7 Papers & Radios | 微软亚研麻将AI「Suphx」技术细节;港中文、商汤动作识别时序金字塔网络
参与:杜伟、楚航、罗若天
本周的重要论文有微软麻将 AI 研究团队公布 Suphx 所有技术细节,以及港中文联合商汤科技推出的特征级通用时序金字塔网络。
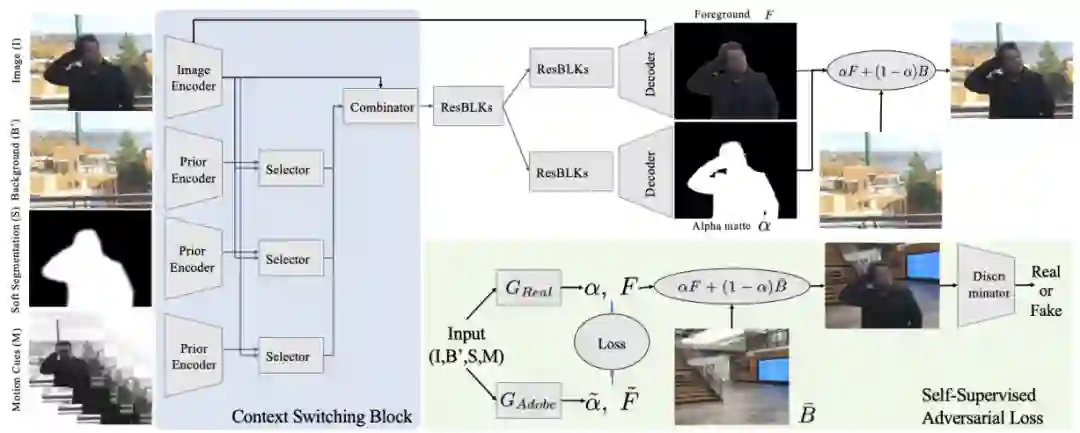
Background Matting: The World is Your Green Screen
Suphx: Mastering Mahjong with Deep Reinforcement Learning
A mountable toilet system for personalized health monitoring via the analysis of excreta
Weakly-Supervised Reinforcement Learning for Controllable Behavior
Evolving Normalization-Activation Layers
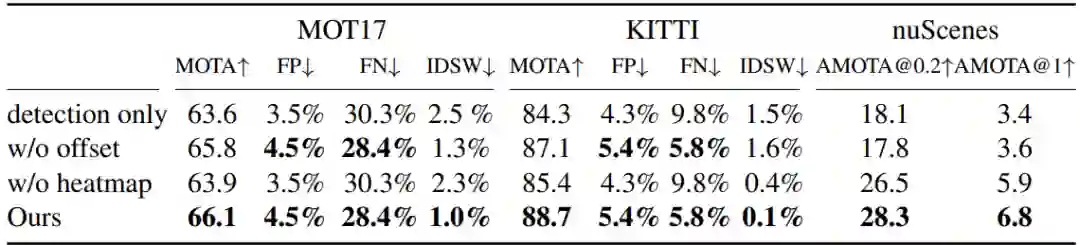
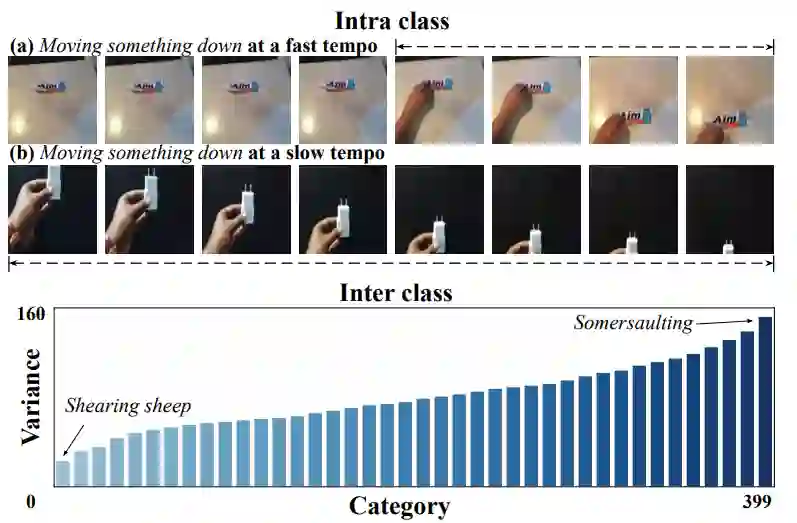
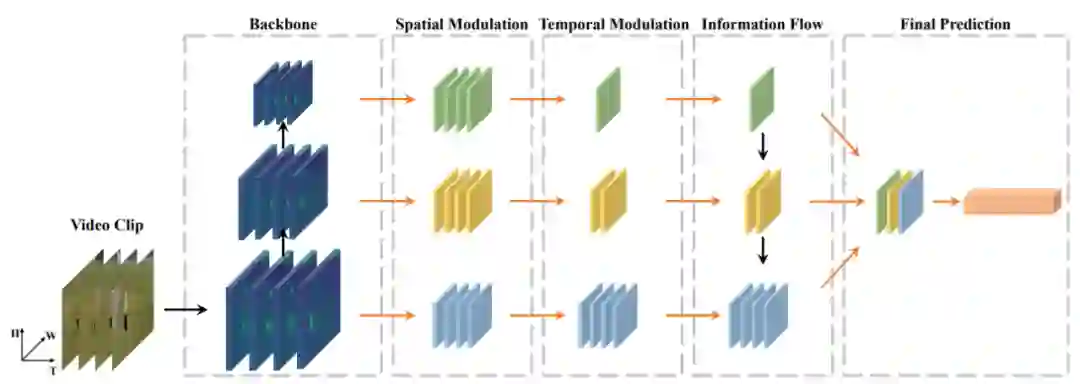
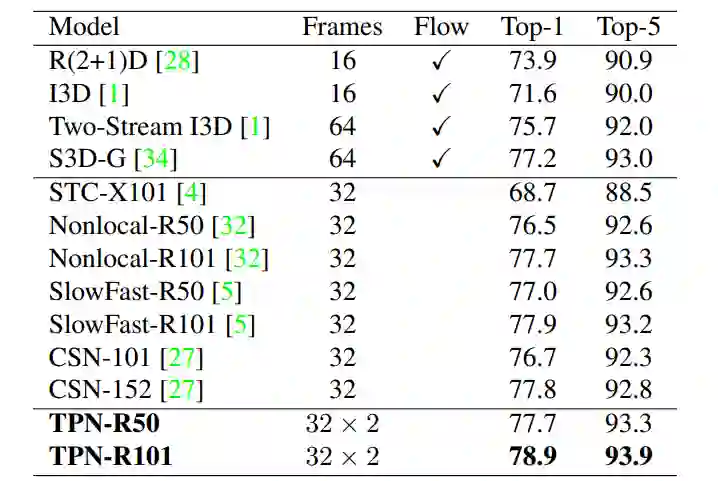
Temporal Pyramid Network for Action Recognition
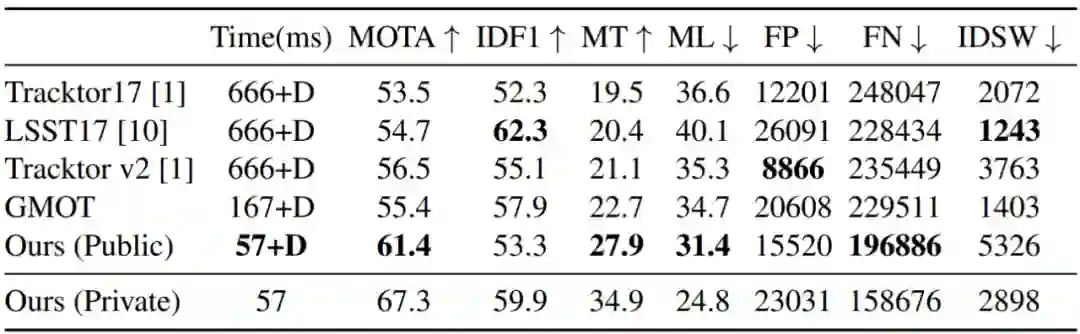
Tracking Objects as Points
ArXiv Weekly Radiostation:NLP、CV、ML更多精选论文(附音频)
作者:Soumyadip Sengupta、Vivek Jayaram、Ira Kemelmacher-Shlizerman 等
论文链接:https://arxiv.org/pdf/2004.00626.pdf
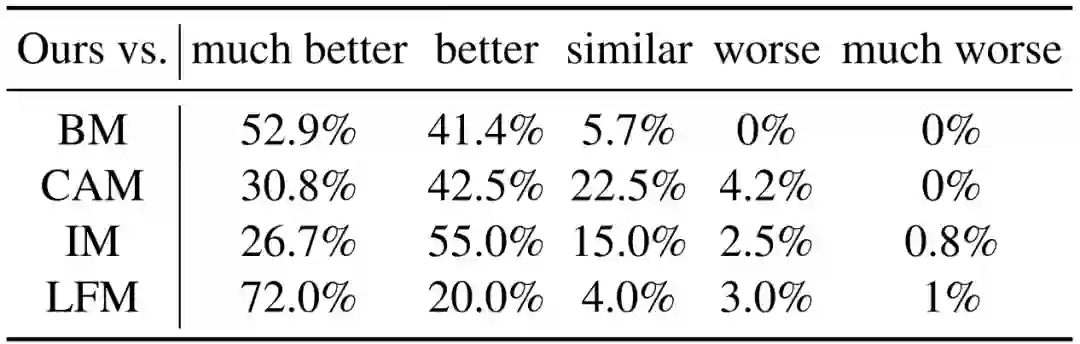
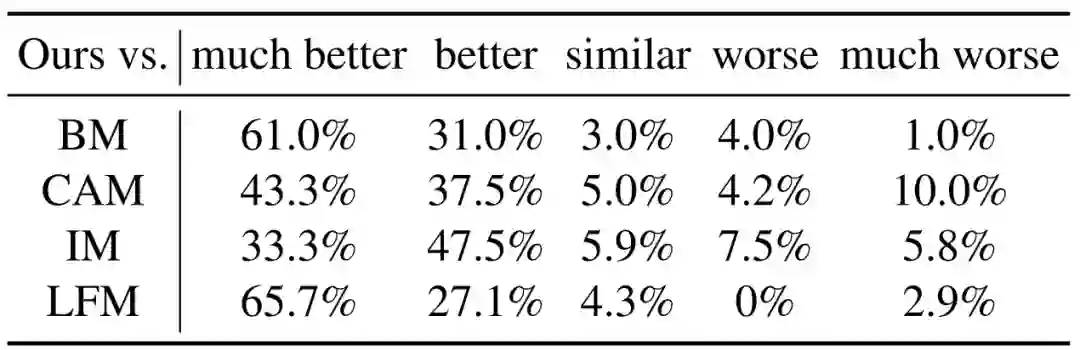
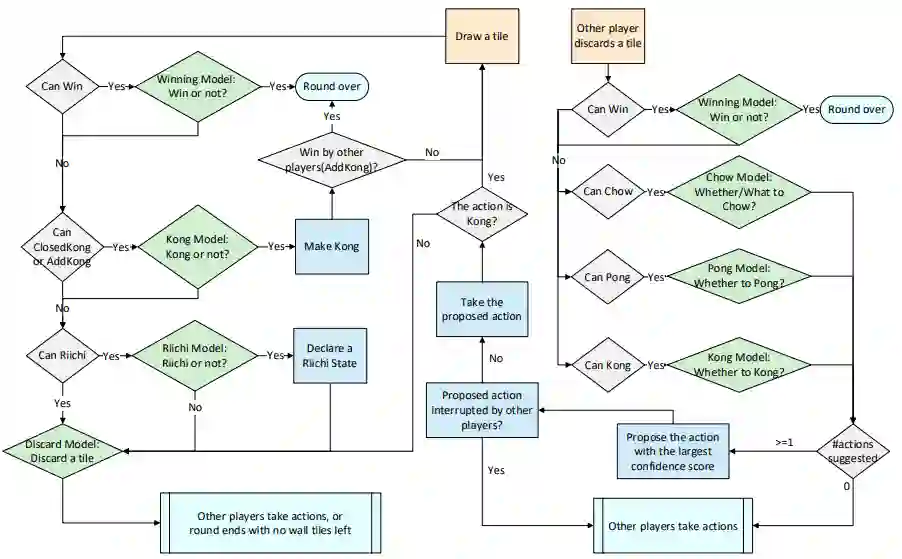
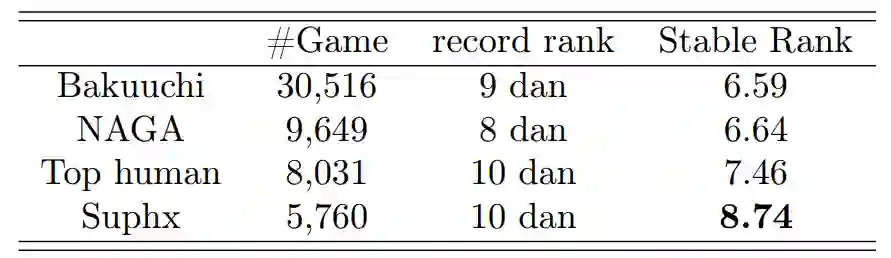
作者:Junjie Li、 Sotetsu Koyamada、Hsiao-Wuen Hon 等
论文链接:https://arxiv.org/pdf/2003.13590.pdf

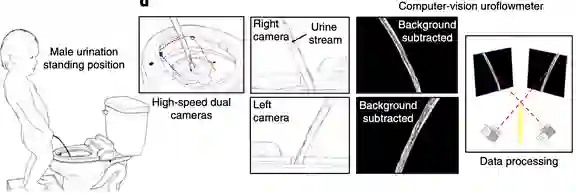
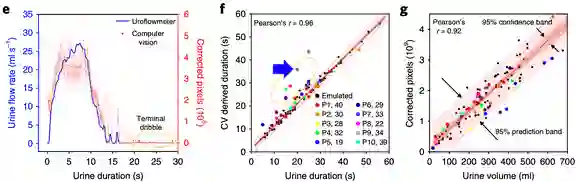
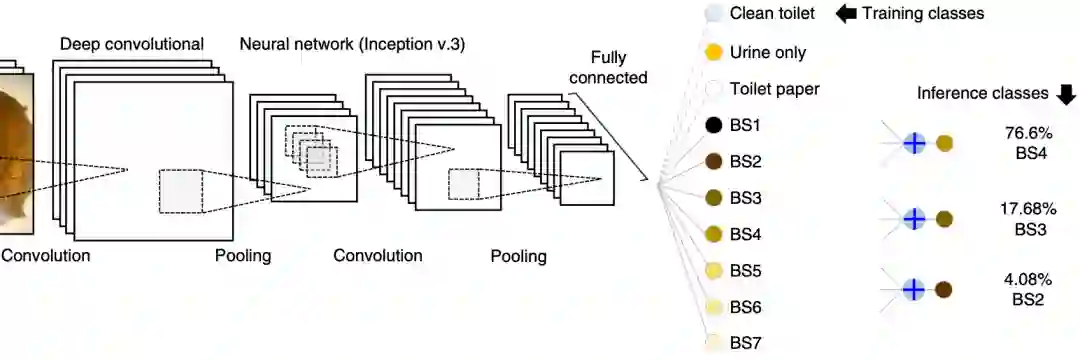
作者:Seung-min Park、Daeyoun D. Won、Sanjiv S. Gambhir 等
论文链接:https://www.nature.com/articles/s41551-020-0534-9
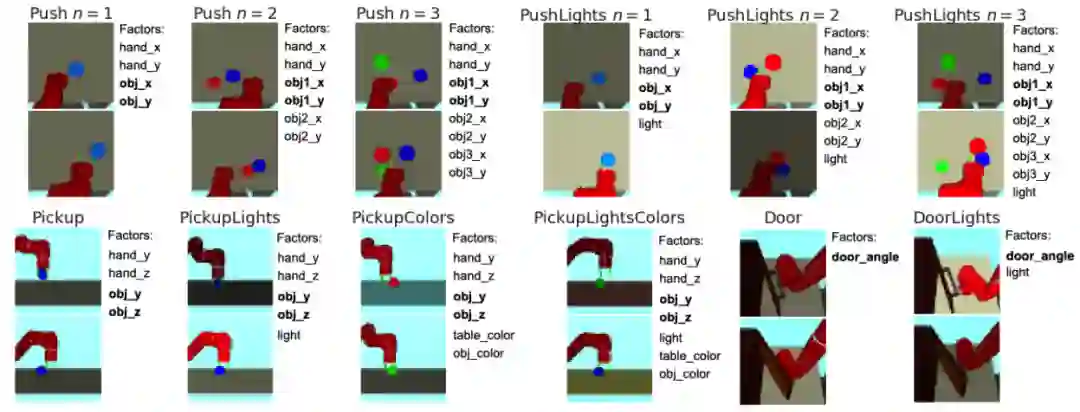
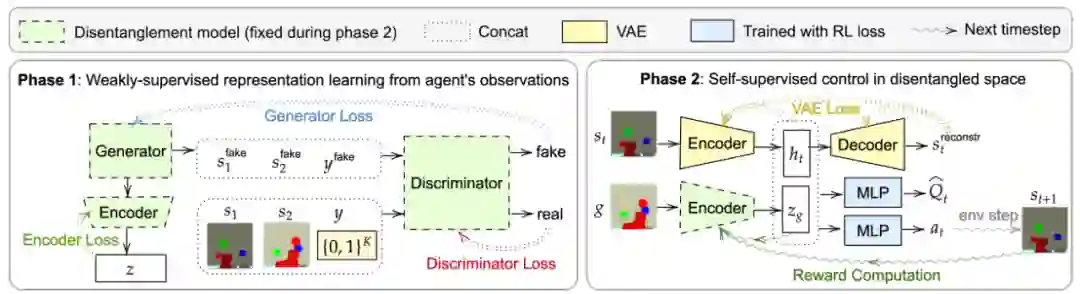
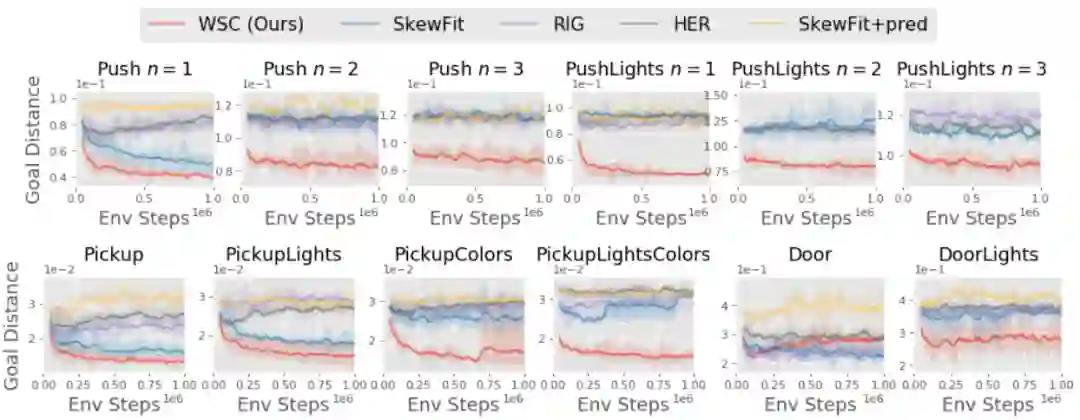
作者:Lisa Lee、Benjamin Eysenbach、 Chelsea Finn 等
论文链接:https://arxiv.org/pdf/2004.02860.pdf
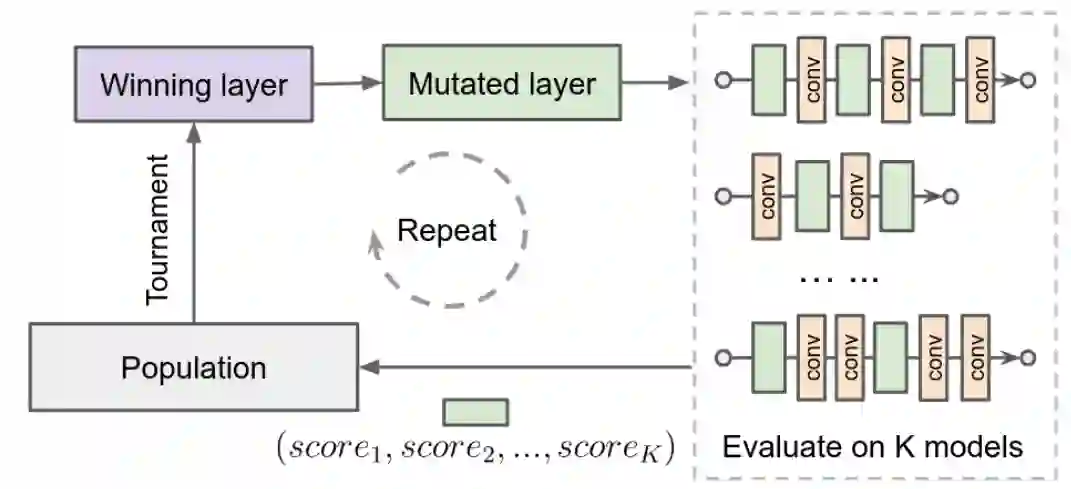
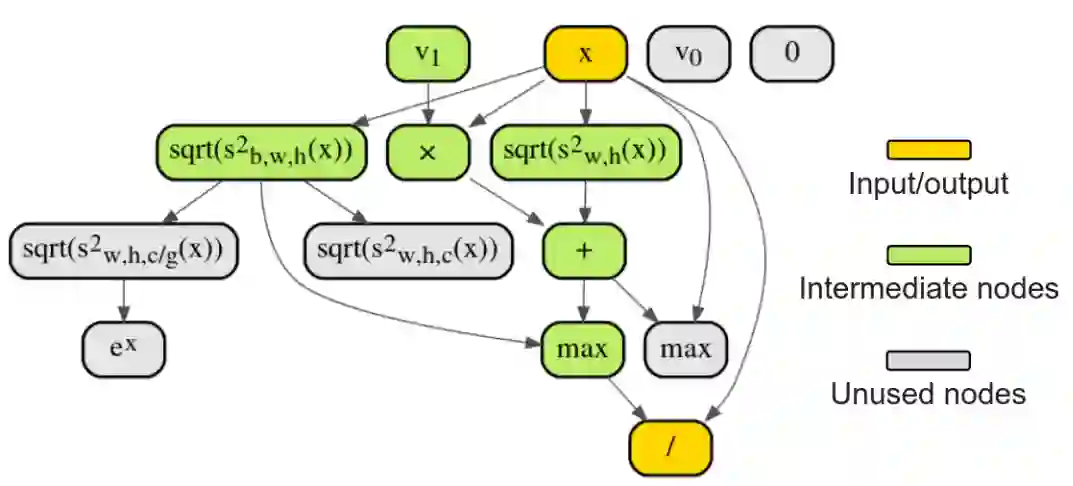
作者:Hanxiao Liu、Andrew Brock、 Quoc V. Le 等
论文链接:https://arxiv.org/pdf/2004.02967.pdf

作者:Ceyuan Yang、Yinghao Xu、 Bolei Zhou 等
论文链接:https://arxiv.org/pdf/2004.03548.pdf
作者:Xingyi Zhou、Vladlen Koltun、Philipp Krahenbuhl
论文链接:https://arxiv.org/pdf/2004.01177.pdf