
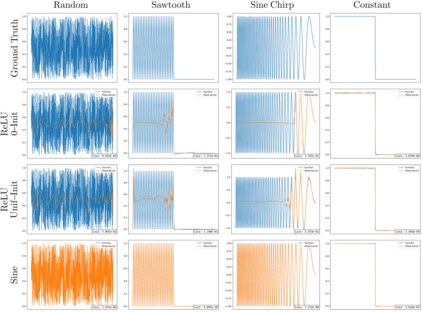
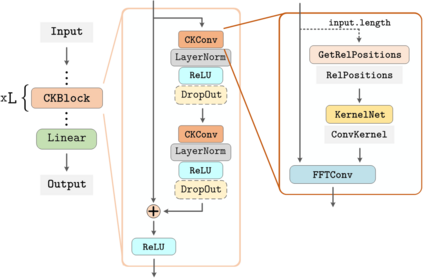
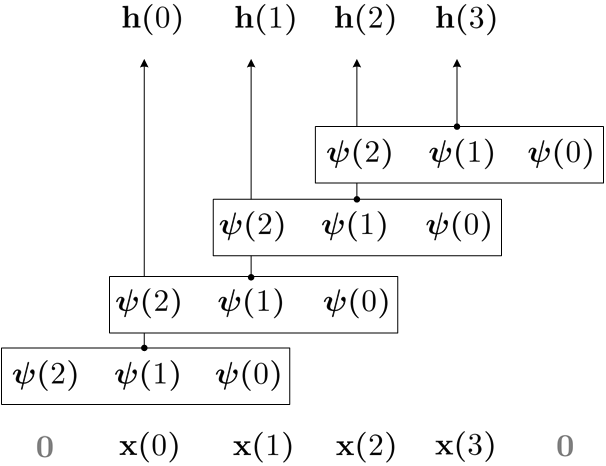
Conventional neural architectures for sequential data present important limitations. Recurrent networks suffer from exploding and vanishing gradients, small effective memory horizons, and must be trained sequentially. Convolutional networks are unable to handle sequences of unknown size and their memory horizon must be defined a priori. In this work, we show that all these problems can be solved by formulating convolutional kernels in CNNs as continuous functions. The resulting Continuous Kernel Convolution (CKConv) allows us to model arbitrarily long sequences in a parallel manner, within a single operation, and without relying on any form of recurrence. We show that Continuous Kernel Convolutional Networks (CKCNNs) obtain state-of-the-art results in multiple datasets, e.g., permuted MNIST, and, thanks to their continuous nature, are able to handle non-uniformly sampled datasets and irregularly-sampled data natively. CKCNNs match or perform better than neural ODEs designed for these purposes in a much faster and simpler manner.
翻译:用于连续数据的常规神经结构具有重要的局限性。 经常性网络存在爆炸和消失的梯度、小的有效记忆地平线,必须进行连续培训。 革命网络无法处理未知大小的序列,必须先验地界定它们的记忆地平线。 在这项工作中,我们表明所有这些问题都可以通过在CNN中将革命内核作为连续功能来解决。 由此形成的连续核心革命(CKConv)使我们能够在单一操作中平行地模拟任意的长序列,不依赖任何形式的重复。 我们显示,连续的Kernel革命网络(CKCNNs)在多个数据集中取得了最先进的结果,例如,移动的MNIST,并且由于它们的连续性,能够处理非统一的抽样数据集和不固定的本地抽样数据。 CKCNNs 匹配或运行比为这些目的设计的神经代码要好得多的更快和简单的方式。


相关内容

Source: Apple - iOS 8

