实操教程 | 年轻人的第一个深度学习图像分割项目(Pytorch框架)
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
来源丨有三AI
本文资源与图像分割结果展示

1 项目背景
图像处理中,研究者往往只对图像中的某些区域感兴趣,在此基础上才有可能对目标进行后续的处理与分析。图像分割技术就是把图像中属于目标区域的感兴趣区域进行半自动或者自动地提取分离出来,属于计算机视觉领域中最基础的任务之一。
为了让新手们能够一次性体验一个图像分割任务的完整流程,本次我们选择带领大家完成一个嘴唇图像分割任务,包括数据集的处理,模型的训练和测试,同时也将这次的实验与上一期内容结合起来。
2 数据处理
2.1 数据获取
如果没有开源的数据集,我们首先要学会使用爬虫爬取图像,然后对获得的图片数据进行整理,包括重命名,格式统一。获取后整理的图像如下:

2.2 数据标注
接下来,我们需要对数据进行标注。图像分割任务要求对每一个像素进行预测,所以需要像素级别的标注结果,当然我们实际标注的时候往往是通过画轮廓形成闭合区域,开源的标注工具有很多,我们可以使用LabelMe等工具进行标注,当然你也可以使用其他工具进行标注,这里我们就不再展开讲了,因为本文面向的读者已经不是纯新手了。
标注完之后的样本和结果如下:

需要注意的是,标注的结果并不是我们用于训练的标签,因为图像分割本身是对每一个图像像素进行分类,在当前的开源框架中,每一个像素的类别也是从0,1,2,3这样的顺序依次增加。
所以在这里,我们一定需要注意训练时候的标签处理,这个大家根据自己的实际情况进行调整。
3 数据读取
得到了数据之后,接下来咱们使用Pytorch框架来进行模型的训练,首先需要实现的就是数据读取。Pytorch本身并没有图像分割任务的数据接口,所以我们需要自己定义,读取图像和掩膜,做一些简单的数据增强操作,我们定义一个类为SegDataset如下。
class SegDataset(Dataset):
def __init__(self,filetxt,imagesize,cropsize,transform=None):
lines = open(filetxt,'r').readlines()
self.samples = []
self.imagesize = imagesize
self.cropsize = cropsize
self.transform = transform
if self.transform is None:
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
for line in lines:
line = line.strip()
imagepath,labelpath = line.split(' ')
self.samples.append((imagepath,labelpath))
def __getitem__(self,index):##获取数据
imagepath,labelpath = self.samples[index]
image = cv2.imread(imagepath)
label = cv2.imread(labelpath,0) ##读成1通道
## 添加基本的数据增强,对图片和标签保持一致
## 添加固定尺度的随机裁剪,使用最近邻缩放(不产生新的灰度值)+裁剪
image = cv2.resize(image,(self.imagesize,self.imagesize),interpolation=cv2.INTER_NEAREST)
label = cv2.resize(label,(self.imagesize,self.imagesize),interpolation=cv2.INTER_NEAREST)
offsetx = np.random.randint(self.imagesize-self.cropsize)
offsety = np.random.randint(self.imagesize-self.cropsize)
image = image[offsety:offsety+self.cropsize,offsetx:offsetx+self.cropsize]
label = label[offsety:offsety+self.cropsize,offsetx:offsetx+self.cropsize]
return self.transform(image),label ##只对image做预处理操作
def __len__(self): ##统计数据集大小
return len(self.samples)
上述的SegDataset类实现了图像分割任务数据的读取,有以下几个需要说明的地方:
-
输入的filetxt是我们预先准备好的文件,其中每一行按照[图片 标签]的对应格式存储着数据。
-
我们这里自己添加了一个随机裁剪的数据增强操作,对于裁剪类操作,标签图也需要在同样的裁剪参数下进行变换,对于颜色类操作则不需要。
接下来我们就可以来测试一下数据集的读取,分别使用简单的方法和Dataloader接口。
## 简单方法,根据index来读取某一条数据
filetxt = "data/train.txt"
imagesize = 256
cropsize = 224
mydataset = SegDataset(filetxt,imagesize,cropsize)
print(mydataset.__length__())
image,label = mydataset.__getitem__(0)
## 使用DataLoader来遍历,相关接口我们上期已经讲过,不再赘述
from torch.utils.data import DataLoader
batchsize = 64
train_dataset = SegDataset(train_data_path,imagesize,cropsize,data_transform)
train_dataloader = DataLoader(train_dataset, batch_size=batchsize, shuffle=True)
确认数据读取没有问题后,我们就可以开始来准备模型以及训练了。
4 模型训练
得到了数据之后,接下来咱们使用Pytorch框架来进行模型的训练,包括模型定义、结果保存与分析。
4.1 模型定义
接下来我们定义分割模型,首先是若干卷积层,然后是若干反卷积层。
import torch
from torch import nn
class simpleNet5(nn.Module):
def __init__(self):
super(simpleNet5, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(True),
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
)
self.conv4 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
)
self.conv5 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
)
self.deconv1 = nn.Sequential(
nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=3,
stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True)
)
self.deconv2 = nn.Sequential(
nn.ConvTranspose2d(256, 128, 3, 2, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(True)
)
self.deconv3 = nn.Sequential(
nn.ConvTranspose2d(128, 64, 3, 2, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(True)
)
self.deconv4 = nn.Sequential(
nn.ConvTranspose2d(64, 32, 3, 2, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(True)
)
self.deconv5 = nn.Sequential(
nn.ConvTranspose2d(32, 16, 3, 2, 1, 1),
nn.BatchNorm2d(16),
nn.ReLU(True)
)
self.classifier = nn.Conv2d(16, 3, kernel_size=1)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.deconv1(out)
out = self.deconv2(out)
out = self.deconv3(out)
out = self.deconv4(out)
out = self.deconv5(out)
out = self.classifier(out)
return out
if __name__ == '__main__':
img = torch.randn(2, 3, 224, 224)
net = simpleNet5()
sample = net(img)
print(sample.shape)
在这里我们需要知道的是转置卷积的API为nn.ConvTranspose2d(in_channels,out_channels,kernel_size,stride=1, padding=0, output_padding=0,groups=1, bias=True, dilation=1),其中各个参数大家可以去查API说明。
卷积的具体配置如下:
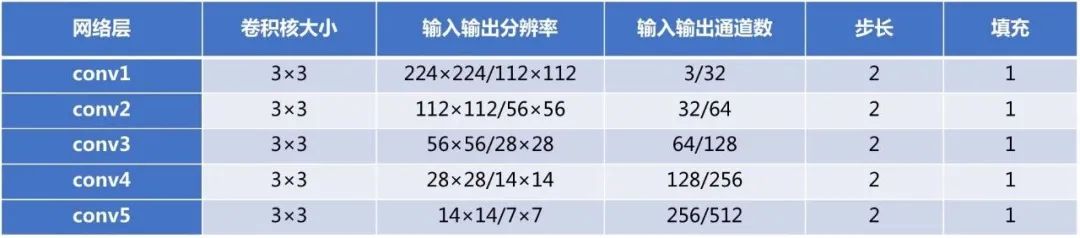
反卷积层的具体配置如下:
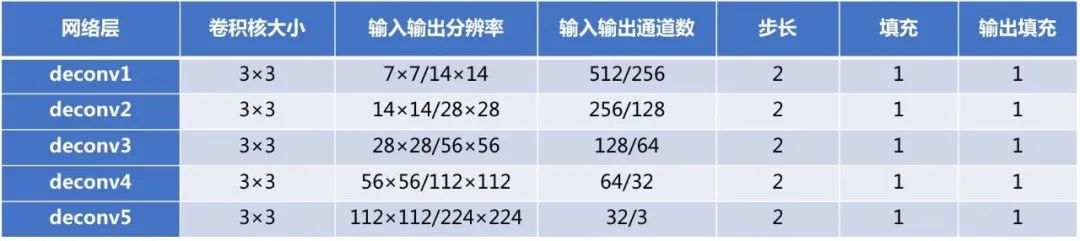
4.2 训练
数据集接口准备好之后我们进行训练,完整代码如下。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
import torchvision
from torchvision import datasets, models, transforms
import time
import os
from net import simpleNet5
from dataset import SegDataset
from tensorboardX import SummaryWriter
from torch.utils.data import DataLoader
import numpy as np
writer = SummaryWriter() #可视化
batchsize = 64
epochs = 200
imagesize = 256 #缩放图片大小
cropsize = 224 #训练图片大小
train_data_path = 'data/train.txt' #训练数据集
val_data_path = 'data/val.txt' #验证数据集
# 数据预处理
data_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
# 图像分割数据集
train_dataset = SegDataset(train_data_path,imagesize,cropsize,data_transform)
train_dataloader = DataLoader(train_dataset, batch_size=batchsize, shuffle=True)
val_dataset = SegDataset(val_data_path,imagesize,cropsize,data_transform)
val_dataloader = DataLoader(val_dataset, batch_size=val_dataset.__len__(), shuffle=True)
image_datasets = {}
image_datasets['train'] = train_dataset
image_datasets['val'] = val_dataset
dataloaders = {}
dataloaders['train'] = train_dataloader
dataloaders['val'] = val_dataloader
# 定义网络,优化目标,优化方法
device = torch.device('cpu')
net = simpleNet5().to(device)
criterion = nn.CrossEntropyLoss() #使用softmax loss损失,输入label是图片
optimizer = optim.SGD(net.parameters(), lr=1e-1, momentum=0.9)
scheduler = lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) #每50个epoch,学习率衰减
if not os.path.exists('checkpoints'):
os.mkdir('checkpoints')
for epoch in range(1, epochs+1):
print('Epoch {}/{}'.format(epoch, epochs - 1))
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
net.train(True) # Set model to training mode
else:
net.train(False) # Set model to evaluate mode
running_loss = 0.0
running_accs = 0.0
n = 0
for data in dataloaders[phase]:
imgs, labels = data
img, label = imgs.to(device).float(), labels.to(device).float()
output = net(img)
loss = criterion(output, label.long()) #得到损失
output_mask = output.cpu().data.numpy().copy()
output_mask = np.argmax(output_mask, axis=1)
y_mask = label.cpu().data.numpy().copy()
acc = (output_mask == y_mask) #计算精度
acc = acc.mean()
optimizer.zero_grad()
if phase == 'train':
# 梯度置0,反向传播,参数更新
loss.backward()
optimizer.step()
running_loss += loss.data.item()
running_accs += acc
n += 1
epoch_loss = running_loss / n
epoch_acc = running_accs / n
if phase == 'train':
writer.add_scalar('data/trainloss', epoch_loss, epoch)
writer.add_scalar('data/trainacc', epoch_acc, epoch)
print('train epoch_{} loss='+str(epoch_loss).format(epoch))
print('train epoch_{} acc='+str(epoch_acc).format(epoch))
else:
writer.add_scalar('data/valloss', epoch_loss, epoch)
writer.add_scalar('data/valacc', epoch_acc, epoch)
print('val epoch_{} loss='+str(epoch_loss).format(epoch))
print('val epoch_{} acc='+str(epoch_acc).format(epoch))
if epoch % 10 == 0:
torch.save(net, 'checkpoints/model_epoch_{}.pth'.format(epoch))
print('checkpoints/model_epoch_{}.pth saved!'.format(epoch))
writer.export_scalars_to_json("./all_scalars.json")
writer.close()
在上面代码中,我们使用了带动量项的SGD作为优化方法,配置学习率为0.1,使用了CrossEntropy损失作为优化目标,相关代码如下:
criterion = nn.CrossEntropyLoss() #使用softmax loss损失,输入label是图片
optimizer = optim.SGD(net.parameters(), lr=1e-1, momentum=0.9)
scheduler = lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) #每50个epoch,学习率衰减
另外我们使用了tensorboardX工具来进行可视化,工具使用我们之前已经介绍过了,大家可以去查看之前图像分类的内容,训练的结果如下:
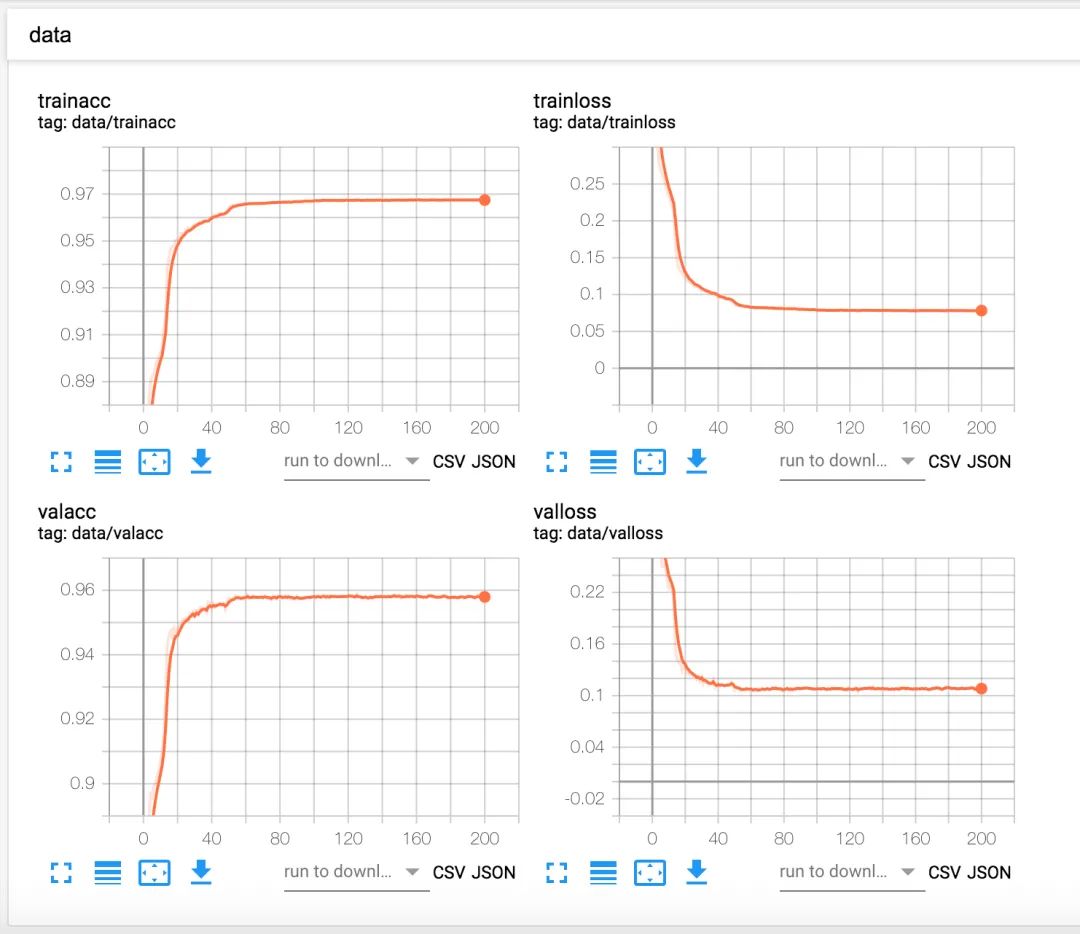
5 模型测试
上面已经训练好了模型,我们接下来的目标,就是要用它来做推理,真正把模型用起来,下面我们载入一个图片,用模型进行测试。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
import torchvision
from torchvision import datasets, models, transforms
import time
import os
import cv2
import sys
import torch.nn.functional as F
import numpy as np
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
modelpath = sys.argv[1] #模型目录
net = torch.load(modelpath,map_location='cpu')
net.eval() #设置为推理模式,不会更新模型的k,b参数
imagepaths = os.listdir(sys.argv[2]) #测试图片目录
torch.no_grad() #停止autograd模块的工作,加速和节省显存
for imagepath in imagepaths:
image = cv2.imread(os.path.join(sys.argv[2],imagepath)) #读取图像
image = cv2.resize(image,(224,224),interpolation=cv2.INTER_NEAREST)
imgblob = data_transforms(image).unsqueeze(0) #填充维度,从3维到4维
predict = F.softmax(net(imgblob)).cpu().data.numpy().copy() #获得原始网络输出,多通道
predict = np.argmax(predict, axis=1) #得到单通道label
result = np.squeeze(predict) #降低维度,从4维到3维
print(np.max(result))
result = (result*127).astype(np.uint8) #灰度拉伸,方便可视化
resultimage = image.copy()
for y in range(0,result.shape[0]):
for x in range(0,result.shape[1]):
if result[y][x] == 127:
resultimage[y][x] = (0,0,255)
elif result[y][x] == 254:
resultimage[y][x] = (0,255,255)
combineresult = np.concatenate([image,resultimage],axis=1)
cv2.imwrite(os.path.join(sys.argv[3],imagepath),combineresult) #写入新的目录
从上面的代码可知,使用torch.load函数载入模型,然后读取图像,进行与训练相同的预处理操作,就可以得到网络输出,再进行一些维度变换和softmax操作就得到最终的结果。
下面展示了一些分割结果。



从图中我们可以看到,总体的分割结果还是不错的,不过本次的任务还有许多可以提升的空间,包括但不限于:(1) 做更多的数据增强。(2) 改进模型。这些就留给读者去进行实验。
然后就可以自己输入图片得到推理结果,index就是预测的类别。
6 资源获取
本文的完整代码,可以在我们的开源项目中获取,项目地址如下:
https://github.com/longpeng2008/yousan.ai
由于数据集较大,如果想要获得数据集,请到知识星球中下载:
https://public.zsxq.com/groups/822451554112.html。
可完全可以将其替换成自己的数据集。
独家重磅课程!
1、重磅来袭!基于LiDAR的多传感器融合SLAM 系列教程:LOAM、LeGO-LOAM、LIO-SAM
2、系统全面的相机标定课程:单目/鱼眼/双目/阵列 相机标定:原理与实战
3、视觉SLAM必备基础课程:视觉SLAM必学基础:ORB-SLAM2源码详解
4、深度学习三维重建课程:基于深度学习的三维重建学习路线
5、激光定位+建图课程:激光SLAM怎么学?手把手教你Cartographer从入门到精通!
6、视觉+IMU定位课程 视觉惯性里程计58讲教程全部上线!IMU预积分/残差雅克比推导、边缘化约束、滑窗BA!
7、手把手图像三维重建课程:系统学三维重建42讲全部上线!掌握稠密匹配、点云融合、网格重建、纹理贴图!

全国最棒的SLAM、三维视觉学习社区↓

技术交流微信群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群,请添加微信号 chichui502 或扫描下方加群,备注:”名字/昵称+学校/公司+研究方向“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓

— 版权声明 —
本公众号原创内容版权属计算机视觉life所有;从公开渠道收集、整理及授权转载的非原创文字、图片和音视频资料,版权属原作者。如果侵权,请联系我们,会及时删除。


