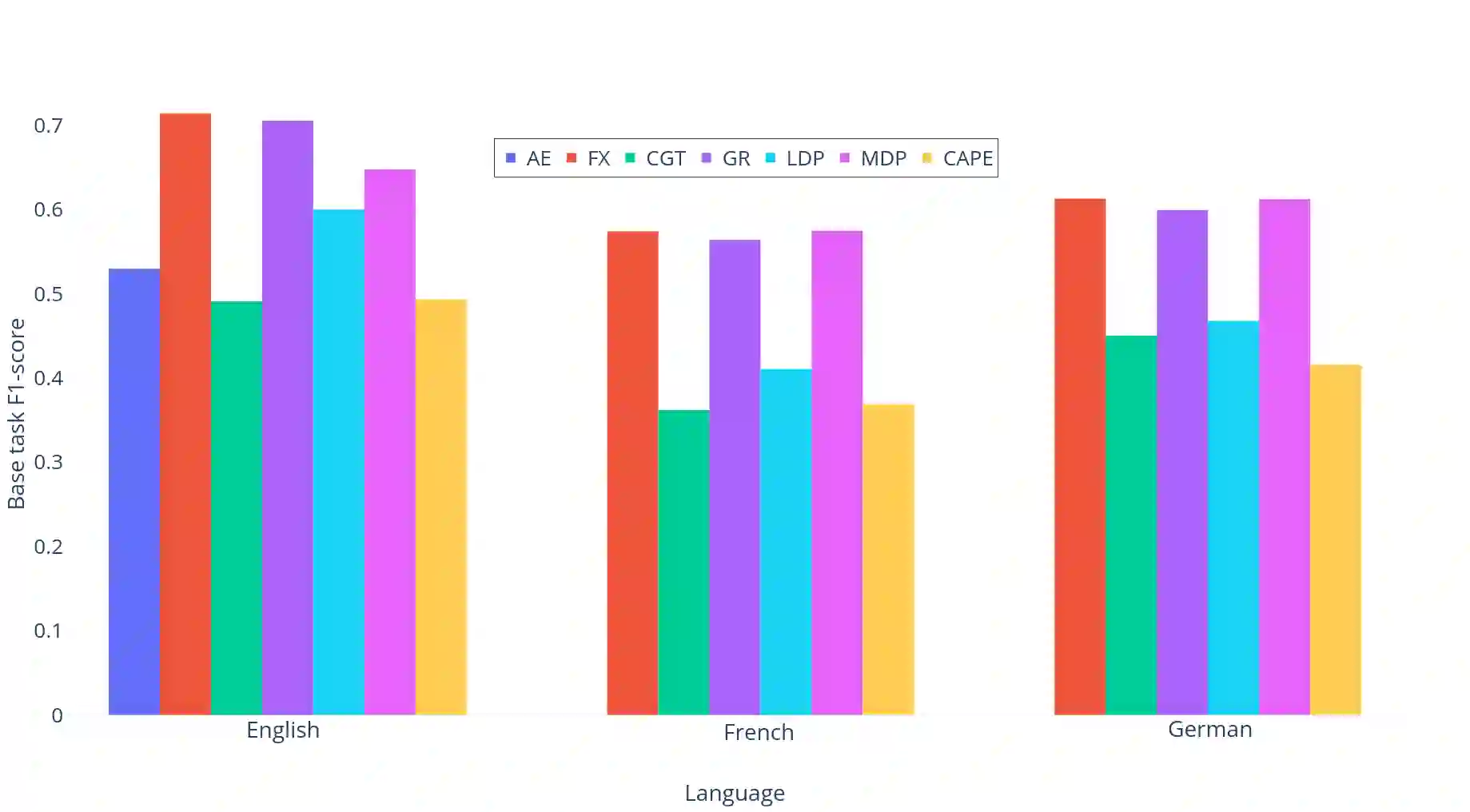
Large scale adoption of large language models has introduced a new era of convenient knowledge transfer for a slew of natural language processing tasks. However, these models also run the risk of undermining user trust by exposing unwanted information about the data subjects, which may be extracted by a malicious party, e.g. through adversarial attacks. We present an empirical investigation into the extent of the personal information encoded into pre-trained representations by a range of popular models, and we show a positive correlation between the complexity of a model, the amount of data used in pre-training, and data leakage. In this paper, we present the first wide coverage evaluation and comparison of some of the most popular privacy-preserving algorithms, on a large, multi-lingual dataset on sentiment analysis annotated with demographic information (location, age and gender). The results show since larger and more complex models are more prone to leaking private information, use of privacy-preserving methods is highly desirable. We also find that highly privacy-preserving technologies like differential privacy (DP) can have serious model utility effects, which can be ameliorated using hybrid or metric-DP techniques.
翻译:大规模采用大型语言模型为一连串自然语言处理任务带来了方便知识转让的新时代,但是,这些模型也暴露了有关数据主题的不受欢迎的信息,从而有可能损害用户的信任,而数据主题的信息可能由恶意一方通过对抗性攻击等手段获得。我们对通过一系列流行模式将个人信息编入预先培训前的表述中的程度进行了实证性调查,并显示出模型的复杂性、培训前使用的数据数量和数据泄漏之间的正相关关系。在本文中,我们介绍了对一些最受欢迎的隐私保护算法的首次广泛评价和比较,介绍了关于人口信息(地点、年龄和性别)附加说明的情绪分析的大型多语文数据集。结果显示,由于较大和更加复杂的模型更容易泄露私人信息,使用隐私保护方法是非常可取的。我们还发现,像差异隐私(DP)这样的高度隐私保护技术可以产生严重的示范效用效应,可以通过混合或计量-DP技术加以改进。