从SGD到NadaMax,十种优化算法原理及实现

极市导读
本文总结了SGD、MomentumNesterov、Momentum、AdaGrad...等十种优化算法,每一种算法的讲解都附有详细的公式过程以及代码实现。>>今天感恩节,感谢CV开发者们对我们的一路支持,前往文末即可领取【极市】给大家的感恩节礼物~
无论是什么优化算法,最后都可以用一个简单的公式抽象:



SGD
Momentum
Nesterov Momentum
AdaGrad
RMSProp
AdaDelta
Adam
AdaMax
Nadam
NadaMax
SGD
虽然有凑数的嫌疑,不过还是把SGD也顺带说一下,就算做一个符号说明了。常规的随机梯度下降公式如下:

其中 



其中 


另外
Numpy实现神经网络框架(3)——线性层反向传播推导及实现
卷积核梯度计算的推导及实现
Momentum
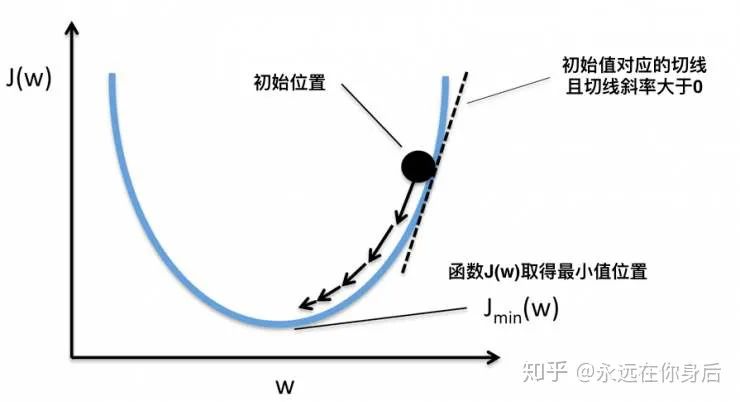 的值,而垂直方向对应为损失。设其质量
的值,而垂直方向对应为损失。设其质量
 ,在第
时刻,在单位时间内,该质点受外力而造成的动量改变为:
,在第
时刻,在单位时间内,该质点受外力而造成的动量改变为:

 ,所以约去了。另外受到的外力可以分为两个分量:重力沿斜面向下的力
,所以约去了。另外受到的外力可以分为两个分量:重力沿斜面向下的力
 和粘性阻尼力
和粘性阻尼力





 ,另外
的方向与损失的梯度方向相反,并取系数为
,得到:
,另外
的方向与损失的梯度方向相反,并取系数为
,得到:


 足够大时,
足够大时,
 趋近于
趋近于

import numpy as np
class Momentum(object):
def __init__(self, alpha=0.9, lr=1e-3):
self.alpha = alpha # 动量系数
self.lr = lr # 学习率
self.v = 0 # 初始速度为0
def update(self, g: np.ndarray): # g = J'(w) 为本轮训练参数的梯度
self.v = self.alpha * self.v - self.lr * g # 公式
return self.v # 返回的是参数的增量,下同

 ,刚开始时
会比期望值要小,需要进行修正,下面的Adam等算法会使用该方式
,刚开始时
会比期望值要小,需要进行修正,下面的Adam等算法会使用该方式
Nesterov Momentum
 更新一遍参数,得到一个临时参数
更新一遍参数,得到一个临时参数
 ,然后使用这个临时参数计算本轮训练的梯度。相当于是小球预判了自己下一时刻的位置,并提前使用该位置的梯度更新 :
,然后使用这个临时参数计算本轮训练的梯度。相当于是小球预判了自己下一时刻的位置,并提前使用该位置的梯度更新 :
 的更新过程:
的更新过程:
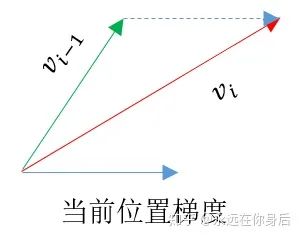
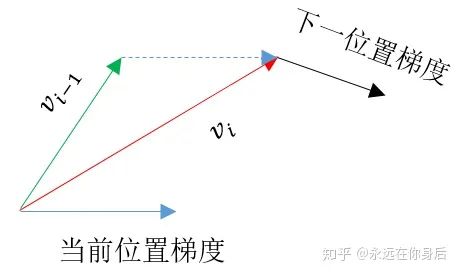
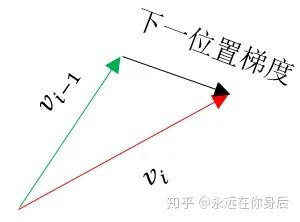 ,所以可以之前使用Momentum的代码
,所以可以之前使用Momentum的代码
AdaGrad

 是一个极小的正数,用来防止除0,而
是一个极小的正数,用来防止除0,而
 ,
,
 是矩阵的哈达玛积运算符,另外,本文中矩阵的平方或者两矩阵相乘都是计算哈达玛积,而不是计算矩阵乘法
是矩阵的哈达玛积运算符,另外,本文中矩阵的平方或者两矩阵相乘都是计算哈达玛积,而不是计算矩阵乘法
 会越来越大,整体的学习率会越来越小。所以,一般来说AdaGrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢
展开得到:
会越来越大,整体的学习率会越来越小。所以,一般来说AdaGrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢
展开得到:

 ,所以在第一次训练时(2.2)式为:
,所以在第一次训练时(2.2)式为:
 的值是不确定的,所以要防止处0,但是可以令
的值是不确定的,所以要防止处0,但是可以令
 ,这样就可以在(2.2)式中去掉
,这样就可以在(2.2)式中去掉
 代入(2.3)式,可以得到:
代入(2.3)式,可以得到:
 恒大于0,因此不必在计算
中额外加入
,代码如下:
恒大于0,因此不必在计算
中额外加入
,代码如下:
class AdaGrad(object):
def __init__(self, eps=1e-8, lr=1e-3):
self.r = eps # r_0 = epsilon
self.lr = lr
def update(self, g: np.ndarray):
r = r + np.square(g)
return -self.lr * g / np.sqrt(r)
RMSProp
的计算不同,先看公式
 展开后的公式:
展开后的公式:
 ,从而去掉计算
时的
,实现代码:
,从而去掉计算
时的
,实现代码:
class RMSProp(object):
def __init__(self, lr=1e-3, beta=0.999, eps=1e-8):
self.r = eps
self.lr = lr
self.beta = beta
def update(self, g: np.ndarray):
r = r * self.beta + (1-self.beta) * np.square(g)
return -self.lr * g / np.sqrt(r)
AdaDelta
 ,这是该算法的一大优势。除了同样以
来累积梯度的信息之外,该算法还多了一个
,这是该算法的一大优势。除了同样以
来累积梯度的信息之外,该算法还多了一个
 以指数衰减的形式来累积
的信息
以指数衰减的形式来累积
的信息
 ,得到:
,得到:

class AdaDelta(object):
def __init__(self, beta=0.999, eps=1e-8):
self.r = eps
self.s = eps
self.beta = beta
def update(self, g: np.ndarray):
g_square = (1-self.beta) * np.square(g) # (1-beta)*g^2
r = r * self.beta + g_square
frac = s / r
res = -np.sqrt(frac) * g
s = s * self.beta + frac * g_squaretmp # 少一次乘法。。。
return res
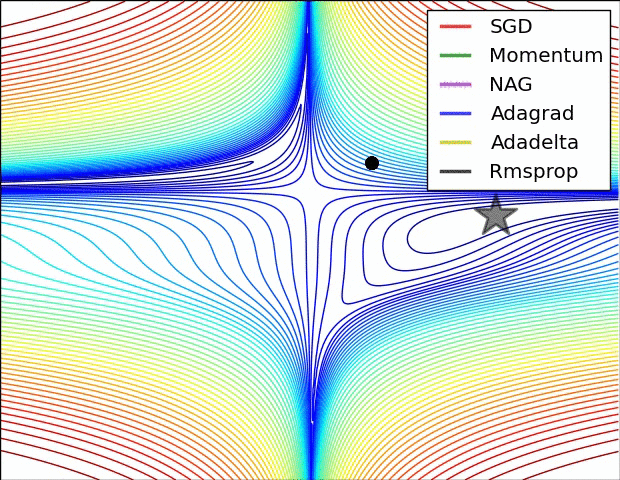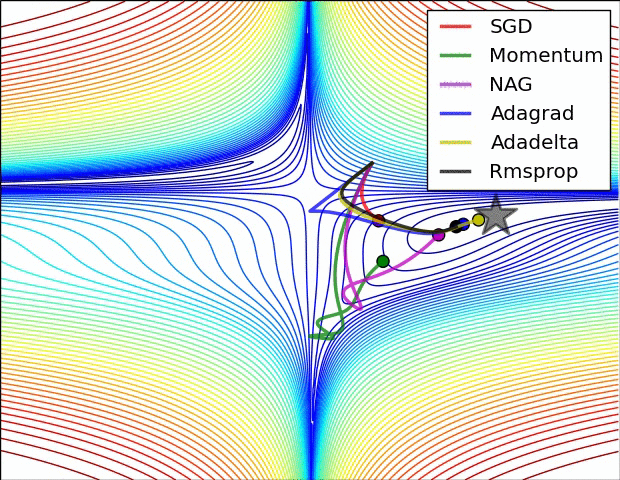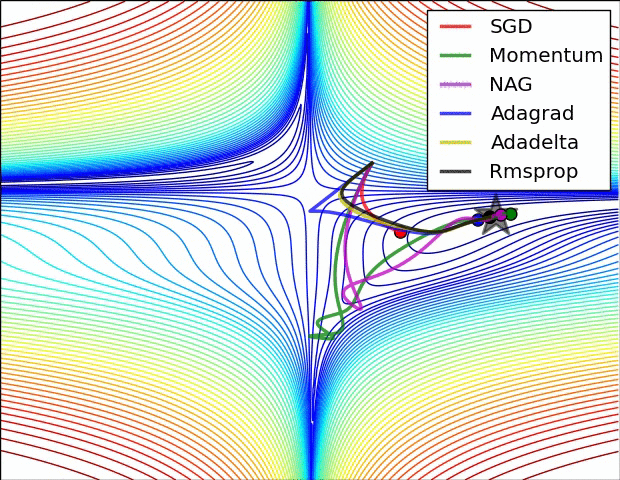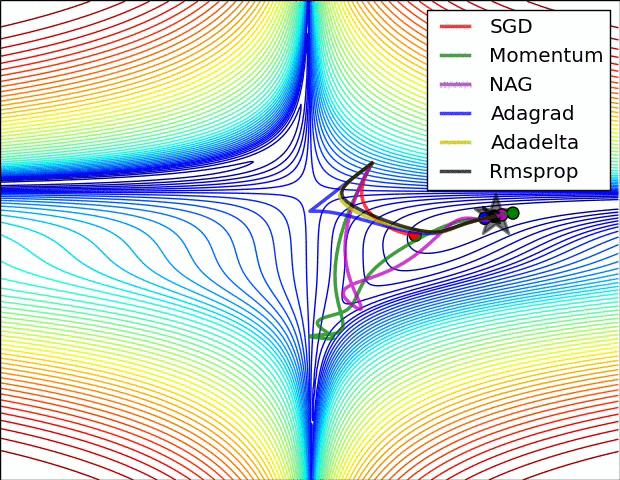
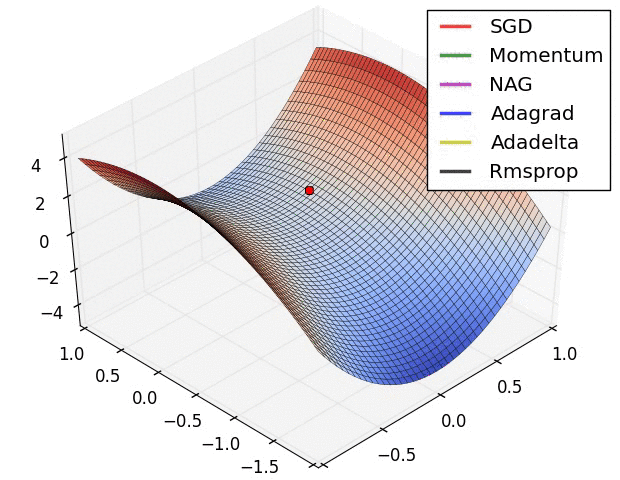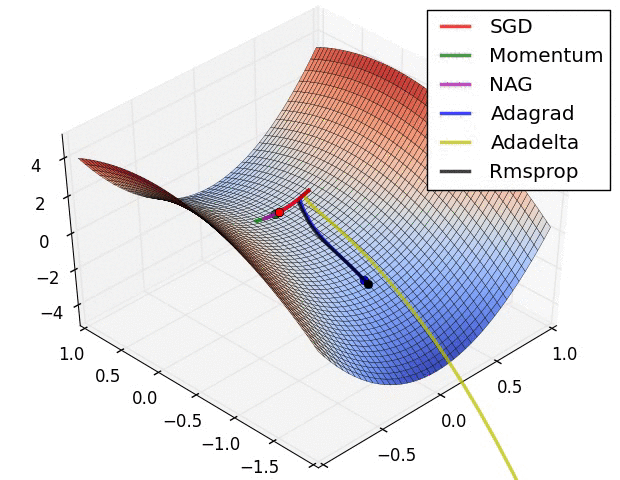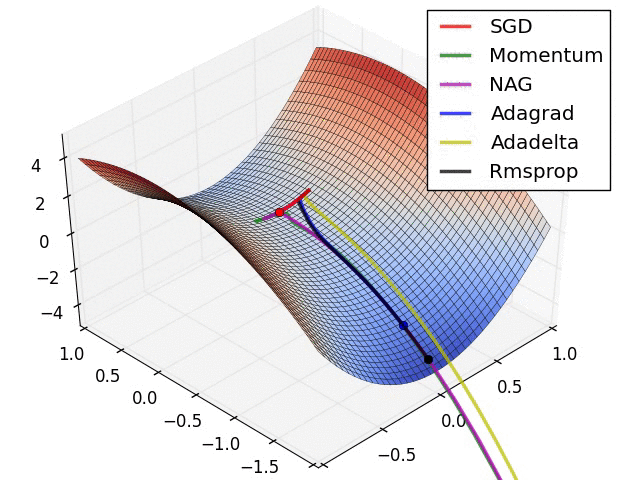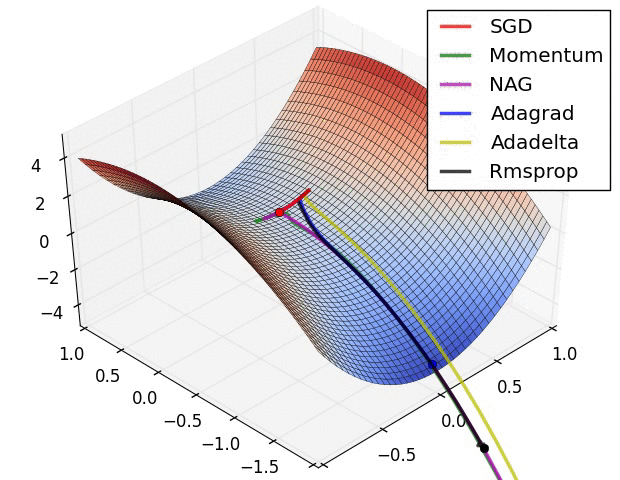
Adam

 计算
却先经过(4.3)和(4.4)式是因为通常会设
计算
却先经过(4.3)和(4.4)式是因为通常会设
 ,所以此时梯度的一阶矩估计和二阶矩估是有偏的,需要进行修正
,所以此时梯度的一阶矩估计和二阶矩估是有偏的,需要进行修正


 ,可知当
足够大时修正将不起作用(也不需要修正了):
,可知当
足够大时修正将不起作用(也不需要修正了):

class Adam(object):
def __init__(self, lr=1e-3, alpha=0.9, beta=0.999, eps=1e-8):
self.s = 0
self.r = eps
self.lr = lr
self.alpha = alpha
self.beta = beta
self.alpha_i = 1
self.beta_i = 1
def update(self, g: np.ndarray):
self.s = self.s * self.alpha + (1-self.alpha) * g
self.r = self.r * self.beta + (1-self.beta) * np.square(g)
self.alpha_i *= self.alpha
self.beta_i *= self.beta_i
lr = -self.lr * (1-self.beta_i)**0.5 / (1-self.alpha_i)
return lr * self.s / np.sqrt(self.r)
AdaMax
的展开式并且令
,得到:

 的
的
 范数,也就是说
的各维度的增量是根据该维度上梯度的
范数的累积量进行缩放的。如果用
范数,也就是说
的各维度的增量是根据该维度上梯度的
范数的累积量进行缩放的。如果用
 范数替代就得到了Adam的不同变种,不过其中
范数替代就得到了Adam的不同变种,不过其中
 范数对应的变种算法简单且稳定
范数,第
轮训练时梯度的累积为:
范数对应的变种算法简单且稳定
范数,第
轮训练时梯度的累积为:


 :
:

 是累积的梯度各个分量的绝对值最大值,所以直接用做分母且不需要修正,代码如下:
是累积的梯度各个分量的绝对值最大值,所以直接用做分母且不需要修正,代码如下:
class AdaMax(object):
def __init__(self, lr=1e-3, alpha=0.9, beta=0.999):
self.s = 0
self.r = 0
self.lr = lr
self.alpha = alpha
self.alpha_i = 1
self.beta = beta
def update(self, g: np.ndarray):
self.s = self.s * self.alpha + (1-self.alpha) * g
self.r = np.maximum(self.r*self.beta, np.abs(g))
self.alpha_i *= self.alpha
lr = -self.lr / (1-self.alpha_i)
return lr * self.s / self.r
Nadam






 替换成
替换成
 ,得到:
,得到:

 ,消去(5.8)式种的
:
,消去(5.8)式种的
:

class Nadam(object):
def __init__(self, lr=1e-3, alpha=0.9, beta=0.999, eps=1e-8):
self.s = 0
self.r = eps
self.lr = lr
self.alpha = alpha
self.beta = beta
self.alpha_i = 1
self.beta_i = 1
def update(self, g: np.ndarray):
self.s = self.s * self.alpha + (1-self.alpha) * g
self.r = self.r * self.beta + (1-self.beta) * np.square(g)
self.alpha_i *= self.alpha
self.beta_i *= self.beta_i
lr = -self.lr * (1-self.beta_i)**0.5 / (1-self.alpha_i)
return lr * (self.s * self.alpha + (1-self.alpha) * g) / np.sqrt(self.r)
NadaMax




class NadaMax(object):
def __init__(self, lr=1e-3, alpha=0.9, beta=0.999):
self.s = 0
self.r = 0
self.lr = lr
self.alpha = alpha
self.alpha_i = 1
self.beta = beta
def update(self, g: np.ndarray):
self.s = self.s * self.alpha + (1-self.alpha) * g
self.r = np.maximum(self.r*self.beta, np.abs(g))
self.alpha_i *= self.alpha
lr = -self.lr / (1-self.alpha_i)
return lr * (self.s * self.alpha + (1-self.alpha) * g) / self.r
参考资料:
[1]: 《机器学习算法背后的理论与优化》 ISBN 978-7-302-51718-4
[2]: Adam: A Method for Stochastic Optimization(https://arxiv.org/abs/1412.6980)
[3]: Incorporating Nesterov Momentum into Adam(https://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ¬eId=OM0jvwB8jIp57ZJjtNEZ)
[4]: An overview of gradient descent optimization algorithms(https://ruder.io/optimizing-gradient-descent/index.html)
推荐阅读
~感恩福利回馈~
关注极市平台,回复关键词“感恩福利”,领取进阶学习礼包!
截止时间:11月27日20:00







