谷歌AI歌手震撼来袭!AudioLM简单听几秒,便能谱曲写歌

来源:新智元
本文为约2273字,建议阅读4分钟
本文介绍
了谷歌研究团队推出的语音生成的AI模型——AudioLM

图像生成模型卷起来了!视频生成模型卷起来了!
下一个,便是音频生成模型。

近日,谷歌研究团队推出了一种语音生成的AI模型——AudioLM。
只需几秒音频提示,它不仅可以生成高质量,连贯的语音,还可以生成钢琴音乐。

论文地址:https://arxiv.org/pdf/2209.03143.pdf
AudioLM是一个具有长期一致性的高质量音频生成框架,将输入的音频映射为一串离散的标记,并将音频生成任务转化为语言建模任务。
现有的音频标记器在音频生成质量和稳定的长期结构之间必须做出权衡,无法兼顾。
为了解决这个矛盾,谷歌采用「混合标记化」方案,利用预训练好的掩膜语言模型的离散化激活,并利用神经音频编解码器产生的离散代码来实现高质量的合成。
AudioLM模型可以基于简短的提示,学习生成自然和连贯的连续词,当对语音进行训练时,在没有任何记录或注释的情况下,生成了语法上通顺、语义上合理的连续语音,同时保持说话人的身份和语调。
除了语音之外,AudioLM还能生成连贯的钢琴音乐,甚至不需要在任何音乐符号来进行训练。
从文本到钢琴曲:两大问题
近年来,在海量的文本语料库中训练出来的语言模型已经显示出其卓越的生成能力,实现了开放式对话、机器翻译,甚至常识推理,还能对文本以外的其他信号进行建模,比如自然图像。
AudioLM的思路是,利用语言建模方面的这些进展来生成音频,而无需在注释数据上进行训练。
不过这需要面对两个问题。
首先,音频的数据率要高得多,单元序列也更长。比如一个句子包含几十个字符表示,但转换成音频波形后,一般要包含数十万个值。
另外,文本和音频之间存在着一对多的关系。同一个句子可以由不同的说话人以不同的风格、情感内容和环境来呈现。

为了克服这两个挑战,AudioLM利用了两种音频标记。
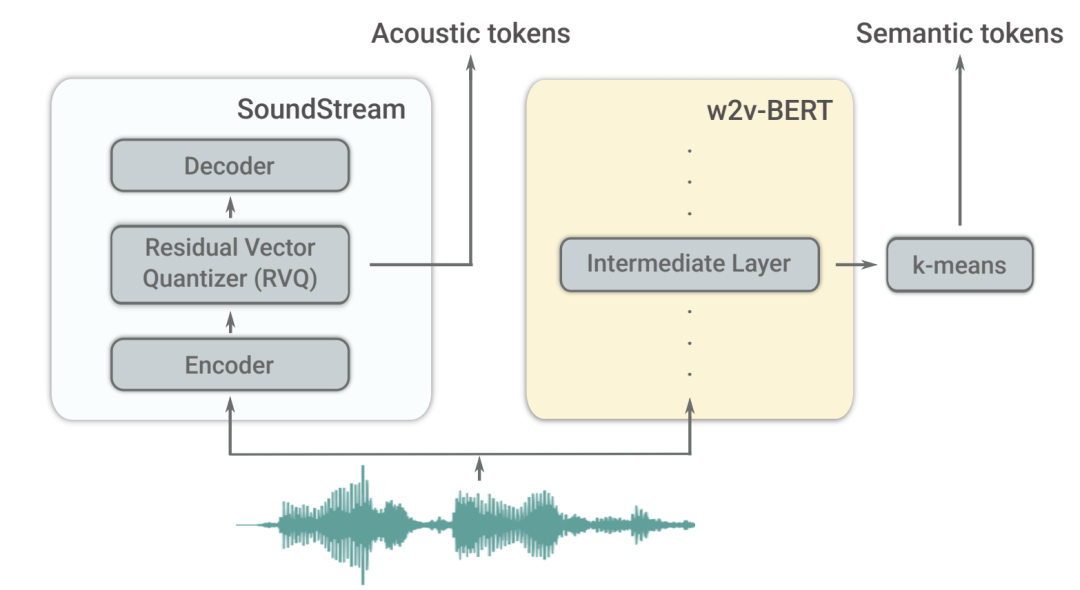
首先,语义标记是从w2v-BERT这个自监督的音频模型中提取的。
这些标记既能捕捉到局部的依赖关系(如语音中的语音,钢琴音乐中的局部旋律),又能捕捉到全局的长期结构(如语音中的语言句法和语义内容,钢琴音乐中的和声和节奏),同时对音频信号进行大量的降采样,以便对长序列进行建模。
不过,从这些token中重建的音频的保真度不高。
为了提高音质,除了语义标记外,AudioLM还利用了SoundStream神经编解码器产生的声学标记,捕捉音频波形的细节(如扬声器特征或录音条件),进行高质量的合成。
如何训练?
AudioLM是一个纯音频模型,在没有任何文本或音乐的符号表示下进行训练。
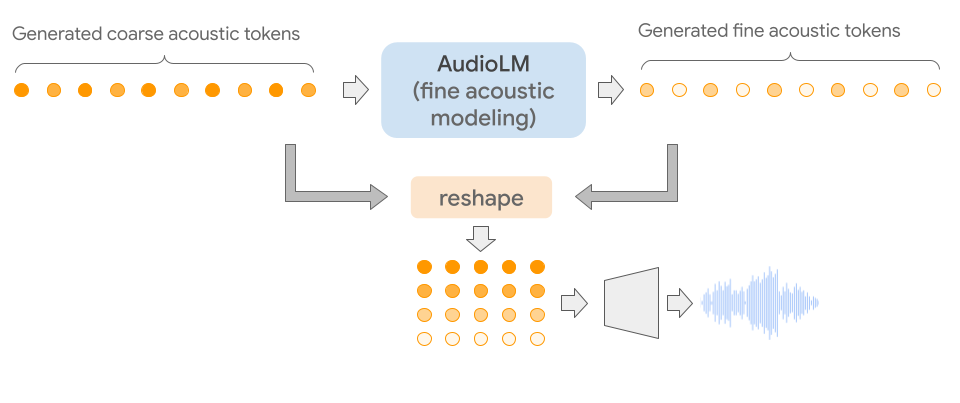
它通过链接多个Transformer模型(每个阶段一个)从语义标记到精细的声学标记对音频序列进行分层建模。
每个阶段都会根据上次的标记为下一个标记预测进行训练,就像训练一个语言模型一样。
第一阶段在语义标记上执行此任务,以对音频序列的高级结构进行建模。

到了第二阶段,通过将整个语义标记序列与过去的粗声标记连接起来,并将两者作为条件反馈给粗声模型,然后预测未来的标记。
这个步骤模拟了声学特性,例如说话者特性或音乐中的音色。

在第三阶段,使用精细的声学模型来处理粗糙的声学信号,从而为最终的音频增加了更多的细节。
最后,将声学标记输入SoundStream解码器以重建波形。
训练完成后,可以在几秒钟音频上调整AudioLM,这能够让其生成连续性的音频。
为了展示AudioLM的普遍适用性,研究人员通过在不同音频领域的2个任务对其进行检验。
一是Speech continuation,该模型保留提示的说话人特征、韵律,同时还能输出语法正确且语义一致的新内容。
二是Piano continuation,该模型会生成在旋律、和声和节奏方面与提示一致的钢琴音乐。
如下所示,你听到的所有灰色垂直线之后的声音都是由AudioLM生成的。
为了验证效果如何,研究人员让人类评分者去听简短的音频片段,去判断是人类语音的原始录音还是由 AudioLM生成的录音。
根据收集到的评分,可以看到AudioLM有51.2%的成功率,意味着这一AI模型生成的语音对于普通听众来说很难与真正的语音区分开来。
在东北大学研究信息和语言科学的Rupal Patel表示,之前使用人工智能生成音频的工作,只有在训练数据中明确注释这些细微差别,才能捕捉到这些差别。
相比之下,AudioLM从输入数据中自动学习这些特征,同样达到了高保真效果。
随着 GPT3 和 Bloom(文本生成)、 DALLE和Stable Diffusion(图像生成)、RunwayML和Make-A-Video(视频生成)等多模态 ML 模型的出现,关于内容创建和创意工作正在发生变化。
未来的世界,便是人工智能生成的世界。




