大,使用自动方法来对整个语料库进行自动筛选所带来的影响将非常不可控,同时,通过手动检查数据样本来获得良好的洞察也是一大挑战。为了应对这些挑战,并提高数据选择过程的可理解性和可说明性,项目人员在工作中优先考虑了以下方法:
1、构建支持大规模人工决策的工具,而不是完全自动化,在手动和自动之间找到一个平衡点。
2、更少的语言,更多的语言专业知识。将精力集中在能够投入足够资源的语言和语言组上。
![]()
以下博文介绍了关于该数据集的更多细节:https://bigscience.huggingface.co/blog/building-a-tb-scale-multilingual-dataset-for-language-modeling
最后,关注这个项目的同学可以查看以下账户的直播信息:https://twitter.com/BigScienceLLM
参考链接:https://www.reddit.com/r/MachineLearning/comments/tfm7zb/n_live_and_open_training_of_bigsciences_176b/
时在中春,阳和方起——机器之心「AI科技年会」
机器之
心AI科技年会将于3月23日在线上
举办
,本次活动分为三场论坛:
-
「人工智能论坛」直播间:
http://live.bilibili.com/3519835
-
「AI x Science 论坛」直播间:
http://live.bilibili.com/24531944
-
「首席智行官大会」直播间:
https://live.bilibili.com/24532108
人工智能论坛关注高性能计算、联邦学习、系统机器学习、强化学习、CV与NLP发展、RISC-V等。
AI x Science论坛关注AI与蛋白质、生物计算、数学、物理、化学、新材料和神经科学等领域的交叉研究进展。
首席智行官大会关注智能汽车、汽车机器人、无人驾驶商业化、车规级芯片和无人物流等。
点击阅读原文,查看全部日程。
欢迎大家加入本次年会交流群,就感兴趣的话题进行讨论和交流:关注下方服务号-点击菜单即可扫码入群。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com