实践教程|分割mask生成动漫人脸!爆肝数周,从零搭建

极市导读
本文分享了国外大佬的从0开始构建分割mask生成动漫人脸的项目,整个思路的搭建阐述的都非常的详细,有兴趣的朋友们可以按照这个流程去尝试自己搭建~ >>加入极市CV技术交流群,走在计算机视觉的最前沿
今天分享一个国外论坛medium大佬的文章,从 0 做项目的整个过程,具有很大的参考价值,大家感兴趣的可以试着参考这个思路去实现,比起直接跑别人现有的完整,一定能更有收获和成就感。
1、确定目标(分割mask ---> 动漫人脸)
2、确定技术路线(语义分割 + 语义合成)
3、实现(数据集标注 + 模型调优 + 界面编写)
PS:原作者并没有开源数据集和代码, 不过给了所有参考资料的源码和数据集链接!复现应该没有问题

目标
该项目的目标是建立一个深度学习模型,从分割mask生成动漫人脸肖像。

segmentation mask to anime face portrait
在这个项目中,首先手动标注一小批图像。然后使用数据增强和 U-Net 模型来乘以分割mask的数量来构建数据集。最后,训练一个 GauGAN 模型,用于从分割mask中合成动漫人脸。
1. 语义分割
语义分割是为图像中的每个像素分配标签(也称为类 id)的过程。它的结果是一个分割mask,它是一个大小为高度 * 宽度的数组,每个像素都包含一个类 ID。
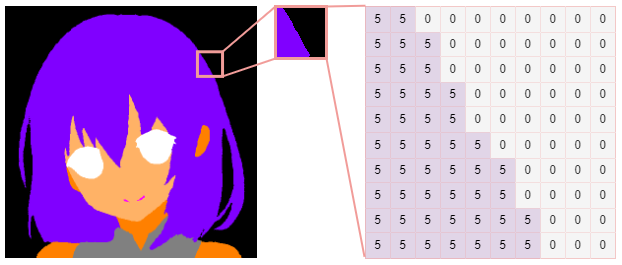
class id: 0 = background, 5 = hair
1.1 Dataset
在进入图像生成任务之前,我们需要一个分割mask数据集,用于训练生成模型将mask转换为图像。
数据集链接:https://www.gwern.net/Crops#danbooru2019-portraits
1.2 Annotation
要标注图像,我们必须确定类。最初的想法是列出 15 个类:
background, body, ear, face, eyeball, pupil, eyelash, nose, mouth, hair, hair_accessory, eyebrow, glasses, clothes, hand后来为了简单起见,将其缩减为 7 个类,最终的类列表如下:
background, skin, face, eye, mouth, hair, clothes有许多不同的注释工具,这里使用的是 labelme。
https://github.com/wkentaro/labelme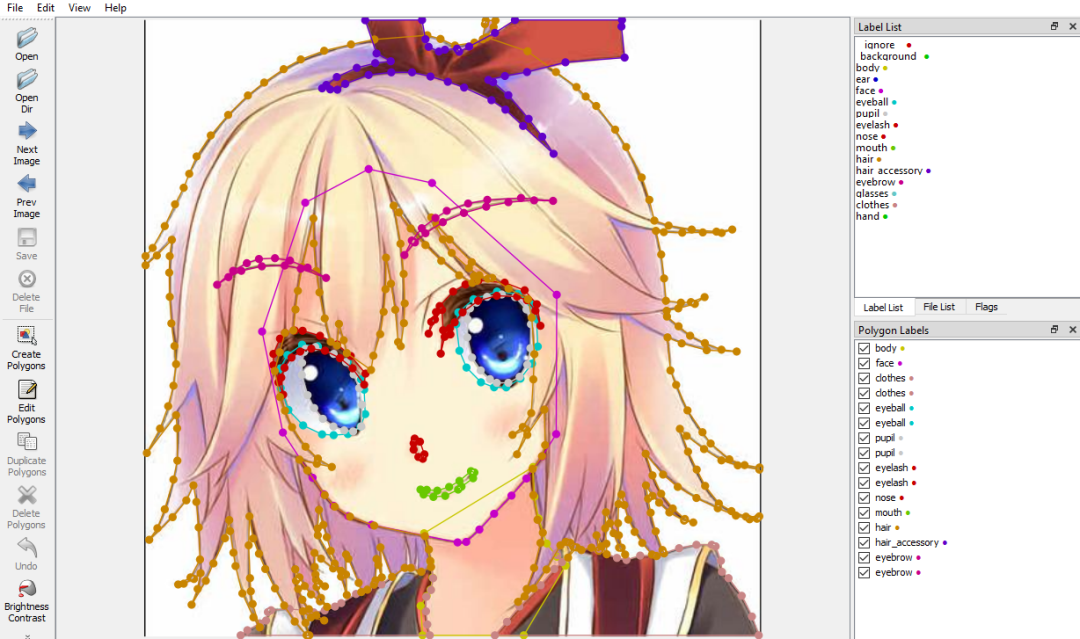
labelme GUI

在这项乏味的工作上辛勤工作数周后,设法标注了 200 张图像

examples of annotated masks

left: original image, middle: segmentation mask, right: visualization of the annotation
1.3 Data Augmentation
当然,200 张带注释的图像不足以让我们训练我们的网络。我们需要使用数据增强技术来增加数据集的大小。
通过随机旋转、镜像和扭曲图像,我从这 200 个样本中生成了 3000 多个数据。换句话说,现在我有 3200 个数据。
examples of augmented masks
然而,这些数据在内容和风格方面高度重复,因为它们仅从 200 个样本中扩充而来。为了训练网络将分割掩码转换为高质量和多样化的动漫面孔,我们需要的不仅仅是 200 + 3000 个数据点。因此,我将首先使用这些数据来训练一个 U-Net 模型来学习从动漫人脸到分割掩码的翻译。然后我会将整个 Danbooru 肖像数据集输入到经过训练的 U-Net 模型中,以生成更多不同人脸的分割掩码。

anime face portraits to segmentation mask
1.4 U-Net
U-Net 最初是为了分割医学图像进行诊断而引入的。它通过使用跳跃连接来解决传统 FCN(全卷积网络)中发生的信息丢失问题,在精确分割方面做得非常好。
U-Net 的架构与 Autoencoder 相似,但从下采样端到上采样端有额外的连接层。
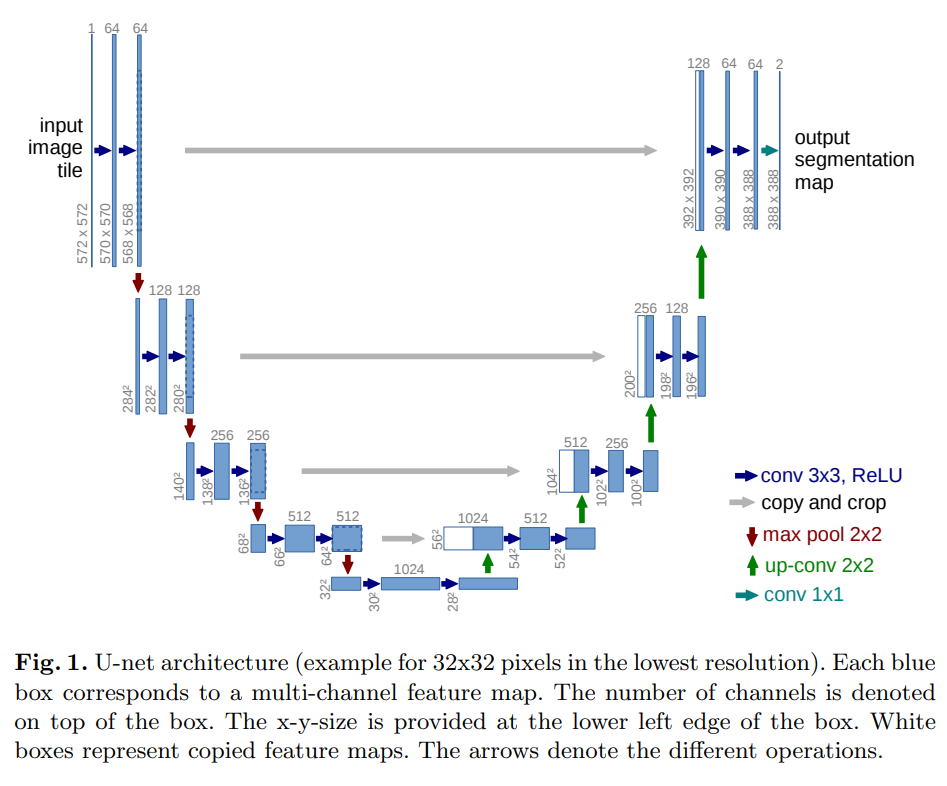
source: https://arxiv.org/abs/1505.04597
在下采样部分,我使用预训练的 MobileNetV2 从输入图像中提取特征。在上采样部分,我使用了由 Conv2DTranspose、Batchnorm 和 ReLU 层组成的块。
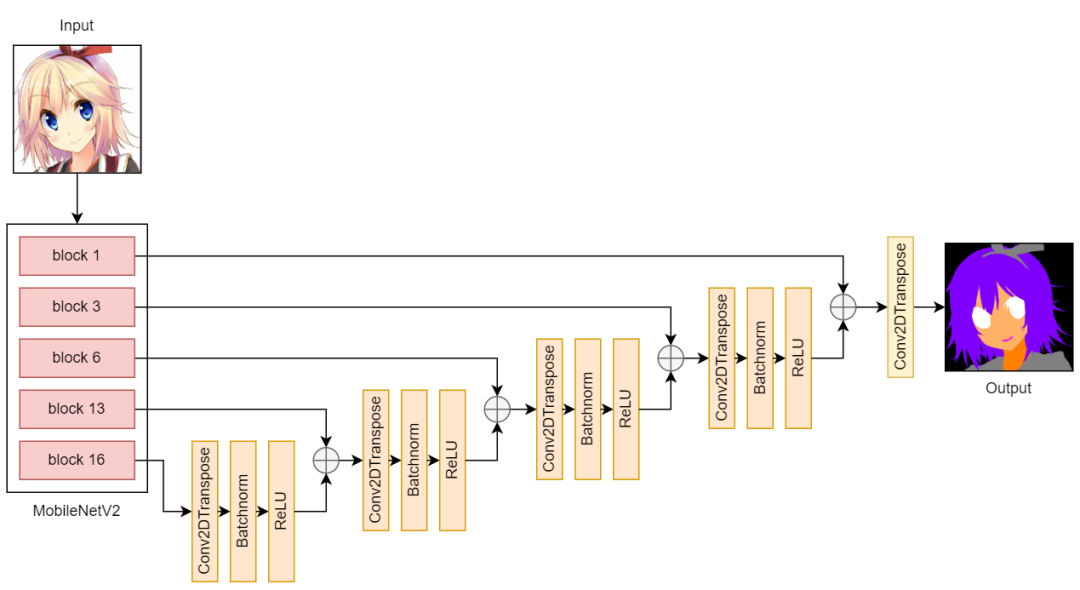
U-Net v1, v2 architecture
在我的 U-Net 版本 1 中,输入和输出大小为 128 x 128px。经过训练的模型确实学习了从动漫人脸到分割mask的非常好的映射。但由于我想在我后来的合成模型中拥有 512 x 512px 的输入和输出,我将 U-Net 输出的大小调整为 512 x 512px 并进行插值。然而,结果看起来是像素化的,它未能捕捉到出现在小区域(例如嘴巴)中的某些类别。
在版本 2 中,我只是将输入和输出大小更改为 512 x 512px(我一开始并没有这样做,因为我不希望输出嘈杂并在图像中令人困惑的区域中填充随机点,例如 衣服)。正如我所料,v2 的输出很嘈杂。不过,它们看起来比 v1 更好。
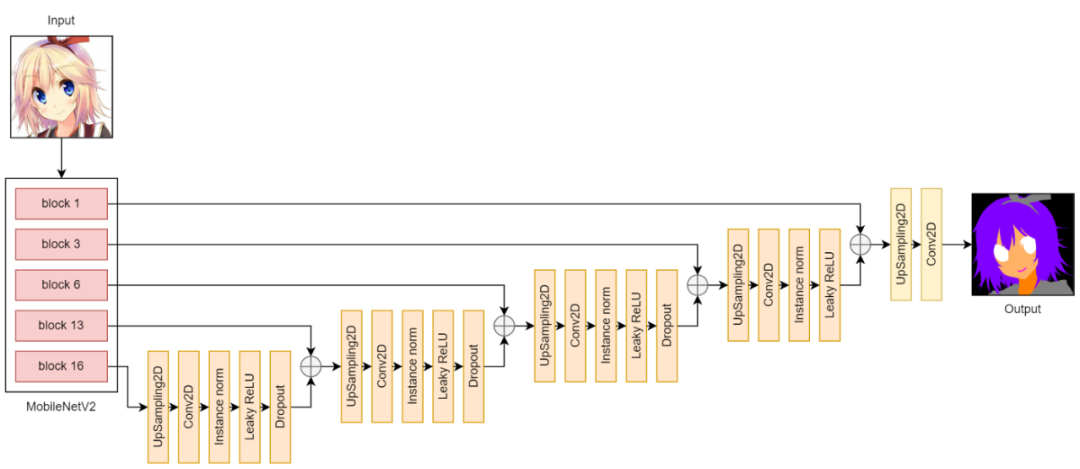
U-Net v3 architecture
在版本 3 中,我尝试通过用 UpSampling2D 层替换 Conv2DTranspose 层来减轻噪音和棋盘伪影。现在的结果比 v2 的要好得多。噪音更少,棋盘伪影更少。

checkerboard artifacts of v2

U-Net segmentation results
最后,我将整个 Danbooru 数据集输入 U-Net v3 以构建我的分割掩码数据集。
2. 图像语义合成
现在,我们有了分割蒙版数据集,是时候深入研究主要任务——图像语义合成,正如之前所说,这不过是从分割mask到真实图像的转换的一个花哨的名称。
Semantic Image Synthesis: segmentation mask to anime face portrait
2.1 GauGAN

source: https://github.com/NVlabs/SPADE
GauGAN 由 Nvidia 开发,用于从分割mask合成逼真的图像。在他们的展示网站上,他们展示了 GauGAN 如何出色地通过几笔画来生成逼真的风景图像。
demo链接:https://www.nvidia.com/en-us/research/ai-playground/
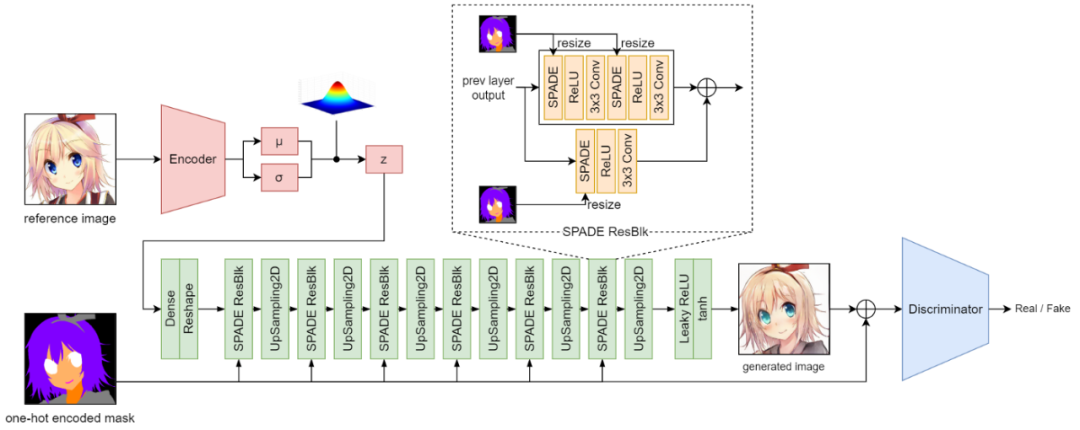
GauGAN architecture
上图展示了 GauGAN 模型的架构。绿色块完全代表发电机。鉴别器是一个 PatchGAN。
2.2 SPADE
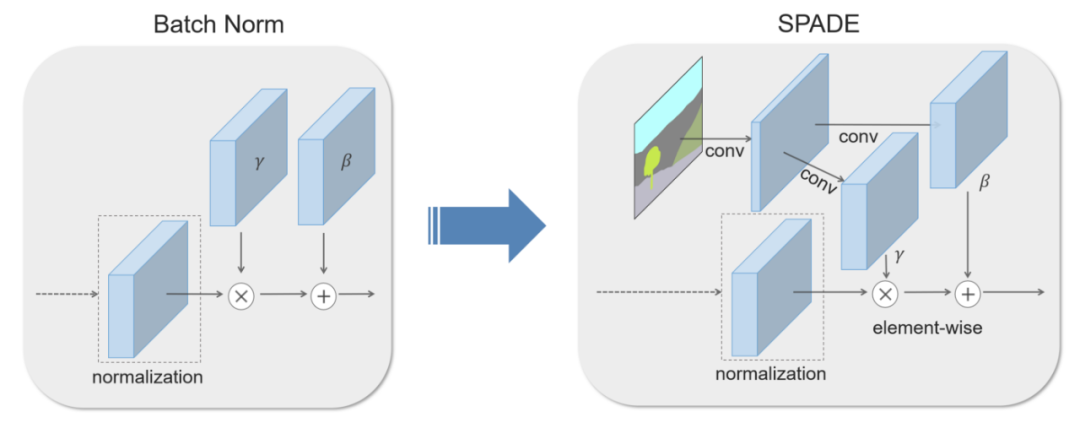
source: https://nvlabs.github.io/SPADE/
GauGAN 的核心是 SPADE(Spatially-Adaptive Denormalization)模块,它是从 Batch Norm 修改而来的归一化层。它旨在克服 pix2pixHD 中的挑战:在具有统一类 ID 的大区域丢失语义信息。
这是通过将 Conv 层引入Batch Norm来解决的,这样它具有不同的参数集(β,γ),这些参数以分割mask为条件,并且会随着不同的区域而变化。这意味着 SPADE 允许生成器在统一标签区域中学习更多细节。

因此,在我们的问题中,生成的图像可能如下所示:

2.3 Pretrained Encoder
encoder 实际上是可选的,因为可以直接从高斯分布中采样 z(潜在向量)而无需任何输入(就像 vanilla GAN)。这里使用了encoder ,因为我想用参考图像对生成的图像进行样式设置。
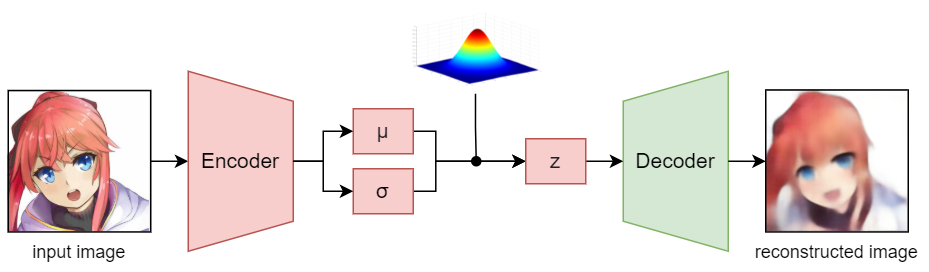
VAE architecture
由于与encoder一起训练 GauGAN 是不稳定的,需要更多的时间和资源,所以我提前使用 VAE 训练了我的编码器,然后在 GauGAN 模型的训练过程中使用预训练的encoder对 z 进行采样。
2.4 Results
以下是从不同的分割mask和参考图像生成的图像的结果。

semantic image synthesis results
2.5 Latent Attribute Vectors
除了使用参考图像来控制输出图像的风格外,我们还可以直接操纵潜在向量 z 来做到这一点。为此,我们首先需要找出潜在空间中的属性向量。
动漫角色面部最重要的属性之一是头发颜色。但是,由于数据集没有带有头发颜色的标签,我必须自己使用 i2v 来标记它们,i2v 是一个用于估计插图标签的库。然后,我们可以通过使用 t-SNE 将样本图像的潜在向量投影到 2D 空间来可视化潜在空间以及估计的标签。
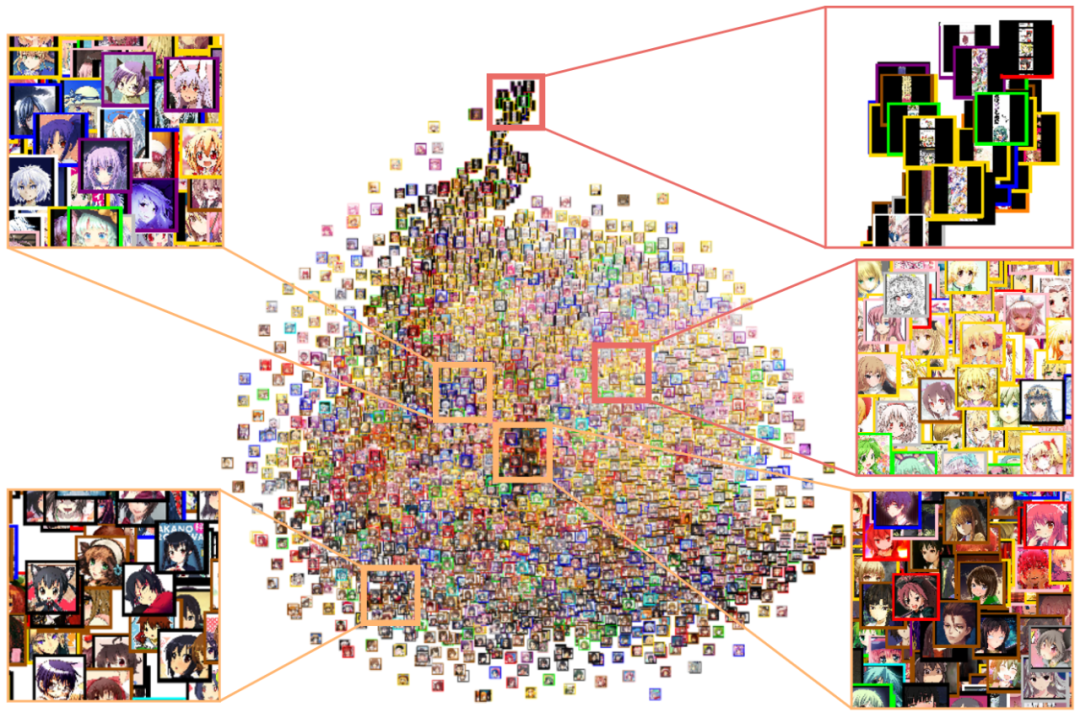
t-SNE of 4000 samples (estimated hair colors are indicated by image border colors)
最后,通过计算不同标签的潜在向量之间的距离和方向,我们可以得到属性向量。下面的动画演示了使用提取的属性向量在头发颜色之间进行的转换。
3. GUI
使用 python tkinter 库创建了一个 GUI,用于编辑生成的图像和分割mask。以下是演示视频:
4. 总结
这个项目还有改进的空间,尤其是语义分割模型(U-Net)和语义图像合成模型(GauGAN)。以下是未来要做的事情的清单:
寻找更好的模型架构以从原始图像中获得更准确的分割掩码
改进 GauGAN 模型以消除头发区域出现的噪声
训练生成模型以生成随机分割mask
参考资料
[1] D. Gwern Branwen, “Anime Crop Datasets: Faces, Figures, & Hands”, Gwern.net, 2022. https://www.gwern.net/Crops#danbooru2019-portraits
[2] “ wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).”, GitHub, 2022. https://github.com/wkentaro/labelme
[3] O. Ronneberger, P. Fischer and T. Brox, “U-Net: Convolutional Networks for Biomedical Image Segmentation”, arXiv.org, 2022. https://arxiv.org/abs/1505.04597
[4] Odena, et al., “Deconvolution and Checkerboard Artifacts”, Distill, 2016. http://doi.org/10.23915/distill.00003
[5] “The NVIDIA AI Playground”, NVIDIA, 2022. https://www.nvidia.com/en-us/research/ai-playground/
[6] “NVlabs/SPADE: Semantic Image Synthesis with SPADE”, GitHub, 2022. https://github.com/NVlabs/SPADE
[7] “Semantic Image Synthesis with Spatially-Adaptive Normalization”, Nvlabs.github.io, 2022. https://nvlabs.github.io/SPADE/
[8] “rezoo/illustration2vec: A simple deep learning library for estimating a set of tags and extracting semantic feature vectors from given illustrations.”, GitHub, 2022. https://github.com/rezoo/illustration2vec
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~






