实践教程|CV语义分割标签之间的相互转换

极市导读
本文以语义分割任务为例,介绍了标签的不同表达形式。并介绍了不同表达形式之间应该如何相互转换,附相关代码。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
图像分割是计算机视觉中除了分类和检测外的另一项基本任务,它意味着要将图片根据内容分割成不同的块。相比图像分类和检测,分割是一项更精细的工作,因为需要对每个像素点分类。如下图的街景分割,由于对每个像素点都分类,物体的轮廓是精准勾勒的,而不是像检测那样给出边界框。

图像分割可以分为以下三个子领域:语义分割、实例分割、全景分割。

由对比图可发现,语义分割是从像素层次来识别图像,为图像中的每个像素制定类别标记,目前广泛应用于医学图像和无人驾驶等;实例分割相对更具有挑战性,不仅需要正确检测图像中的目标,同时还要精确的分割每个实例;全景分割综合了两个任务,要求图像中的每个像素点都必须被分配给一个语义标签和一个实例id。
01 语义分割中的关键步骤
在进行网络训练时,时常需要对语义标签图或是实例分割图进行预处理。如对于一张彩色的标签图,通过颜色映射表得到每种颜色所代表的类别,再将其转换成相应的掩膜或Onehot编码完成训练。这里将会对于其中的关键步骤进行讲解。首先,以语义分割任务为例,介绍标签的不同表达形式。
1.1 语义标签图
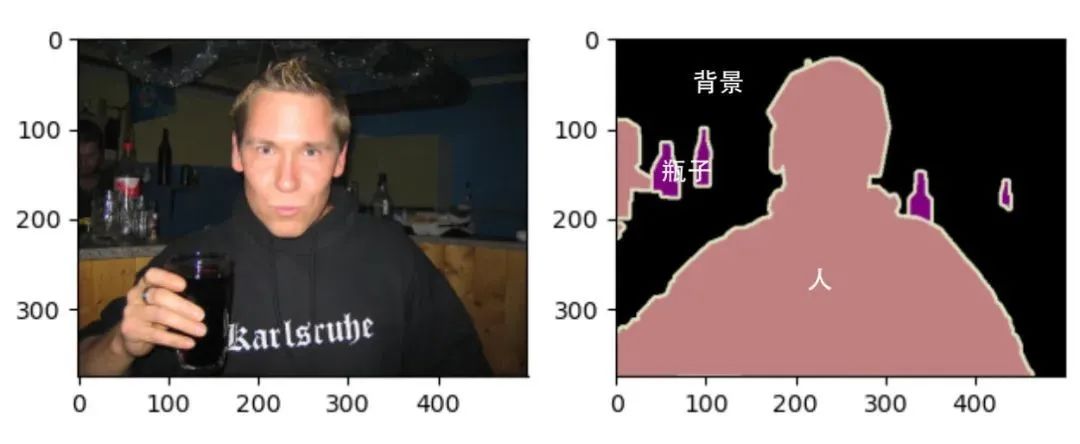
语义分割数据集中包括原图和语义标签图,两者的尺寸大小相同,均为RGB图像。在标签图像中,白色和黑色分别代表边框和背景,而其他不同颜色代表不同的类别:
1.2 单通道掩膜
每个标签的RGB值与各自的标注类别对应,则可以很容易地查找标签中每个像素的类别索引,生成单通道掩膜Mask。如下面这种图,标注类别包括:Person、Purse、Plants、Sidewalk、Building。将语义标签图转换为单通道掩膜后为右图所示,尺寸大小不变,但通道数由3变为1。
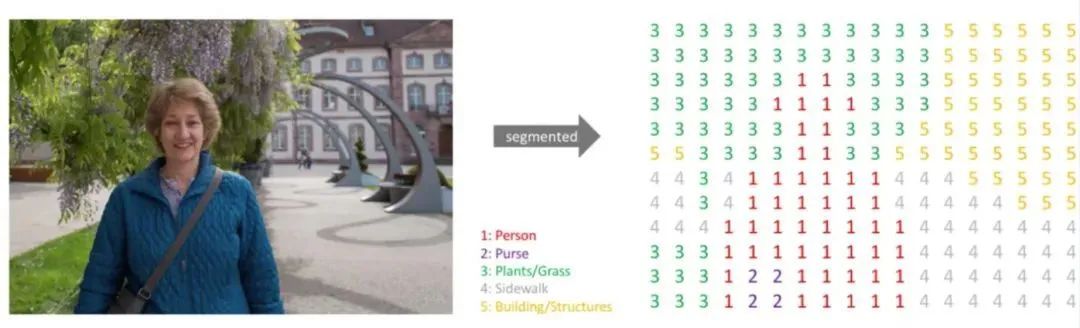
每个像素点位置一一对应。

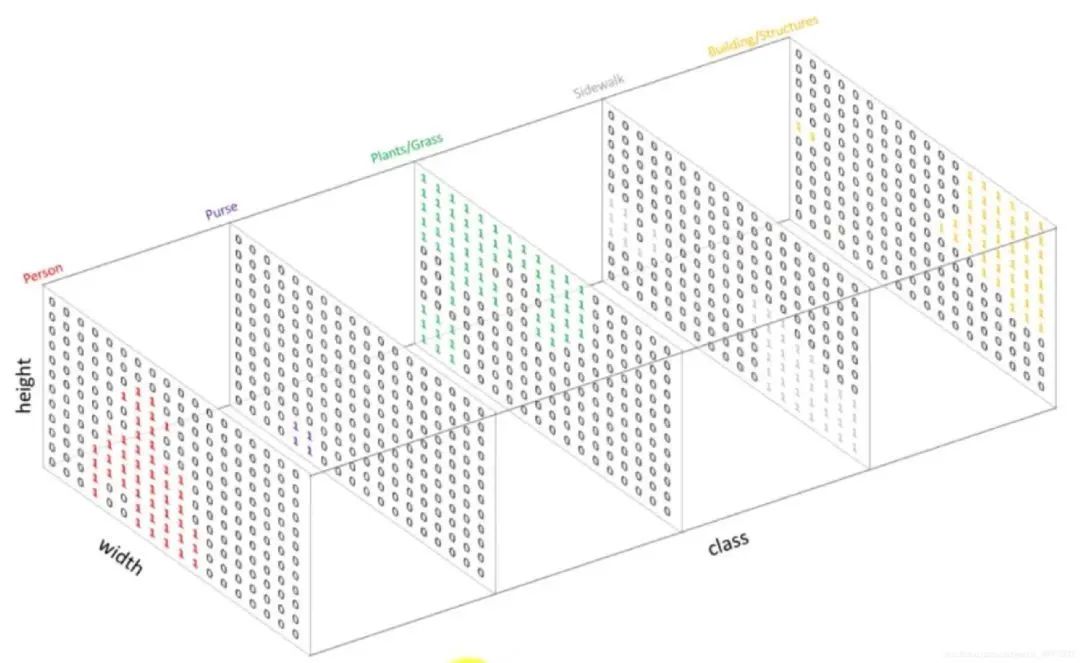
1.3 Onehot编码
Onehot作为一种编码方式,可以对每一个单通道掩膜进行编码。比如对于上述掩膜图Mask,图像尺寸为,标签类别共有5类,我们需要将这个Mask变为一个5个通道的Onehot输出,尺寸为,也就是将掩膜中值全为1的像素点抽取出生成一个图,相应位置置为1,其余为0。再将全为2的抽取出再生成一个图,相应位置置为1,其余为0,以此类推。
02 语义分割实践
接下来以Pascal VOC 2012语义分割数据集为例,介绍不同表达形式之间应该如何相互转换。实践采用的是Pascal VOC 2012语义分割数据集,它是语义分割任务中十分重要的数据集,有 20 类目标,这些目标包括人类、机动车类以及其他类,可用于目标类别或背景的分割。数据集开源地址:https://gas.graviti.cn/dataset/yluy/VOC2012Segmentation
2.1 数据集读取
在使用之前先进行一些必要的准备工作:
-
Fork数据集:如果需要使用公开数据集,则需要将其先fork到自己的账户。 -
获取AccessKey:获取使用SDK与格物钛数据平台交互所需的密钥,链接为https://gas.graviti.cn/tensorbay/developer -
理解Segment:数据集的进一步划分,如VOC数据集分成了“train”和“test”两个部分。
import os
from tensorbay import GAS
from tensorbay.dataset import Data, Dataset
from tensorbay.label import InstanceMask, SemanticMask
from PIL import Image
import numpy as np
import torchvision
import matplotlib.pyplot as plt
ACCESS_KEY = "<YOUR_ACCESSKEY>"
gas = GAS(ACCESS_KEY)
def read_voc_images(is_train=True, index=0):
"""
read voc image using tensorbay
"""
dataset = Dataset("VOC2012Segmentation", gas)
if is_train:
segment = dataset["train"]
else:
segment = dataset["test"]
data = segment[index]
feature = Image.open(data.open()).convert("RGB")
label = Image.open(data.label.semantic_mask.open()).convert("RGB")
visualize(feature, label)
return feature, label # PIL Image
def visualize(feature, label):
"""
visualize feature and label
"""
fig = plt.figure()
ax = fig.add_subplot(121) # 第一个子图
ax.imshow(feature)
ax2 = fig.add_subplot(122) # 第二个子图
ax2.imshow(label)
plt.show()
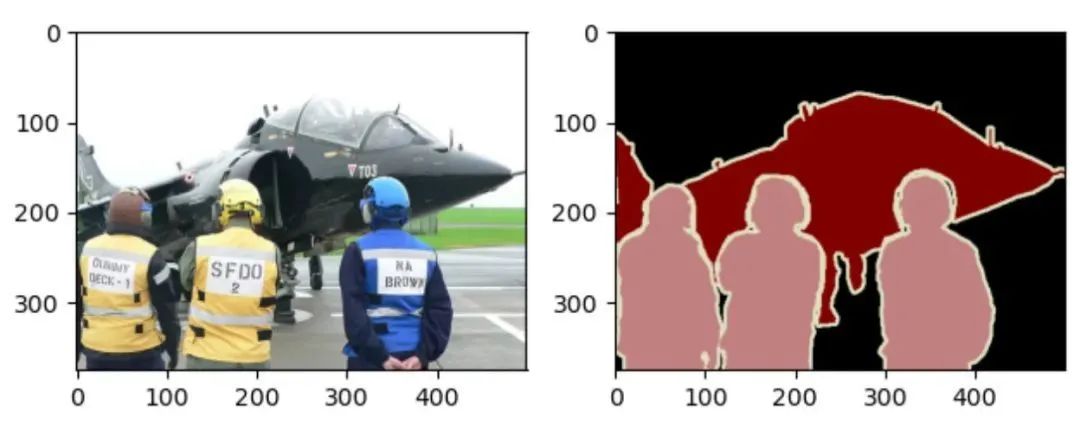
train_feature, train_label = read_voc_images(is_train=True, index=10)
train_label = np.array(train_label) # (375, 500, 3)
2.2 颜色映射表
在得到彩色语义标签图后,则可以构建一个颜色表映射,列出标签中每个RGB颜色的值及其标注的类别。
def colormap_voc():
"""
create a colormap
"""
colormap = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]]
classes = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person',
'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']
return colormap, classes
2.3 Label与Onehot转换
根据映射表,实现语义标签图与Onehot编码的相互转换:
def label_to_onehot(label, colormap):
"""
Converts a segmentation label (H, W, C) to (H, W, K) where the last dim is a one
hot encoding vector, C is usually 1 or 3, and K is the number of class.
"""
semantic_map = []
for colour in colormap:
equality = np.equal(label, colour)
class_map = np.all(equality, axis=-1)
semantic_map.append(class_map)
semantic_map = np.stack(semantic_map, axis=-1).astype(np.float32)
return semantic_map
def onehot_to_label(semantic_map, colormap):
"""
Converts a mask (H, W, K) to (H, W, C)
"""
x = np.argmax(semantic_map, axis=-1)
colour_codes = np.array(colormap)
label = np.uint8(colour_codes[x.astype(np.uint8)])
return label
colormap, classes = colormap_voc()
semantic_map = mask_to_onehot(train_label, colormap)
print(semantic_map.shape) # [H, W, K] = [375, 500, 21] 包括背景共21个类别
label = onehot_to_label(semantic_map, colormap)
print(label.shape) # [H, W, K] = [375, 500, 3]
2.4 Onehot与Mask转换
同样,借助映射表,实现单通道掩膜Mask与Onehot编码的相互转换:
def onehot2mask(semantic_map):
"""
Converts a mask (K, H, W) to (H,W)
"""
_mask = np.argmax(semantic_map, axis=0).astype(np.uint8)
return _mask
def mask2onehot(mask, num_classes):
"""
Converts a segmentation mask (H,W) to (K,H,W) where the last dim is a one
hot encoding vector
"""
semantic_map = [mask == i for i in range(num_classes)]
return np.array(semantic_map).astype(np.uint8)
mask = onehot2mask(semantic_map.transpose(2,0,1))
print(np.unique(mask)) # [ 0 1 15] 索引相对应的是背景、飞机、人
print(mask.shape) # (375, 500)
semantic_map = mask2onehot(mask, len(colormap))
print(semantic_map.shape) # (21, 375, 500)
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





