从零开始学习「张氏相机标定法」(五)优化算法正传
坚持原创,点击上方蓝字关注我!
前一篇《从零开始学习「张氏相机标定法」(四)优化算法前传》花了不少篇幅介绍了最简单的求解无约束优化问题的梯度下降法,这篇我们从算法的演进方向分别介绍牛顿法、高斯牛顿法、Levenberg-Marquardt(LM)法。
牛顿法
介绍牛顿法之前,我们先来看看它到底有什么优势?能够解决什么问题?这样才有兴趣去了解它。
前面文章中介绍了梯度下降法在山谷中容易出现锯齿状的迭代,如下图所示。从不同的初始值开始迭代所需要的迭代次数会产生非常大的差异。
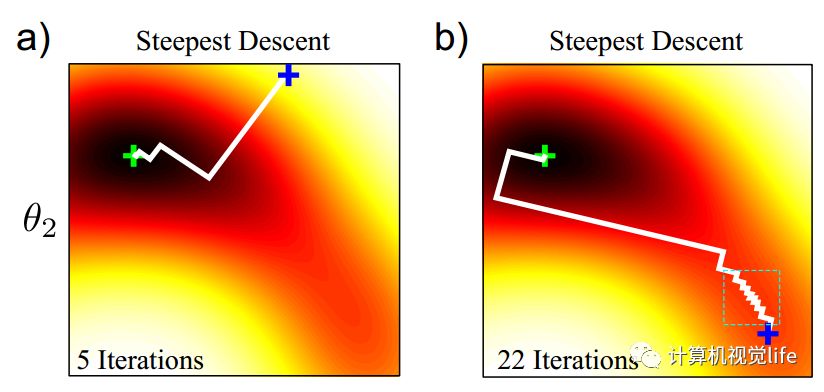
这种锯齿状的迭代,可以通过牛顿法来避免。对于同样的目标函数,使用牛顿法在不同的初始值位置(下图中蓝色十字),只需要3、4次迭代即可找到最小值(下图中绿色十字)。
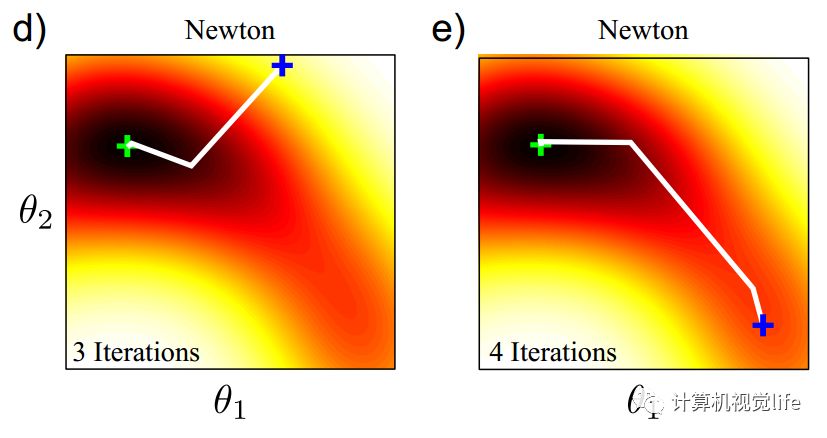
知道了牛顿法相较于梯度下降法的优势了,那么牛顿法是怎么来的?原理是什么?
首先回顾一下,泰勒展开的通式,如下:
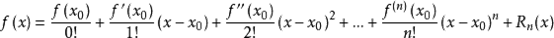
待优化的目标函数和前面一样:
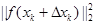
我们将目标函数在x处进行二阶泰勒展开。对照上述通式,目标函数泰勒展开如下:
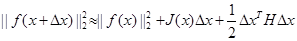
其中 J(x) 是 ||f(x)||2 关于x的Jacobian矩阵(一阶导数),H(x)则是Hessian矩阵(二阶导数)。
什么是Jacobian矩阵和Hessian矩阵呢?
Jacobian矩阵
假设函数 f = {f1(x1,...,xn), .., fm((x1,...,xn))} 有m维空间组成,对应n个自变量。那么函数 f 的一阶偏导数(如果存在)可以组成一个m行n列的矩阵,称为Jacobian(译为雅克比)矩阵
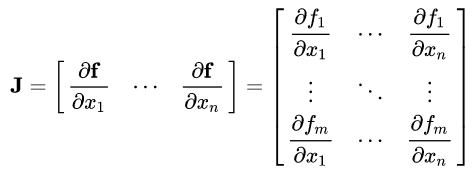
Hessian矩阵
假设有一个实数函数 f(x1,...,xn), 如果函数 f 的所有二阶偏导数存在,那么称如下矩阵为Hessian矩阵,它是一个n x n 的方阵。

而梯度下降法可以认为是泰勒展开式中只取到了一阶项,二阶项后面的部分丢弃。而在牛顿法中,泰勒展开中取到二阶导数,我们的目标函数变为:
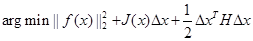
对其关于△x求导,并令其为0,可以得到步长
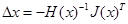
类似于梯度下降法,我们用上述步长来迭代优化,最终收敛到极值点。这个过程就称为牛顿法。
牛顿法相比于梯度下降法的优点是什么呢? 为什么会有这样的优点? 我们来直观的理解一下。
如下图所示。红点和蓝点的梯度(一阶导数)是一样的,但是红点出的二阶导数比蓝点大,也就是说在红点处梯度变化比蓝点处更快,那么最小值可能就在附近,因此步长就应该变小;而蓝点处梯度变化比较缓慢,也就是说这里相对平坦,多走一点也没事,那么可以大踏步往前,因此步长可以变大一些。所以我们看到牛顿法迭代优化时既利用了梯度,又利用了梯度变化的速度(二阶导数)的信息。
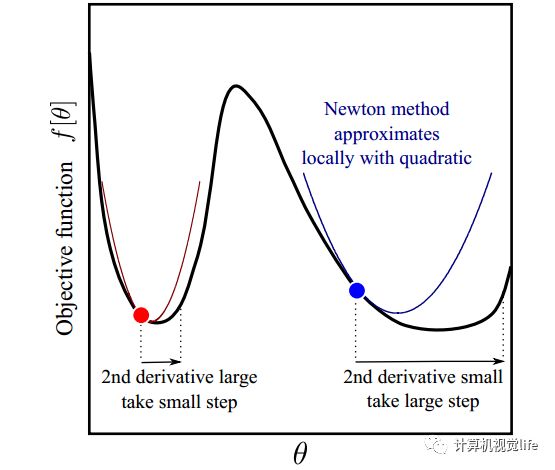
从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法收敛更快。比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。也就是说梯度下降法更贪心,只考虑了眼前,反而容易走出锯齿形状走了弯路;而牛顿法目光更加长远,所以少走弯路。
有人会问了,牛顿法既然那么好,为啥还有后续的高斯牛顿法、LM法?牛顿法肯定有什么缺点吧?
是的,牛顿法确实有比较明显的缺点。前面推导过程,可以看到:牛顿法中包含了Hessian 矩阵的计算。而在高维度下计算Hessian 矩阵需要消耗很大的计算量,很多时候甚至无法计算。
下面介绍高斯牛顿法,看看它是怎么改进牛顿法这个缺点的。
高斯牛顿法
高斯牛顿(Gauss-Newton)法是对牛顿法的一种改进,它用雅克比矩阵的乘积近似代替牛顿法中的二阶Hessian 矩阵,从而省略了求二阶Hessian 矩阵的计算。下面来看看高斯牛顿法是怎么一步步推导来的。
牛顿法中我们是将目标函数 f(x+△x)^2 进行泰勒展开,而在高斯牛顿法中,我们对 f(x+△x) 进行一阶泰勒展开,如下:
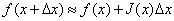
前面我们说过,我们要确定一个步长,使得目标函数
达到最小,将一阶泰勒展开代入,问题转化为如下最小二乘问题:
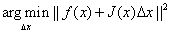
展开后可得:
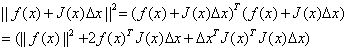
对△x求导并令导数为0,可得:
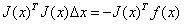
则有:
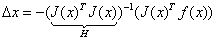
其中我们把J^TJ作为牛顿法中Hessian矩阵的近似,从而用求一阶雅克比矩阵代替了直接求二阶Hessian矩阵的过程。上述就是高斯牛顿法中步长的推导过程。
这个结果完美吗?No!
我们知道牛顿法中,要求Hessian矩阵是可逆的并且正定。但在高斯牛顿法中,用来近似Hessian矩阵的J^TJ可能是奇异矩阵或者病态的,此时会导致稳定性很差,算法不收敛。
另外一个不可忽视的问题是,由于前面我们采用二阶泰勒展开来进行的推导,而泰勒展开只是在一个较小的范围内的近似,因此如果高斯牛顿法计算得到的步长较大的话,上述的近似将不再准确,也会导致算法不收敛。
肿么办?LM算法可以修正上述问题。
LM法
Levenberg-Marquardt(LM)法在一定程度上修正了高斯牛顿法的缺点,因此它比高斯牛顿法更加鲁棒,不过这是以牺牲一定的收敛速度为代价的--它的收敛速度比高斯牛顿法慢。
下面来看看LM算法到底怎么修正高斯牛顿法的缺点的。
LM算法中定义的步长为:
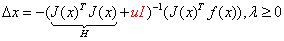
其中I是单位矩阵,u是一个非负数。如果 u 取值较大时,uI 占主要地位,此时的LM算法更接近一阶梯度下降法,说明此时距离最终解还比较远,用一阶近似更合适。反之,如果 u 取值较小时,H 占主要地位,说明此时距离最终解距离较近,用二阶近似模型比较合适,可以避免梯度下降的“震荡”,容易快速收敛到极值点。因此参数 u 不仅影响到迭代的方向还影响到迭代步长的大小。
设x初值为x0,根据经验可以设置u的初值u0为:
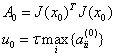
其中,τ可以自己指定,aii表示矩阵A对角线元素。
LM采用的搜索方法是信赖域(Trust Region)方法,和梯度下降、牛顿法、高斯牛顿法采用的线性搜索(Line Search)方法不同。
为什么要用信赖域呢?这是因为高斯牛顿法中采用近似二阶泰勒函数只在展开点附近有较好的近似效果,如果步长太大近似就不准确,因此我们应该给步长加个信赖区域,在信赖区域里,我们认为近似是有效的,出了这个区域,近似会出问题。
那么如何确定信赖区域的范围呢?一个比较好的方法是根据我们的近似模型跟实际函数之间的差异来确定。使用如下因子来判断泰勒近似是否足够好:
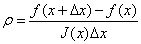
其中,分子是实际函数迭代下降的值,分母是近似模型下降的值。如果 ρ 接近于1,认为近似比较准确,可以扩大信赖范围;如果 ρ 远小于1,说明实际减小的值和近似减少的值差别很大,也就是说近似比较差,需要缩小信赖范围。
下面给出LM算法优化的一个实例流程。
1、给定初始点 x0 ,计算初始信赖域半径 u0
2、对于第 k 次迭代,根据前面式子求出步长 △xk,并计算得到 ρ
3、若 ρ ≤0.25 ,说明步子迈得太大了,应缩小信赖域半径,令
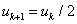
4、若 ρ ≥0.75 ,说明这一步近似比较准确,可以尝试扩大信赖域半径,令
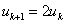
5、若 0.25<ρ<0.75 ,说明这一步迈出去之后,处于“可信赖”和“不可信赖”之间,可以维持当前的信赖域半径,令
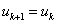
6、若 ρ≤0 ,说明函数值是向着上升而非下降的趋势变化了(与最优化的目标相反),这说明这一步迈得错得“离谱”了,这时不应该走到下一点,而应“原地踏步”,即

并且和上面 ρ≤0.25的情况一样缩小信赖域。反之,在 ρ>0 的情况下,都可以走到下一点,即
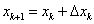
上面优化过程中的阈值参数只是作为示例使用的经验值,也可以自己指定。
LM算法可以一定程度避免系数矩阵的非奇异和病态问题,可以提供更鲁棒、更准确的步长。因此LM算法在相机标定、视觉SLAM等领域中应用非常广泛。
LM算法的C/C++实现见:http://users.ics.forth.gr/~lourakis/levmar/
相关阅读
注:原创不易,转载请联系simiter@126.com,注明来源,侵权必究。