NIPS 2018 | 行人重识别告别辅助姿势信息,商汤、中科大提出姿势无关的特征提取GAN
选自arXiv
作者:Yixiao Ge、Zhuowan Li、Haiyu Zhao等
机器之心编译
参与:李诗萌、张倩
行人图像的姿势变化是行人重识别(reID)任务中的重要挑战之一。本文提出了一个 reID 新框架——FD-GAN,来学习与身份相关而与姿势无关的表征,用于姿势不同的行人重识别。与现有的对齐或基于区域的学习方法相比,该框架不需要额外的辅助姿势信息和计算成本,在三个广泛使用的行人重识别数据集中都取得了当前最优结果。
引言
行人重识别(reID)是一项极具挑战性的任务,该任务以在多个摄像头拍摄出来的图像中识别相同行人为目标。随着深度学习方法的广泛使用,reID 的性能借助不同的算法得到快速提高。在用深度神经网络学习表征的问题上大家做了各种尝试,但姿势变化、图像模糊以及目标遮挡等问题仍对学习判别式特征提出了巨大的挑战。解决这些问题有两类方法,对齐行人图像 [1] 或通过学习身体区域的特征整合行人的姿势信息 [2]。但这些工作在推断阶段也需要辅助的姿势信息,这样就限制了算法在没有姿势信息的情况下泛化新图像的能力。与此同时,由于对姿势估计的推断更复杂了,计算成本也随之增加。
在图像生成方面,生成式对抗网络(GAN)受到了越来越多的关注。近期,也有一些工作将 GAN 的潜力用在现有的 reID 算法中。Zheng 等人 [3] 提出一个半监督架构,利用离群值的标签平滑正则化(LSRO)学习生成的图像。还有用于弥合不同数据集间领域差距的 PTGAN[4]。除了图像合成,GAN 也可以用在表征学习中。我们在本文中提出了一个身份相关的新表征学习框架,来实现鲁棒的行人重识别。
本文提出的特征提取生成式对抗网络(FD-GAN)在姿势改变的情况下还能保持身份特征的连续性(如图 1 所示),但推断复杂性并没有增加。该架构采用了 Siamese 架构学习特征。每一个分支中都有一个图像编码器和图像生成器。图像编码器输入给定输入图像中的行人视觉特征。图像生成器根据姿势信息和编码器中输入的行人特征生成了新的行人图像。框架中集成了多个判别器,分辨通过两个分支生成的图像之间的分支内和分支间关系。
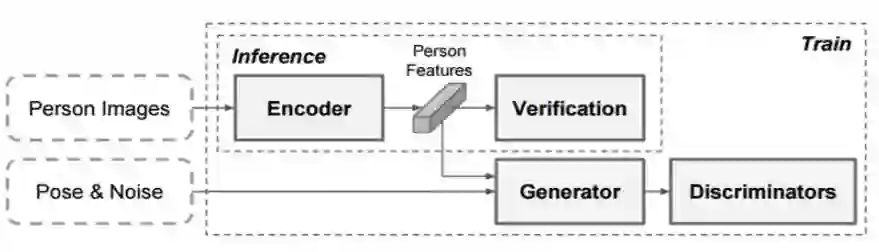
图 1:在姿势引导的图像生成器和判别器的帮助下训练得到的 FD-GAN 中的图像编码器,以学习鲁棒的身份相关和姿势相关表征。它在推断时不需要姿势信息和额外的计算成本。
身份判别器、姿势判别器和验证分类器连同重建损失以及全新的同姿势损失一起正则化特征学习过程,来实现鲁棒的行人重识别。根据对抗损失,可以通过图像编码器在视觉特征中减少姿势和背景这种与身份判断无关的信息。更重要的是,在推断过程中,不再需要额外的姿势信息以及额外的计算成本。在三个广泛使用的 reID 数据集(即 Market-1501[5]、CUHK03[6] 和 DukeMTMC-reID[7])中,我们的方法比之前的方法都要好。
总体而言,本研究做出了以下贡献:1)我们提出了一个新的框架,FD-GAN,来学习与身份相关而与姿势无关的表征,用于姿势不同的行人重识别。与现有的对齐或基于区域的学习方法不同,我们的框架不需要额外的辅助姿势信息,在推断过程中也不需要增加计算的复杂程度。2)尽管在我们的框架中,行人图像生成是辅助任务,但是通过该框架生成的行人图像的质量比现有的行人图像生成方法所生成的图像都要好。3)在行人重识别任务中,本文提出的 FD-GAN 在 Market-1501[5],CUHK03[6] 以及 DukeMTMC-reID[7] 数据集上都取得了当前最佳的表现。
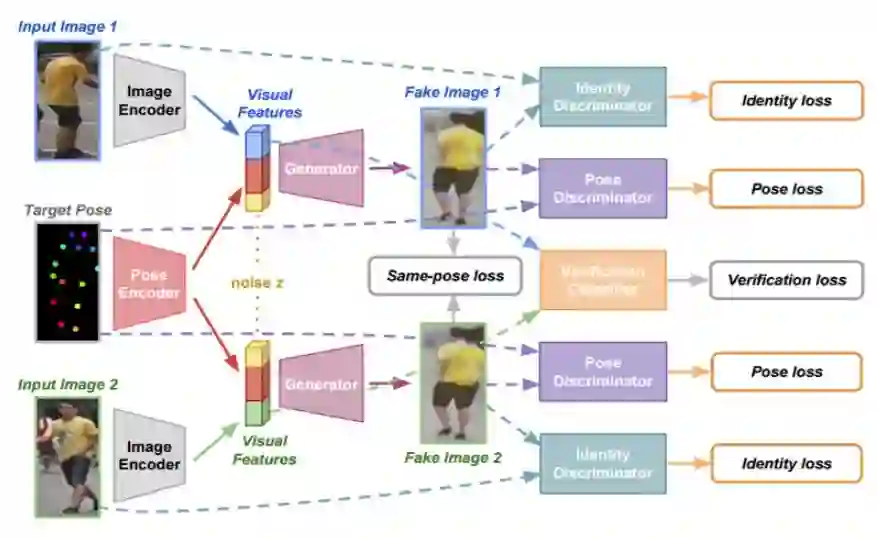
图 2:FD-GAN 的 Siamese 架构。利用验证损失,通过图像编码器 E 学习鲁棒的身份相关而姿势无关的特征,而生成假图像的辅助任务是为了骗过身份和姿势判别器的。引入新的同姿势损失项是为了进一步促进对与身份相关而与姿势无关的视觉特征的学习。
论文:FD-GAN: Pose-guided Feature Distilling GAN for Robust Person Re-identification

论文链接:https://arxiv.org/pdf/1810.02936v1.pdf
摘要:行人重识别(reID)是一项重要的任务,它需要在给定目标行人图像的基础上从图像数据集中提取出行人图像。为了学到鲁棒的行人特征,行人图像的姿势变化是重要的挑战之一。现有的针对该问题的工作要么是对齐行人图片,要么是基于行人区域学习表征。而在推断时一般也会需要额外的姿势信息和计算成本。为了解决这一问题,本文提出了特征提取生成对抗式网络(FD-GAN)来学习和身份相关而和姿势无关的表征。这是一个基于 Siamese 架构的新框架,该框架中有多个新的判别器来判别行人的姿势和身份。除了判别器,还集成了新的同姿势损失,这就需要生成相同行人表现相似的图像。在通过姿势引导学习了与姿势无关的行人特征后,在测试时不再需要辅助的姿势信息和额外的计算成本。我们提出的 FD-GAN 在三个行人重识别数据集中都取得了当前最佳的结果,这说明本文提出的 FD-GAN 可以提取高效而鲁棒的特征。
与 DR-GAN[20] 比较
基于条件 GAN 的 DR-GAN[20] 也试着在面部识别任务中学习姿势变化的身份表征。它也用了一个带有判别器的编码器-解码器架构用来对两种身份进行分类。第 4.2 节中的结果证明,在行人重识别任务中,本文提出的方法比 DR-GAN 要好。
有三点重要差异导致 FD-GAN 比 DR-GAN 效果更好。1)我们用了 Siamese 网络架构,这使我们可以利用同姿势损失鼓励编码器只对身份相关的信息进行编码,而 DR-GAN 则没有这个损失项。2)我们不在图像编码器和身份判别器中的 ResNet-50 网络间共享权值。我们观察到,身份验证和真/假图像身份判别是两个不同领域的任务,因此不能共享它们的权重。3)我们的 Siamese 架构用了验证分类器,而不是交叉熵分类器,在行人重识别任务中,这样可以得到比单分支网络更好的性能。

表 1:FD-GAN 在 Market-1501[5] 和 DukeMTMCreID[7] 数据集上的组分分析。表中标出了最高的准确率(%)和 mAP(%)。
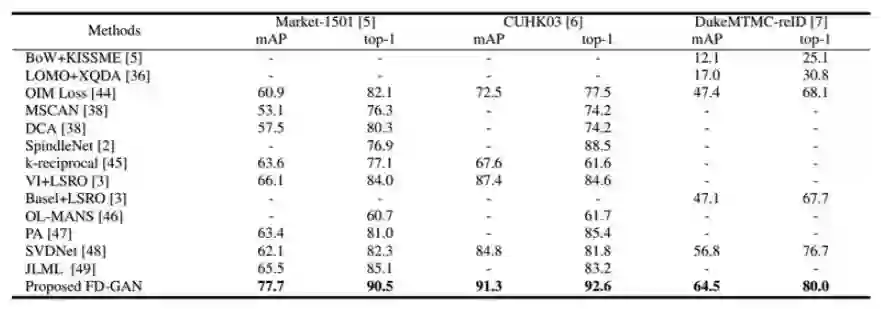
表 2:本文提出的方法和当前最佳方法在 Market-1501[5]、CUHK03[6] 以及 DukeMTMC-reID[7] 数据集上的实验结果比较。表中标注了最高的准确率(%)和 mAP(%)。
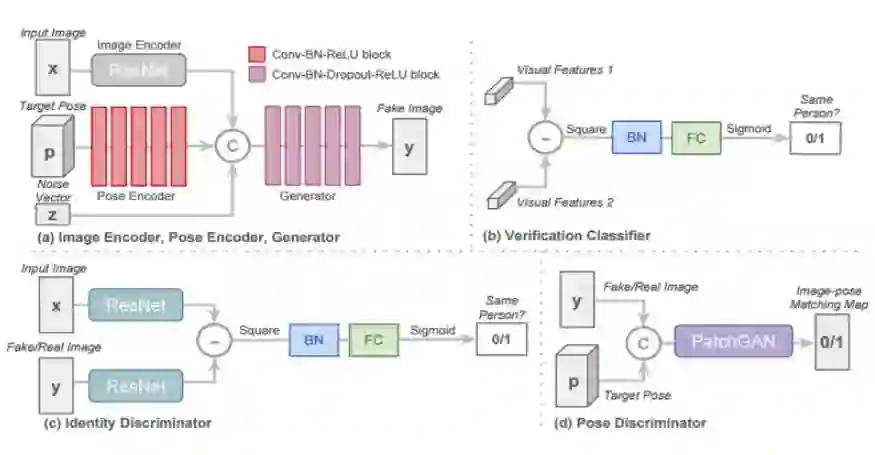
图 3:(a)生成器 G 和图像编码器 E 的网络架构;(b)验证分类器 V 的网络架构;(c)身份判别器 Did 的网络架构;(d)姿势判别器 Dpd 的网络架构。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




