【论文】所见所想所真,对抗学习GAN提升跨模态检索效果!阿里巴巴AI Labs等团队最新工作
【导读】近日,新加坡南洋理工大学、美国莱斯大学和阿里巴巴AI Labs联合提出了一种采用生成模型(Generative Models)来提升跨模态检索效果的方法。该方法在文本-视觉卷积跨模态特征表示中引入了图像-文本生成和文本-图像生成两种模型,使得最终的提出的生成式跨模态特征学习框架(generative cross-modal feature learning framework,GXN)不仅可以学习到高层的全局的抽象表示,还能有效地学习到局部的底层特征表示来捕捉两个模态之间精细的局部相似度。该方法在MSCOCO数据集上超过了现有的最好的方法。
论文:Look, Imagine and Match: Improving Textual-Visual Cross-Modal Retrieval with Generative Models

▌摘要
视觉-文本跨模态检索已经成为计算机视觉和自然语言处理领域的一个热点。为多模态数据学习出一个合适的表示空间对跨模态检索极其重要。不同于现有的将图像-文本对表示为单个的特征对并嵌入到一个公共表示空间的方法,这篇文章提出融合生成过程到跨模态表示中,这样不仅能学习到全局的抽象特征还能学习到局部的底层特征。大量的实验显示出提出的方法可以在复杂的内容中精准地匹配图像和文本描述,并且在MSCOCO数据集上进行的跨模态检索实验中取得了state-of-the-art的效果。
▌概述摘要
我们已经进入到了一个大数据时代,不同模态的数据例如文本,图像,视频正在以爆炸性的速度增长。这些模态展现出了异质的属性,使得用户很难快速高效地搜索到满意的搜索结果。所以,文本-视觉跨模态检索已经成为了一个计算机视觉和自然语言处理领域的研究热点。跨模态检索的核心是学习出一个合适的多模态数据表示空间,使得不同模态的数据可以在这个表示空间内进行直接的比较。
近年,研究人员已经提出了大量的方法来弥补不同模态之间的语义鸿沟。对于文本-视觉的跨模态表示,常见的方法就是首先每个模态的数据编码成各自的表示特征,然后将他们映射到一个共同的语义空间内,然后使用一个ranking loss来对其进行优化,使得相似的图像-文本对映射出的特征向量之间的距离小于不相似的图像-文本对之间的距离。尽管这种方法学习出的公共空间可以很好地描述多模态数据高层的语义概念,但是没有充分地挖掘图像的局部精细相似度和句子的词层次相似度。例如,人类在进行文本和图像的匹配时,会更多地关注他们中存在的细节信息,使得文本和图像的关联更加精准。换句话说,如果将一个模态的表示转换成另一个模态的表示,我们可以学习到一个更好的映射。
受到上述概念的启发,这篇文章在进行传统的全局语义层次上的文本-视觉跨模态表示之外,还引入文本-图像和图像-文本两个生成模型来进行局部层次的跨模态特征表示。下图展示了这种基本概念。
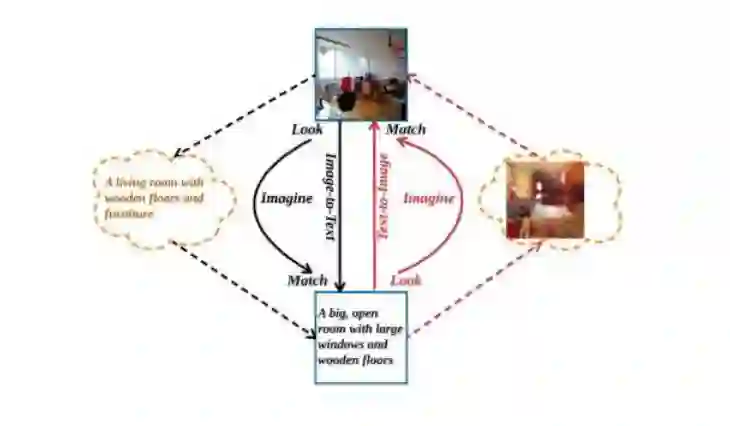
图1: GXN模型的主旨:主要包含三个步骤:Look,Imageine和Match。Look:给出一个查询文本或图像,提取出对应的抽象表示。Image:将第一步中得到的一种模态的特征表示生成为另一种模态表示,并将其和真实数据进行比较来生成一个更加精细的底层表示。Match:使用组合了高层抽象表示和局部底层表示的特征表示来进行图像-文本对的关联匹配。
▌详细内容
总体框架
图2展示的GXN模型的的总体结构,它主要包括三个模块:多模态特征表示部分(整个上部区域),图像-文本生成特征学习部分(蓝色通道)和文本-图像生成对抗特征学习部分(绿色通道)。
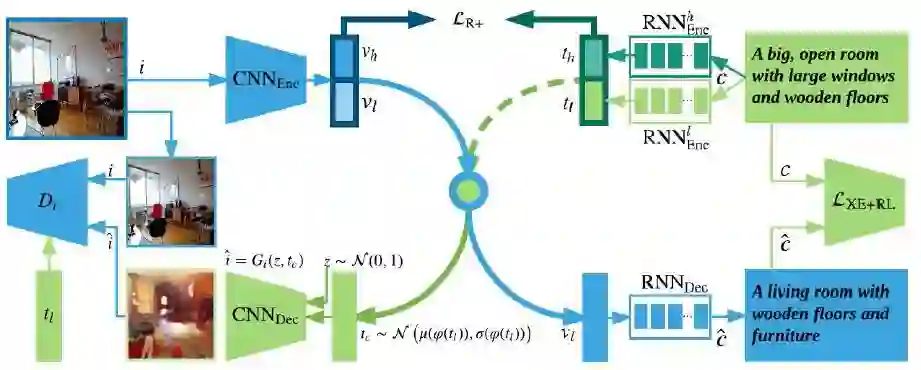
图2: 提出的生成式跨模态特征学习框架(generative cross-modal feature learning framework,GXN)
第一个部分相似于已经存在的跨模态特征表示:将不同模态的特征映射到一个公共的空间;不同之处在于本文使用了两路的特征表示来使表示出的视觉特征和文本特征接近。在这里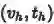
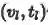
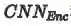
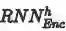

第二部分(蓝色通道)利用底层视觉特征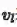
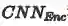
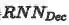
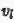
第三部分(绿色通道)通过使用一个生成对抗模型来从文本特征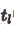
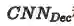
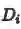
最终,通过两路的跨模态特征生成学习,希望学习到强大的跨模态特征表示,在测试时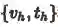
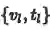
跨模态特征表示
给出一个图像-文本对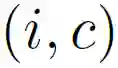
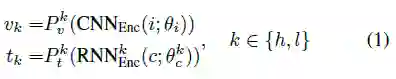
其中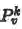
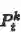

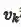
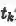
与普通的跨模态特征表示方法一样,本文使用了一个二元ranking loss来学习模型参数,考虑到两路的跨模态特征表示,loss函数可写为:
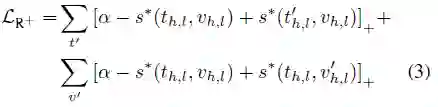
其中,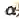
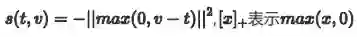
图像-文本生成特征学习
对于图像-文本的训练通道,目标是让底层的特征表示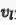
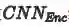
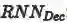
训练时,首先使用一个word-level的交叉熵损失:
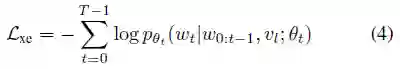
为了直接优化metrics,使用了最小化负期望奖赏来优化模型:
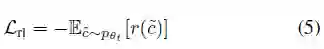
最终的损失函数为:
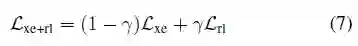
文本-图像生成对抗特征学习
对于文本-图像的训练通道,目标是让底层的特征表示
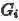
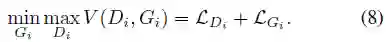
其中判别器损失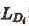
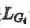
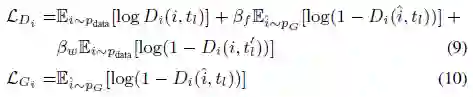
考虑到数据的数量限制和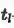
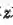
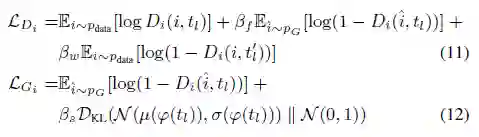
▌实验结果
本文设置了多种baseline进行比较,证实了提出的两种生成模型的有效性:
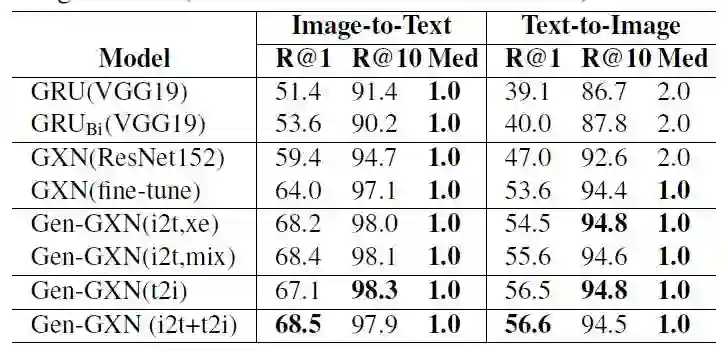
表1:在MSCOCO 1K-image测试集上的跨模态检索结果
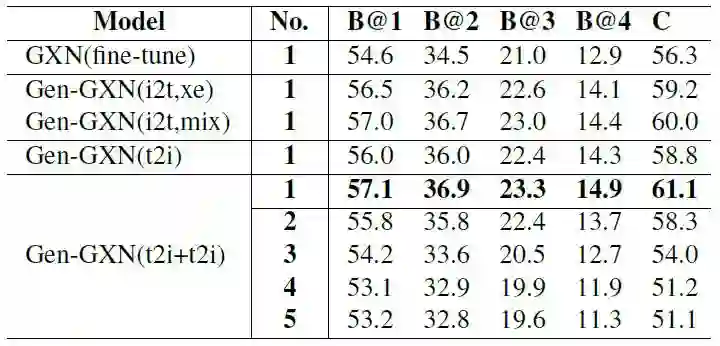
表2:在MSCOCO 1K-image测试集上使用sentence-level metrics对检索的captions的质量进行评估。
与MSCOCO数据集上state-of-the-art方法的比较:
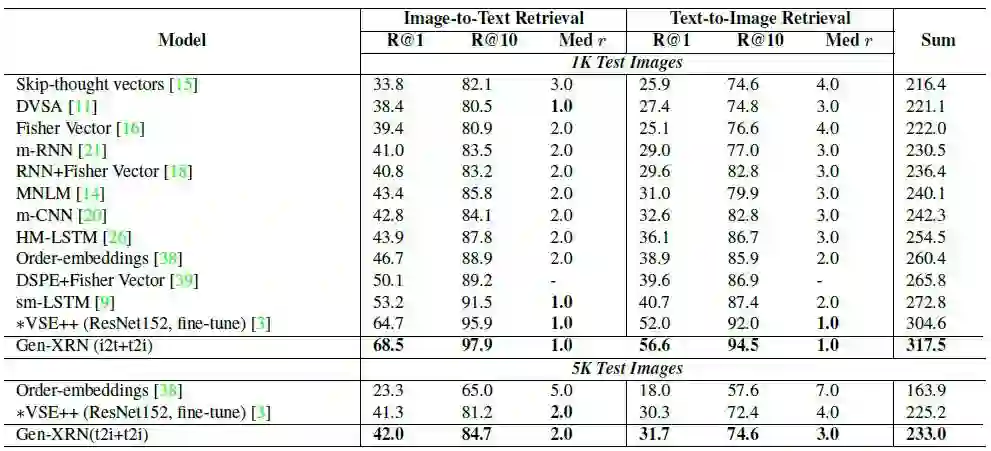
表3:在MSCOCO 数据集上和当前前沿的方法进行跨模态检索的比较结果。
可视化检索结果:

图5:跨模态检索的结果。
可视化word embedding:

图6:word embedding的可视化结果
▌总结
本文提出了一种新颖的特征表示来进行跨模态检索。创新性地将图像-文本生成模型和文本-图像生成模型引入到传统的跨模态表示中,使其不仅能学习到多模态数据的高层的抽象表示,还能学习到底层的表示。显著超越state-of-the-art方法的表现证实了该方法的有效性。
参考链接:
https://arxiv.org/abs/1711.06420
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!


