Cross-Modal & Metric Learning 跨模态检索专题-2

前言
专题链接:
Cross-Modal & Metric Learning 跨模态检索专题-1
本专题计划分3个部分介绍图文跨模态检索的一些工作与思考。第一篇将侧重 "multi-modal" 和 "application", 介绍相关概念与研究背景;第二、三篇会侧重"algorithm" 介绍这个方向研究的技术路线,其中第二篇介绍基于 GAN 的追求公共子空间的 cross-modal 检索;第三篇则从 modal 抽象成更一般的 domain,并且将多域扩展到单域,总结分析单/多域匹配问题,主要介绍基于 contrastive learning / instances discrimination的研究思路。
本文脉络
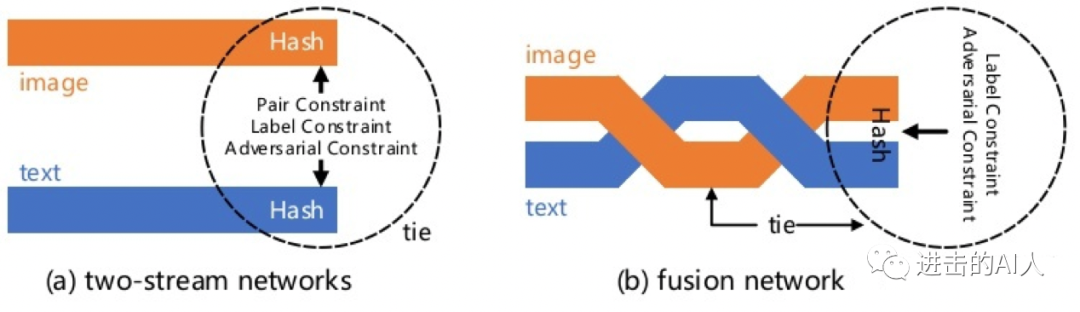
双塔结构的缺陷
"GAN" 出同一个空间
其他优化思路与应用效果
·双塔结构的缺陷
在专题的上一篇中已经提到了双塔结构模型的缺陷:
『...双塔的套路虽然简洁有效,应用广泛。但是缺点也非常明显,模型结构就能看出,不同模态的信号基本没有交互,因此往往很难学习出一个高质量的代表信号语义的 embedding。对应的度量空间/距离也就没那么准确了...』
双塔结构的优点是两种模态特征计算互不干扰,在得到顶层 embedding 后可以更加灵活的应用到下游任务中。而这一点也正是造成双塔结构具有上述缺点的原因。有时候贪婪也是发展的动力,对于双塔结构模型,我们既想要保留其特征计算互不依赖的优点,又想要消除其两种模态互不相识的缺点。总之:

可能有些不熟悉的同学看了上面这些文字表述后,依然对这种结构的缺点不是特别理解。下面以一个实际的例子,用数学语言和可视化数据来进一步解释下。
假设我们研究的双塔结构是下图这样的,图片和文本两个模态的数据分别来自2048维的空间 (
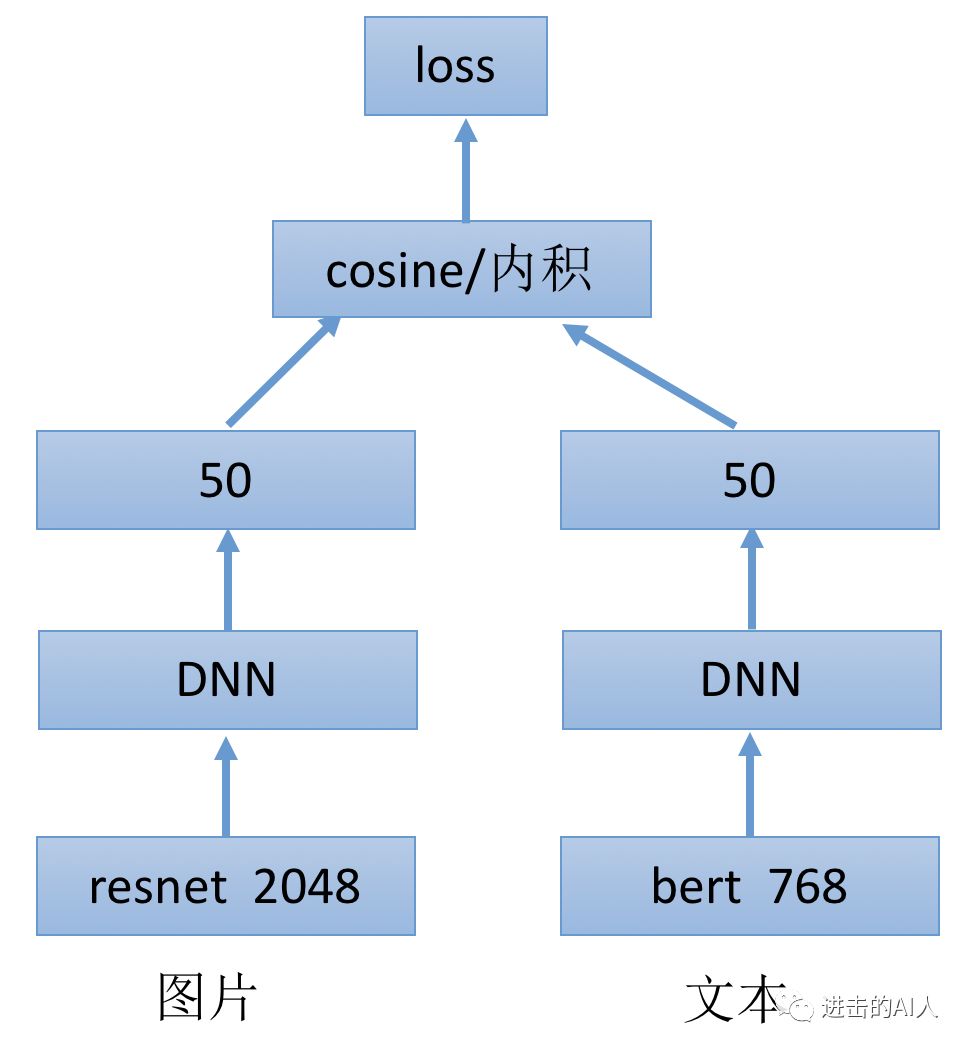
那么这两个子空间是同一个语义空间(common subspace)吗?
从上图模型的 Loss 来看,是通过约束图文两个塔的顶层 embedding 的距离来更新权重的。具体一点就是,如果输入样本中的图片和文本是有关联的正例 pair,那么左右两塔的50维向量应该距离很近;反之,如果样本中图片和文本是无对应信息的负例 pair,那么距离就应该很远。
虽然还回答不了"左右50维embedding是否在共同的子空间?" 这个问题,但是从上面 Loss 的设定来看,我们是希望左右双塔得到的是一个公共子空间的。因为只有在同一个空间中,度量距离才有意义!在同一个公共子空间中去比较两个向量数据,才更准确也更可解释。
那么这2个空间到底是否是公共的呢?从数学角度讲肯定是同一个实数空间,但我们这里讨论的是语义空间。还是以上面模型为例,我们将左右两个模态的数据用可视化方法展示出来,如下图所示:
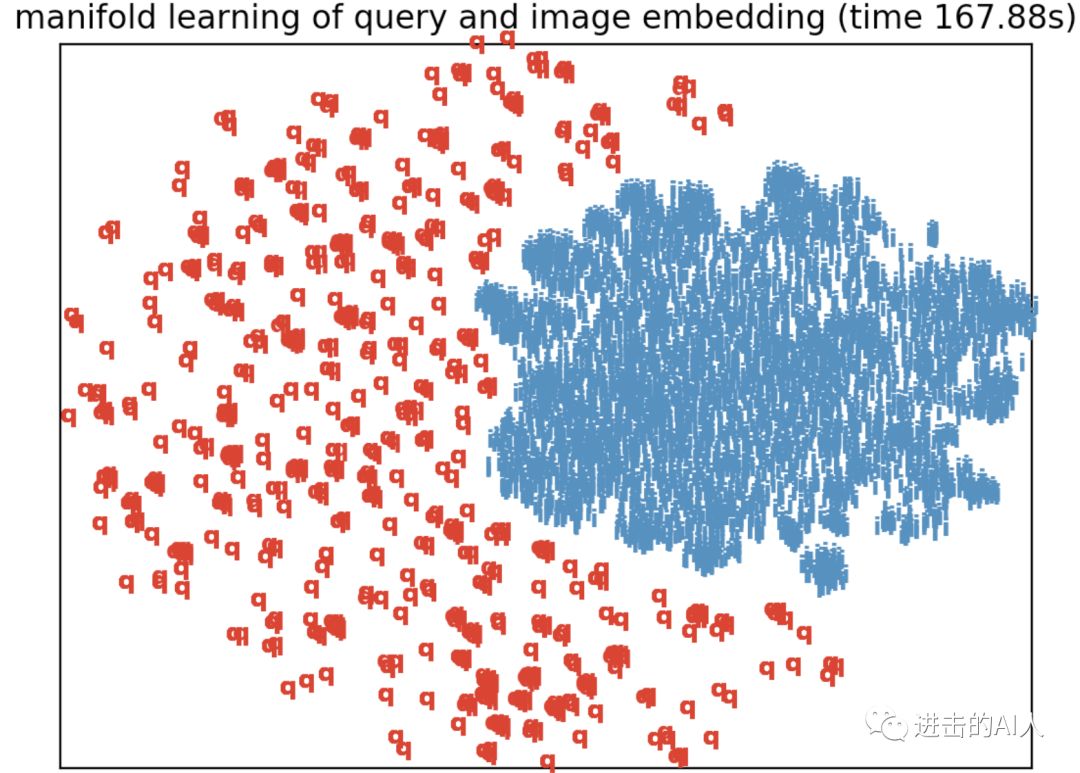
红色的 q 代表文本样本,青色的一簇则代表图片样本。可以直观的看到,上面双塔模型学习出的顶层 embedding,虽然都在50维空间中,但是有一条明显的分界线,即从语义角度来看,这是2个明显不同的存在模态差异的空间。
想要在这样的空间分布中,只用 cosine/内积距离来度量两个模态的语义相关性联系,无疑是非常困难且不太准确的。
·GAN 出同一个空间
上面的 case 来看,图片和文本的两个子空间,一眼就能分辨出类别。有什么办法能让这两个空间融合到一起,消除不同模态的差异呢?很容易想到一个很火的方向:GAN。不要怂,就是GAN!利用它,可以 GAN 出一个公共子空间,让我们无法区分哪个是图片,哪个是文本。
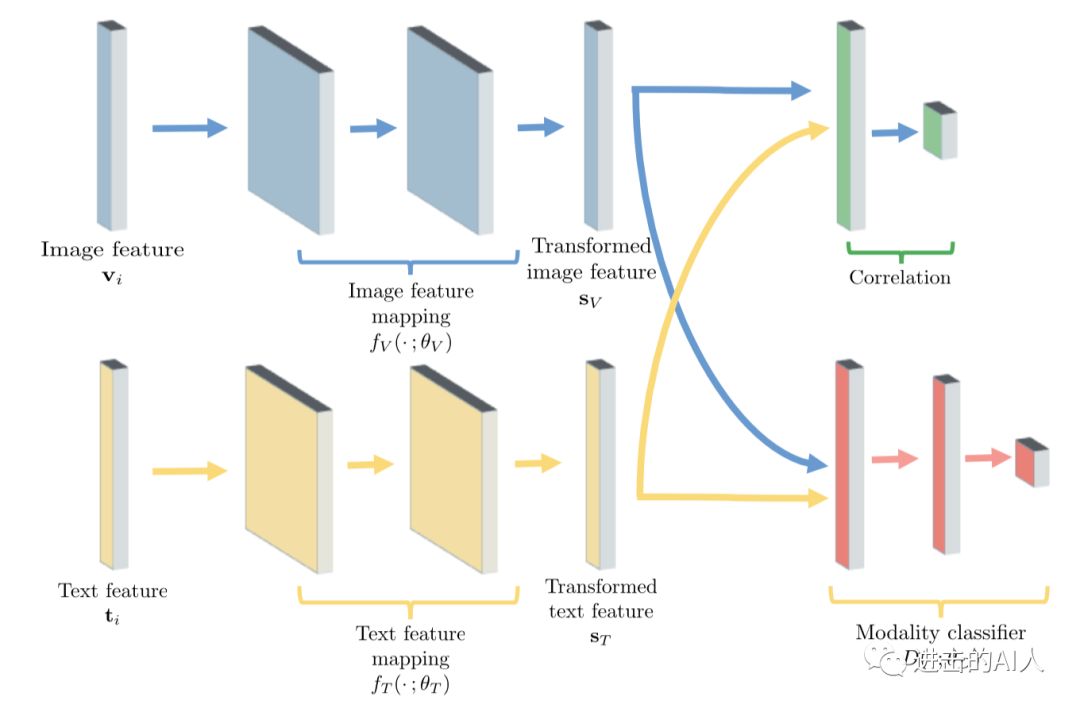
Fig. 图片是 UCAL 模型结构图
引入 GAN 的目标是很明确的,引入方法也是很简单的。只要在之前的双塔模型上增加一个判别器 Discriminator,即上图中右下角红色部分的 modality classifier。这个判别器 D 的任务是区分输入的 embedding 是图片的还是文本的。
引入 GAN 思想来改进双塔结构后,模型就有了2个任务/Loss。一个是之前的利用图文 pair 关系约束距离的 Loss,另一个是新增的判别器 Loss。判别器的 Loss 可简单的设计成一个二分类 Cross-Entropy Loss,输入是图片侧的塔和文本侧的塔的顶层 embedding,输出是预估该 embedding 是来自于哪一个分支。上图左侧生成图文顶层 embedding (Sv, St) 的这部分网络相当于是生成器 Generator。
G 想生成2个融合的空间,D 想生成的是2个有鸿沟的空间,2个 Loss 是相反的,这样一个对抗网络结构就完成了。当 G 和 D 都训练的稳定后(理想状态就是纳什均衡)此时双塔网络模型得到的顶层 embedding 则会处于一个公共子空间,互相间减少了模态鸿沟。经过 GAN 思路优化前后的空间分布对比图如下
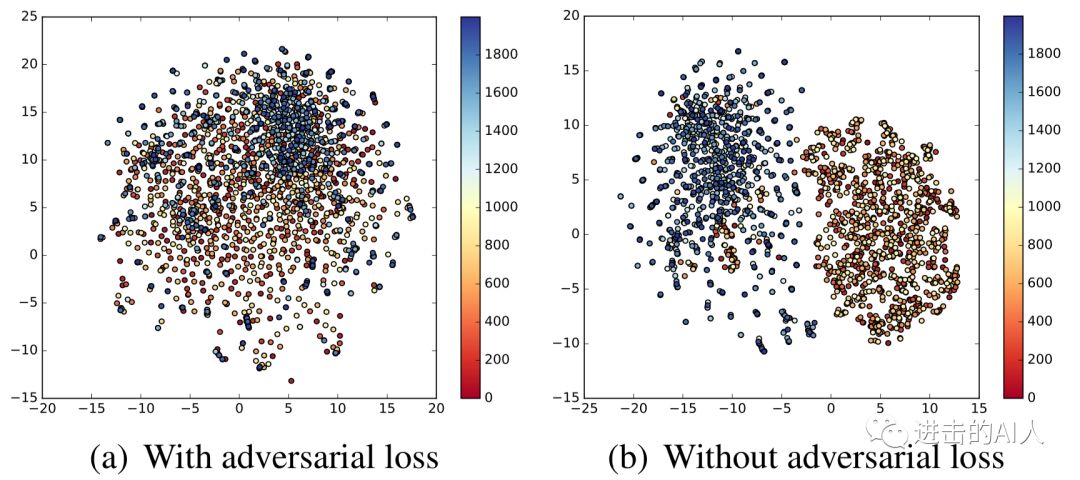
引入 GAN 对抗的思路比较简单,容易想到。但是,实际工作中想要训练成功还是很难的。众所周知 GAN 的训练需要大量的人工介入,hand-design 的痕迹很重。再者,在广告、推荐等场景下的双塔模型,其训练样本可达千万级亿级,所以都是分布式训练。在分布式场景下调整好一个对抗模型就更难了。
这里简单提一个常用的 GAN 训练技巧,即 G 和 D 同时训练。Loss 的符号和梯度的更新范围这些基础就不说了。只提下梯度翻转层 Gradient Reverse Layer (GRL)。在实际应用时,我发现在训练中 GRL 的权重 l,最好做到随着已经进入模型的 instance 的个数而变化,我一般称为 DGRL,动态梯度翻转层。下面提供使用 TensorFlow 的一种实现方式。
class FlipGradientBuilder(object):def __init__(self):self.num_calls = 0#名称只能用一次,故此迭代运行的时候需要更换名称def __call__(self, x, l=1.0):grad_name = "FlipGradient%d" % self.num_calls#自定义 求导, reverse 梯度, 正向时透明,反向时,乘以-l#下面这个首先定义自己的导数@ops.RegisterGradient(grad_name)def _flip_gradients(op, grad):return [tf.negative(grad) * l]#下面是forward时,透明,所以重写自定义的导数,直接y=x。用identity是和y=x有一些性质区别,必须用identityg = tf.get_default_graph()with g.gradient_override_map({"Identity": grad_name}):y = tf.identity(x) #tf.identity属于tensorflow中的一个ops,跟x = x + 0.0的性质一样self.num_calls += 1return yflip_gradient = FlipGradientBuilder()
·其他优化思路与应用效果
运用了对抗学习的思路后,将不同模态数据融合到同一个子空间中,确实有助于消除模态间的鸿沟。但是仅凭这一个优化点是还是很难实现不同模态语义同分布的。我们首先分析下一个合格的公共子空间应该具备拿下性质:

上图中的几点特性都是我们追求的语义同分布的目标。其中业务特征也很重要,举个例子:在文本侧 pre-trained 的模型 embedding中,在“华为”这个词附近的可能是"小米",但是在检索业务中,我们希望检索"华为"时,召回最近的是" magic book 笔记本"、"荣耀手机"等相关的图片或者文本,而不是小米相关的东西。
除了使用对抗学习消除模态鸿沟,获得公共子空间外。还有很多其他的优化思路,由于这些内容很多很杂,而且有的属于本专题第3篇的范畴内,所以这里只简单的罗列几个常用的代表性方法。
1)检索系统中有一类是最终基于哈希码的 HASH 方法。这里用 HASH 更多的是出于工程性能的应用,本身并不在我们讨论的算法范围内。不过既然应用的多,那么第一个优化思路就介绍下18年 CVPR 的相关工作:自监督对抗哈希(SSAH)。
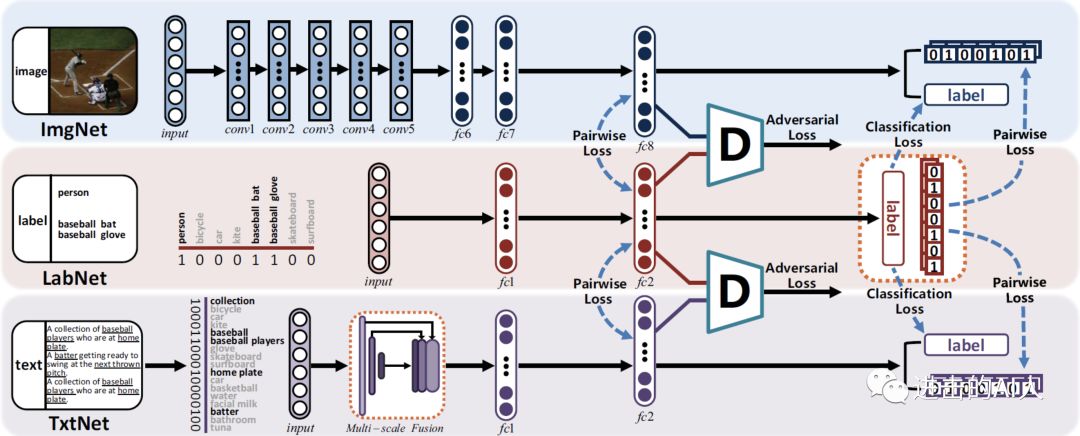
Fig. SSAH 的 framework
这个也是GAN对抗的思路, 只是多了一个 LabNet,有2个对抗模块。因为很多业务数据中,并不存在这个 label(这里是要求一个多标签的 label),所以也不是特别好直接套用。主要思路还是 GAN,所以不多介绍了。
2)除了使用 GAN 来追求公共子空间外,还有一类方法是让双塔都经过一个相同权重的 layer,一般会选择最后一层 FC layer 来共享权重。比如19年 CVPR 的文章 DSCMR 就使用了这个方法,结合着多个 loss 的设计也得到了一个不错的效果。
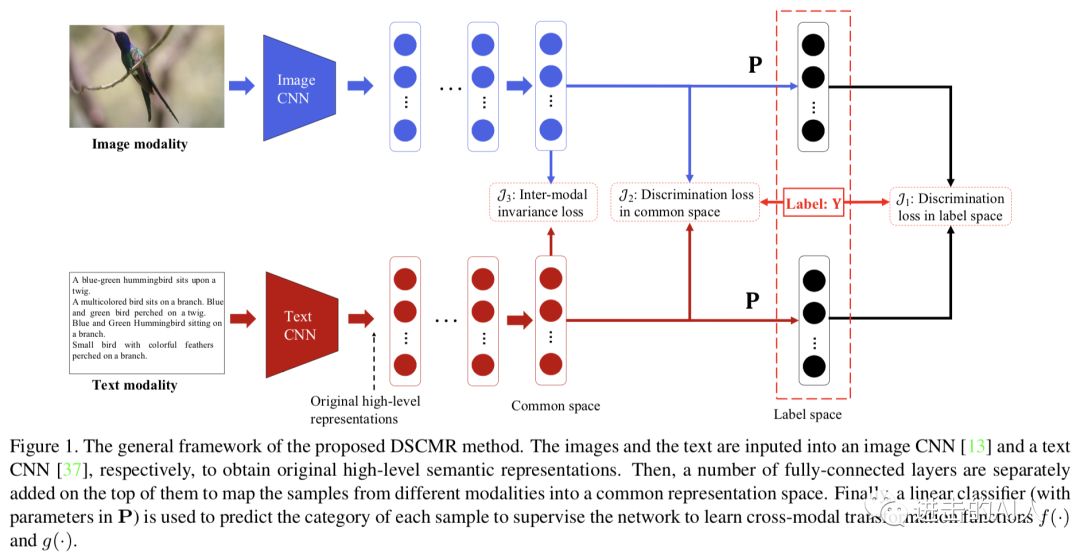
补充一点,共用一个全链接层这个方法,如果 Loss 不做相应的优化设计,很多业务场景中其实没效果。。。
3)让不同模态数据在语义层面融合的更好,这个目标可以拆解成:同模态内部(intro-modal) + 跨模态之间(inter-modal)。同模态内部可以使用模态内数据的 label 来增加一个额外的分类 task 训练,比如图片都有一个100类的类别标签。至于跨模态之间的约束,方法就非常多了,比如最通用的 margin-based loss,可以用pair-wise loss,也可以是 triplet-loss。17年 MM 的 best paper ACMR也是在 GAN 基础上用了这2点。
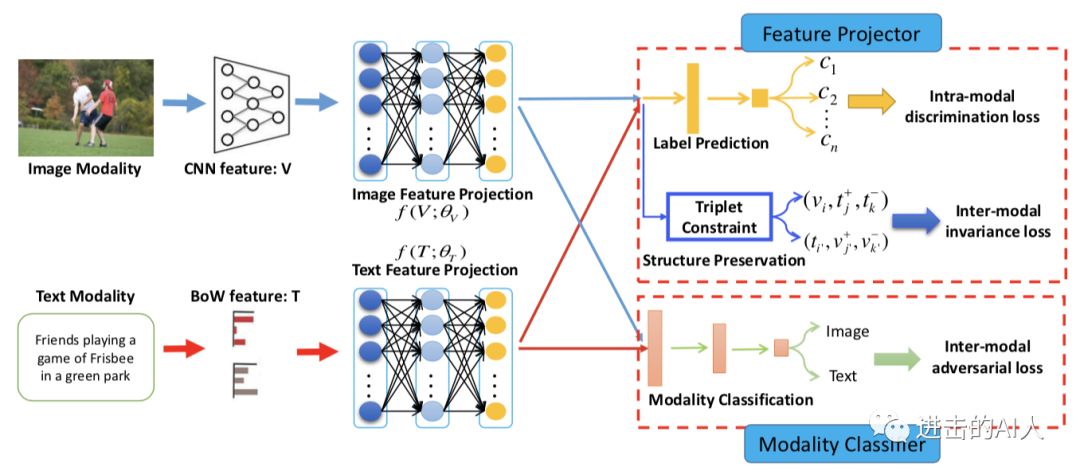
Fig. ACMR 的 framewor
在实际应用时,想补充以下几点。第一点是关于同模态内部的分类 loss。这个实际中,我们都是直接用 pre-trained 模型得到基本特征,所以额外增加这个 loss 基本没有作用,除非 lable 是具有特定的业务特性的。图片和文本的这个 label 体系可以不同,也可以相同。第二点是 GAN 的作用,或者说增加了对抗 Loss 后模型的指标怎么样?如果用AUC 评估的话,基本没啥提升。用检索指标评估,只能说略有提升吧。。。
我们在实际工作中独立的设计了一个几乎一模一样的模型,后来看到了这篇工作后,也做了对比。我们的模型多了一个 Loss,也更好的利用了 transfer 能力,弱化了这篇文章的个别优化点的影响。所以从一些拆解分析来看,这篇文章提到的个别优化点,在实际工作中都没有什么明显效果。
至于文章用到的 triplet loss,这个不算新东西,在类似任务中几乎每个人都尝试过 triplet Loss、contrastive loss 之类的替代品。本篇不在赘述,将在下篇结合最近很火的无监督表示学习/contrastive learning 一起详细讨论。
4)还有很多不错的工作,比如19年 ICMR 的 TFNH 工作,在 ACMR 的启发下对模型结构做了一些有意思的探索。重点是引入了不成对训练数据,但其实和 ACMR 的模态内部分类 Loss 一样,在运用了 pre-trained 模型后,作用应该不大了。文章思路比较简单,不展开介绍,感兴趣的同学可以自己去搜下 github 代码。
简单小结下:
目前优化思路有3类方向:A)利用 GAN 等方法追求公共子空间消除模态差异。B)改进模型结构和增加多任务目标提升模态内部、模态之间的语义同分布能力。C)设计更好的距离 Loss 让模型学习的更充分更高效更准确。这3个方向不是互斥的,很多优秀的工作都是同时应用了这3点。本专题下一篇会聚焦在 C 方向介绍。
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。


