SoundStream 神经音频编解码器,无损音乐顷刻入耳


发布人:Google Research 研究员 Neil Zeghidour 和 Marco Tagliasacchi
音频编解码器通常可以有效地压缩音频,以此减少对存储空间的需求或网络带宽。理想情况下,音频编解码器对最终用户来说应是透明的,这样解码后的音频在感觉上便可与原始音频几无差别,且编码/解码过程不会存在感知延迟。
在过去的几年里,我们已经成功开发出不同的音频编解码器,如 Opus 和增强型语音服务 (Enhanced Voice Services,EVS),以此满足这些要求。Opus 是一种多功能的语音和音频编解码器,支持 6 kbps(每秒千比特)到 510 kbps 的比特率。目前它已被广泛部署在视频会议平台(如 Google Meet)和在线媒体服务(如 YouTube)等各种应用中。EVS 则是由 3GPP 标准化组织开发、针对移动电话 (Telephony) 的最新编解码器。与 Opus 一样,它也是多功能编解码器,可在 5.9 kbps 至 128 kbps 之间的多个比特率下运行。这两种编解码器,无论使用哪一种,只要是在中低比特率(12 至 20 kbps)下重建的音频,其质量都很好。但是若在非常低的比特率 (⪅3 kbps) 下运行时,音频质量便会急剧下降。虽然这些编解码器通过利用人类感知方面的专业知识,以及精心设计的信号处理流水线,能够最大限度地提高压缩算法效率,但人们仍希望用机器学习方法来取代这些人工流水线,通过数据驱动的方式对音频进行编码。
今年早些时候,我们发布了 Lyra,一个用于低比特率语音的神经音频编解码器。在“SoundStream:一个端到端神经音频编解码器”一文中,我们介绍了一个新颖的神经音频编解码器,它能提供更高质量的音频,并扩展至编码不同的声音类型(包括干净的语音、噪音和混响的语音、音乐和环境声音),这推动了进一步的发展。SoundStream 不仅是第一个用于语音和音乐的神经网络编解码器,还能在智能手机 CPU 上实时运行。此外,它还具备在广泛比特率范围内,以单一训练模型呈现最高质量的能力这代表着可学习编解码器方面的一个重大进步。
SoundStream:一个端到端神经音频编解码器
https://arxiv.org/abs/2107.03312


虽然人们可以毫不费力地推理如,话题持续时间、频率或对话中事件先后顺序等日常的时间概念,但这类任务对于对话代理而言则具有较大的挑战。例如,目前的 NLP 模型在执行填空任务时,经常会做出糟糕的决定(如下图所示),因为我们通常会假设其在推理方面仅具备基本的世界知识水平,或者需要理解整个对话回合中时间概念之间显性和隐性的相互依赖关系。
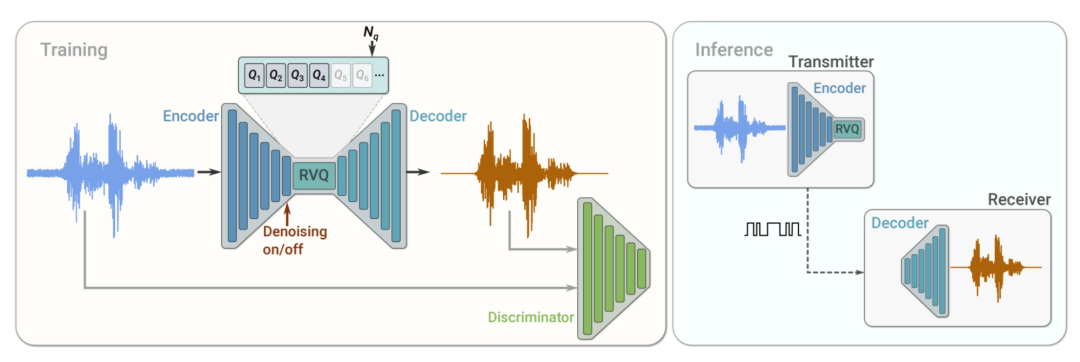
SoundStream 训练和推理。在训练过程中,使用重建和对抗性损失的组合对编码器、量化器和解码器参数进行优化,这些损失是由判别器(训练后用于区分原始输入音频和重建的音频)计算得出。在推理过程中,发射器客户端上的编码器和量化器将压缩的比特流发送到接收器客户端,然后接收器客户端就能对音频信号进行解码
SoundStream 的编码器可产生无限多值的向量。为了用有限的比特数将这些向量传输至接收器,需要用一个与有限的集合(称为码本)接近的向量来代替它们,这个过程被称为向量量化 (Vector quantization)。这种方法在比特率为 1 kbps 左右或更低的情况下效果很好,但在使用更高的比特率时,很快就会达到极限。例如,即使比特率低至 3 kbps,且假设编码器每秒产生 100 个向量,也需要存储一个包含超过 10 亿向量的码本,这在实践中并不可行。
在 SoundStream 中,我们提出一个新的残差向量量化器 (RVQ) 来解决这个问题,该量化器由多层组成(在我们的实验中多达 80 层)。第一层以中等分辨率对代码向量进行量化,接下来的每一层都对前一层的残差错误进行处理。通过将量化过程分为几层,可以让码本的大小缩减很多。举例来说,在比特率为 3 kbps、每秒产生 100 个向量的情况下,如果使用 5 个量化器层,码本大小会从 10 亿变成 320。此外,通过增加或删除量化器层,我们可以轻松地分别提高或降低比特率。
由于网络条件在传输音频时可能会发生变化,理想情况下,编解码器应是“可扩容的”,这样它就可以根据网络状态提高其比特率。虽然大多数传统的编解码器都是可扩容的,但以前的可学习编解码器需要针对每个比特率专门进行训练和部署。
为了规避这一限制,我们利用 SoundStream 中量化层的数量来控制比特率,并提出了一种称为“量化器丢弃”的新方法。在训练期间,我们随机丢弃一些量化层来模拟不同的比特率。这能够让解码器在任何比特率的输入音频流中展现出良好的性能,从而帮助 SoundStream 形成“可扩容性”。如此一来,单一的训练模型可以在任何比特率下运行,并且与针对这些比特率专门训练的模型具有同样好的性能。
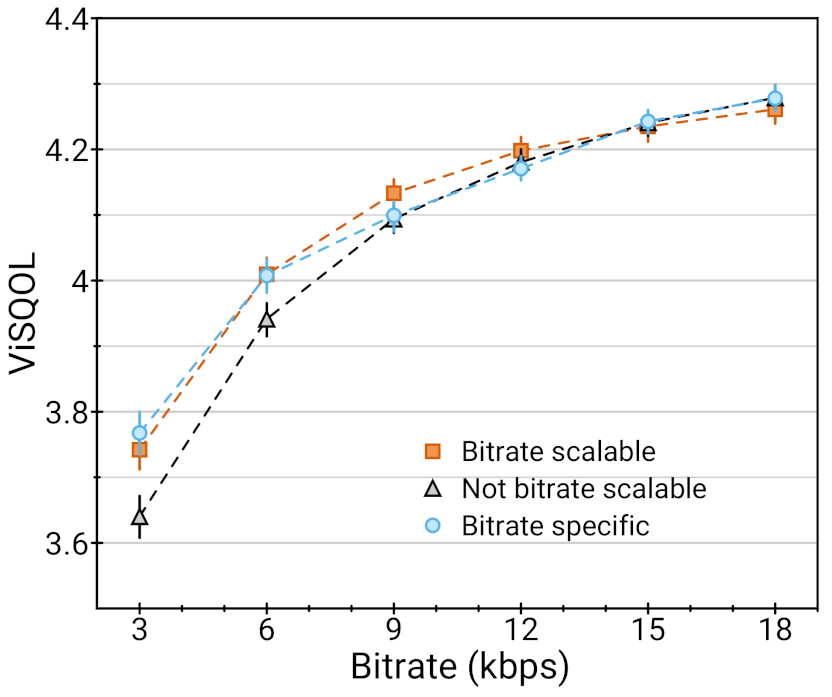
SoundStream 模型之间的比较(越高越好):在 18 kbps 下对这些模型进行训练,分为采用量化器丢弃(比特率可扩容)、不借助量化器丢弃(比特率不可扩容)并用可变数量的量化器评估,或在固定比特率下训练和评估(特定比特率)。与特定比特率的模型(每个比特率都有不同的模型)相比,由于采用量化器丢弃,可扩容比特率模型(针对所有比特率使用单一模型)并没有损失任何质量
3 kbps 下的 SoundStream 优于 12 kbps 下的 Opus,且在 9.6 kbps 下与 EVS 的质量接近,而且使用的比特少了 3.2 倍至 4 倍。这意味着用 SoundStream 编码的音频可以提供相似的质量,而使用的带宽却大大降低。此外,在相同的比特率下,SoundStream 的性能优于当前版本的 Lyra(基于自回归网络)。Lyra 已针对生产使用进行部署和优化,与之不同的是,SoundStream 仍然处于实验阶段。在未来,Lyra 将整合 SoundStream 的组件,以提供更高的音频质量并降低复杂性。
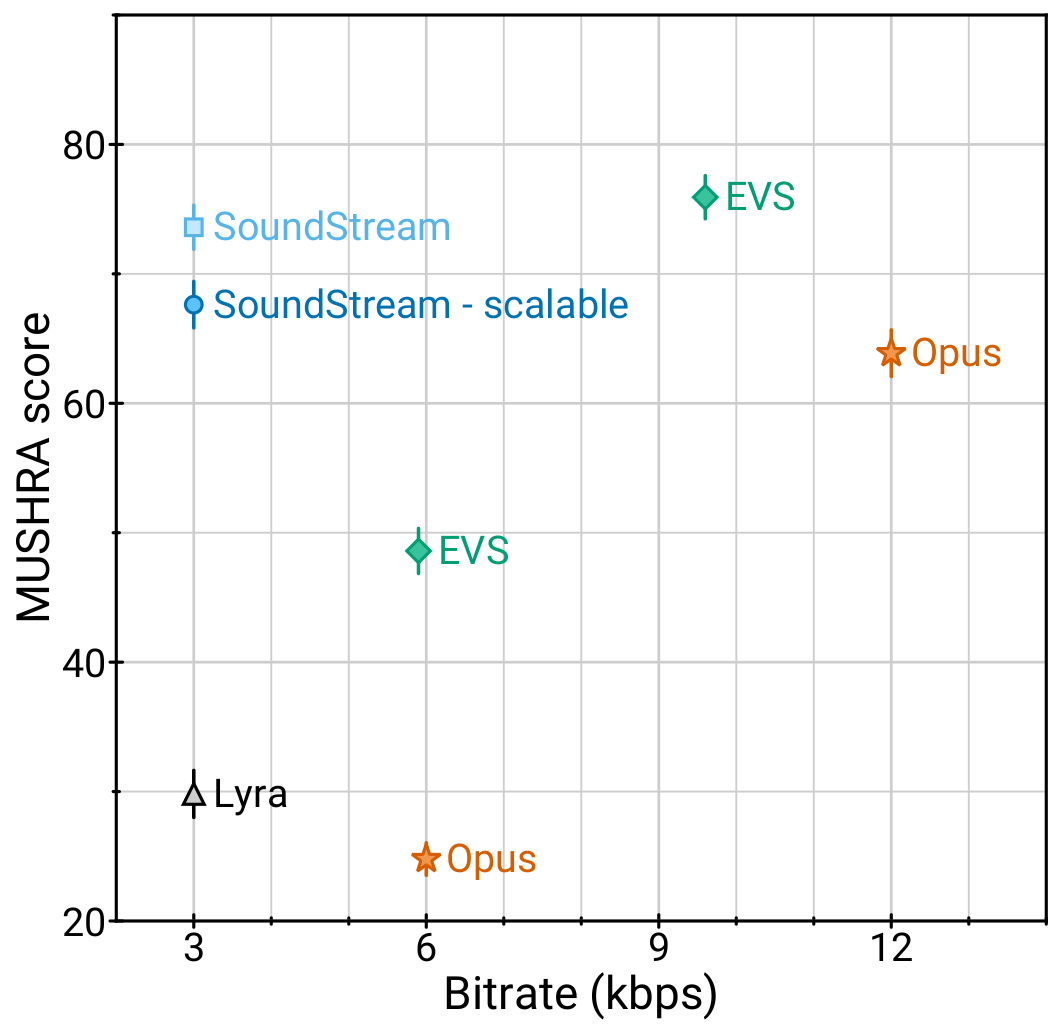
比较 3kbps 下的 SoundStream 与最先进的编解码器。MUSHRA 分数是主观质量的一个指标(越高越好)
SoundStream 与 Opus、EVS 和原始的 Lyra 编解码器相比,性能的优越性在这些音频实例中得到了体现,以下是其中的一部分。
音频实例
https://google-research.github.io/seanet/soundstream/examples
在传统的音频处理流水线中,压缩和增强(去除背景噪音)通常由不同的模块执行。例如,可以在音频压缩之前,在发射器端应用音频增强算法,或者在音频解码之后,在接收器端应用此算法。在这样的设置中,每个处理步骤都会造成端到端的延迟。与之相反,我们采用独特的方式设计 SoundStream,使得压缩和增强可以由同一个模型联合执行,而不增加整体延迟。在下面的例子中,我们证明,通过动态地启用和停用去噪(5 秒不去噪,5 秒去噪,5 秒不去噪,以此类推),可以将压缩和背景噪音抑制结合起来。
原始的有噪音音频
https://www.gstatic.com/soundstream_examples/ai_blog/soundstream_controllable_enhancement_noisy.wav
去噪输出*
https://www.gstatic.com/soundstream_examples/ai_blog/soundstream_controllable_enhancement_denoised.wav
*通过间隔 5 秒启用和停用去噪功能来演示
在需要传输音频时,无论是在线播放视频,还是在电话会议期间,都需要高效的压缩。对于改善机器学习驱动的音频编解码器来说,SoundStream 是非常重要的一步。它的性能优于最先进的编解码器(如 Opus 和 EVS),可以按需增强音频,并且只需部署一个可扩容的模型,而不需要部署很多。
SoundStream 将作为下一次改进版 Lyra 的一部分发布。通过集成 SoundStream 和 Lyra,开发者可以利用现有的 Lyra API 和工具进行开发工作,既获享灵活性,也拥有更好的音质。我们也会将其作为一个单独的 TensorFlow 模型发布,供实验使用。
TimeDial 研究是 Lianhui Qi、Luheng He、Yenjin Choi、Manaal Faruqui 和本文作者共同努力的结果。Disfl-QA 研究是 Jiacheng Xu、Diyi Yang 和 Manaal Faruqui 的合作成果。

推荐阅读



点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看



